Molecular Dynamics Simulations for Materials Mechanical Properties: From Atomic Forces to Predictive Design
This article provides a comprehensive overview of Molecular Dynamics (MD) simulations as a pivotal tool for predicting and understanding the mechanical properties of materials.
Molecular Dynamics Simulations for Materials Mechanical Properties: From Atomic Forces to Predictive Design
Abstract
This article provides a comprehensive overview of Molecular Dynamics (MD) simulations as a pivotal tool for predicting and understanding the mechanical properties of materials. It covers foundational principles, from solving Newton's equations of motion to the application of modern machine-learned potentials, addressing a core challenge in materials science and biophysics. For researchers and drug development professionals, we detail methodologies for simulating diverse systems—including complex metal alloys, polymers, and biomolecules—and explore critical applications in drug discovery, such as ligand pose prediction and binding-free energy calculations. The article further tackles troubleshooting computational constraints and optimizing sampling efficiency, while also discussing validation frameworks that integrate experimental data and comparative analyses with emerging AI techniques. This resource aims to bridge the gap between computational modeling and practical material design, offering insights for accelerating innovation in biomedicine and advanced materials.
The Atomic Foundation: How MD Simulations Decode Mechanical Behavior
In molecular dynamics (MD) simulations, solving Newton's equations of motion for particle systems provides the fundamental framework for predicting the temporal evolution of molecular structures. These principles enable researchers to investigate complex materials phenomena, from protein-ligand interactions in drug discovery to the mechanical behavior of high-energy materials [1] [2]. Newton's second law, expressed as F = ma, serves as the cornerstone for these simulations, where the force F acting on a particle equals its mass ( m ) multiplied by its acceleration a [3]. This relationship translates to a second-order differential equation that can be numerically integrated to track particle trajectories over time, enabling the atomic-scale observation of processes relevant to materials mechanical properties research.
Core Principles and Numerical Implementation
Newton's Equations of Motion Formulation
For a system of ( N ) particles, Newton's equations of motion can be written as:
[ mi \frac{d^2\mathbf{r}i}{dt^2} = \mathbf{F}_i, \quad i = 1, \ldots, N ]
where ( mi ) is the mass of particle ( i ), ( \mathbf{r}i ) is its position vector, and ( \mathbf{F}i ) represents the total force acting on it [4]. This force is derived from the negative gradient of the system's potential energy function ( U(\mathbf{r}1, \mathbf{r}2, \ldots, \mathbf{r}N) ):
[ \mathbf{F}i = -\nablai U ]
In molecular dynamics simulations, these equations are solved numerically to generate trajectories of all particles in the system [3]. The configuration space explored by these trajectories provides the statistical mechanical foundation for calculating thermodynamic, dynamic, and mechanical properties of the material system under investigation.
Numerical Integration Algorithms
Numerical integration methods approximate the continuous motion of particles by discretizing time into small steps ( \Delta t ), typically on the femtosecond scale ((10^{-15}) seconds) for atomistic simulations [3]. Several algorithms have been developed to balance computational efficiency with numerical stability and energy conservation.
Table 1: Comparison of Numerical Integration Methods for Molecular Dynamics
| Algorithm | Formulation | Advantages | Limitations | Typical Timestep (fs) |
|---|---|---|---|---|
| Verlet | ( \mathbf{r}(t + \Delta t) = 2\mathbf{r}(t) - \mathbf{r}(t - \Delta t) + \mathbf{a}(t)\Delta t^2 ) | Time-reversible, good energy conservation | No explicit velocity calculation | 1-2 |
| Velocity Verlet | ( \mathbf{r}(t + \Delta t) = \mathbf{r}(t) + \mathbf{v}(t)\Delta t + \frac{1}{2}\mathbf{a}(t)\Delta t^2 ) ( \mathbf{v}(t + \Delta t) = \mathbf{v}(t) + \frac{1}{2}[\mathbf{a}(t) + \mathbf{a}(t + \Delta t)]\Delta t ) | Positions and velocities simultaneously available | Requires two force evaluations per step | 1-2 |
| Leap-Frog | ( \mathbf{v}(t + \frac{1}{2}\Delta t) = \mathbf{v}(t - \frac{1}{2}\Delta t) + \mathbf{a}(t)\Delta t ) ( \mathbf{r}(t + \Delta t) = \mathbf{r}(t) + \mathbf{v}(t + \frac{1}{2}\Delta t)\Delta t ) | Computational efficiency, moderate memory usage | Velocities not synchronized with positions | 1-2 |
The Velocity Verlet algorithm has become particularly popular in modern MD implementations due to its numerical stability and convenience in providing simultaneous access to positions and velocities [5]. This algorithm is explicit in nature and preserves the time-reversibility of Newton's equations, making it suitable for long-timescale simulations.
Force Calculation and Potential Functions
The accuracy of MD simulations critically depends on the calculation of forces between particles. These forces are derived from potential energy functions (force fields) that describe the energetic interactions within the system.
Force Field Components
For a system with generic pairwise interactions, the total potential energy can be expressed as:
[ U = \sum{i=1}^{N-1} \sum{j>i}^{N} u(r_{ij}) ]
where ( r{ij} = |\mathbf{r}i - \mathbf{r}j| ) is the distance between particles ( i ) and ( j ), and ( u(r{ij}) ) is the pairwise potential [5]. The force on particle ( i ) due to particle ( j ) is then given by:
[ \mathbf{F}{i} = -\frac{du(r{ij})}{dr{ij}} \frac{\mathbf{r}{ij}}{r_{ij}} ]
with ( \mathbf{F}{j} = -\mathbf{F}{i} ) satisfying Newton's third law [5].
Lennard-Jones Potential for Non-Bonded Interactions
The Lennard-Jones potential is commonly used to model van der Waals interactions and steric repulsion between neutral atoms or molecules:
[ U_{LJ}(r) = 4\epsilon \left[ \left( \frac{\sigma}{r} \right)^{12} - \left( \frac{\sigma}{r} \right)^{6} \right] ]
where ( \epsilon ) is the depth of the potential well, ( \sigma ) is the finite distance at which the interparticle potential is zero, and ( r ) is the distance between particles [6]. The ( r^{-12} ) term describes Pauli repulsion at short distances due to overlapping electron orbitals, while the ( r^{-6} ) term represents attractive London dispersion forces [6].
The corresponding force expression for the Lennard-Jones potential is:
[ F{LJ}(r) = -\frac{dU{LJ}}{dr} = 24\epsilon \left[ 2 \frac{\sigma^{12}}{r^{13}} - \frac{\sigma^{6}}{r^{7}} \right] ]
This force calculation is computationally intensive and typically represents the bottleneck in MD simulations, particularly for large systems where the number of pairwise interactions grows quadratically with system size.
Experimental Protocols
Basic MD Simulation Workflow
The following protocol outlines the standard procedure for conducting an MD simulation of a particle system using Newton's equations of motion.
Table 2: Research Reagent Solutions for MD Simulations
| Component | Function | Examples/Parameters |
|---|---|---|
| Force Field | Defines potential energy functions and parameters for interactions | AMBER, CHARMM, GROMACS, OPLS; Lennard-Jones parameters (( \epsilon ), ( \sigma )) [3] |
| Integration Algorithm | Numerical solver for equations of motion | Velocity Verlet, Leap-Frog; Timestep (0.5-2 fs) [3] [5] |
| Periodic Boundary Conditions | Mimics bulk system while minimizing finite-size effects | Cubic, orthorhombic, or triclinic unit cells [3] |
| Thermostat | Maintains constant temperature | Nosé-Hoover, Berendsen, Langevin (coupling constant: 0.1-1.0 ps) |
| Barostat | Maintains constant pressure | Parrinello-Rahman, Berendsen (coupling constant: 1.0-5.0 ps) |
| Software Package | Implements MD algorithms and analysis tools | GROMACS, AMBER, NAMD, LAMMPS [3] |
Protocol 1: Standard MD Simulation Using Velocity Verlet Integration
System Setup
- Define initial particle coordinates (from experimental structures or modeling)
- Specify simulation box dimensions and boundary conditions
- Assign initial particle velocities from Maxwell-Boltzmann distribution at target temperature
- Select appropriate force field parameters for the system
Energy Minimization
- Perform steepest descent or conjugate gradient minimization to remove steric clashes
- Continue until maximum force falls below specified tolerance (typically 10-100 kJ/mol/nm)
Equilibration Phase
- Run simulation with temperature coupling (NVT ensemble) for 50-500 ps
- Continue with pressure and temperature coupling (NPT ensemble) for 50-500 ps
- Monitor potential energy, temperature, and density for stability
Production Phase
- Execute extended simulation without temperature or pressure coupling (NVE ensemble) or with weak coupling
- Save trajectory frames at regular intervals (typically 1-10 ps)
- Continue for timescale appropriate to phenomenon of interest (ns to µs)
Analysis
- Calculate thermodynamic properties (temperature, pressure, energy)
- Compute transport properties (diffusion coefficients, viscosity)
- Analyze structural properties (radial distribution functions, order parameters)
- Investigate dynamic properties (correlation functions, mean-square displacement)
Advanced Sampling Techniques
For processes involving rare events or high energy barriers, enhanced sampling methods may be employed:
Protocol 2: Umbrella Sampling for Free Energy Calculations
Define Reaction Coordinate
- Identify a collective variable (CV) that describes the transition of interest
- Common choices: distance, angle, dihedral, or combination of coordinates
Set Up Umbrella Windows
- Divide the CV range into multiple overlapping windows (typically 20-50)
- Apply harmonic biasing potentials in each window to restrain the CV: [ Ui(\xi) = \frac{1}{2}ki(\xi - \xii^0)^2 ] where ( \xi ) is the CV, ( ki ) is the force constant, and ( \xi_i^0 ) is the center of window ( i )
Run Simulations
- Perform independent MD simulations in each window
- Ensure sufficient sampling within each window (typically 10-100 ns per window)
- Confirm overlap of probability distributions between adjacent windows
Analyze Results
- Use Weighted Histogram Analysis Method (WHAM) to combine data from all windows
- Unbiased free energy profile along the CV: [ G(\xi) = -k_B T \ln P(\xi) ] where ( P(\xi) ) is the probability distribution along ( \xi )
Applications in Materials Mechanical Properties Research
The solution of Newton's equations in MD enables the investigation of various mechanical phenomena in materials at the atomic scale. Recent advances include the development of neural network potentials (NNPs) like EMFF-2025, which achieves density functional theory (DFT)-level accuracy in predicting structures, mechanical properties, and decomposition characteristics of high-energy materials (HEMs) containing C, H, N, and O elements [2]. These machine learning approaches maintain physical consistency and predictive accuracy across structurally complex systems while being more efficient than traditional force fields and DFT calculations [2].
In pharmaceutical applications, MD simulations help elucidate protein-ligand interactions, membrane protein dynamics, and drug formulation stability [3]. The atomic-scale insights provided by these simulations guide rational drug design and optimization, significantly reducing the need for physical experiments in early-stage discovery [1].
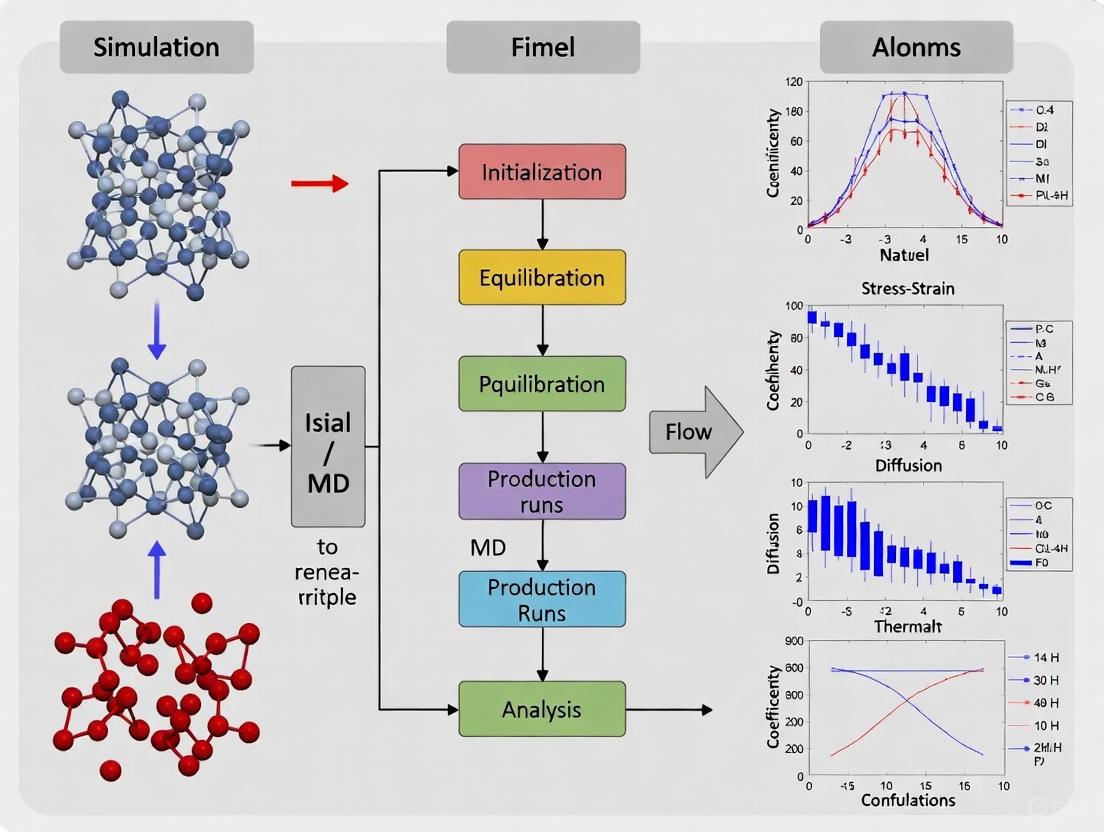
Workflow Visualization
MD Simulation Workflow: This diagram illustrates the fundamental iterative process of molecular dynamics simulations, showing the cycle of force calculation and integration of Newton's equations of motion.
Force Calculation Process: This diagram details the components of force calculation in MD simulations, highlighting how different interaction types contribute to the total force on each particle.
In molecular dynamics (MD) simulations, the interatomic potential, or force field, is the fundamental component that dictates the accuracy and reliability of the computed materials properties. The fidelity of large-scale MD simulations critically hinges on the accuracy of these underlying potentials [7]. This article traces the evolution from classical analytical potentials, like Lennard-Jones, to modern data-driven machine learning potentials, with a focused examination of Neuroevolution Potentials (NEP). Framed within materials mechanical properties research, we provide application notes and detailed protocols for researchers embarking on simulations of metallic systems, alloys, and other advanced materials.
Evolution and Comparison of Interatomic Potentials
Classical and Machine-Learning Potentials
The landscape of interatomic potentials spans from computationally efficient but sometimes inaccurate classical forms to highly accurate but computationally expensive ab initio methods. Machine-learned potentials (MLPs) have emerged as a paradigm that offers near-first-principles accuracy with significantly lower computational cost, bridging the gap between these extremes [7].
Classical Potentials include well-established forms such as the Lennard-Jones (LJ) potential, defined as:
$$ \Large V_{LJ} \left( r \right) = 4 \epsilon \left[ \left(\dfrac{\sigma}{r}\right)^{12} -\left(\dfrac{\sigma}{r}\right)^{6} \right] $$
where ε is the depth of the potential well and σ is the finite distance at which the inter-particle potential is zero [8]. LJ potentials are valued for their computational efficiency, enabling simulations of millions of atoms. For specific metals, they can reproduce lattice constants and surface energies with less than 0.1% and 5% deviation from experiment, respectively [9]. However, their simple two-body nature often fails to capture complex many-body interactions in metallic and covalent systems.
Embedded Atom Method (EAM) potentials introduce a many-body term by considering the local electron density, providing better descriptions for metallic systems but often with reduced accuracy for surface properties and limited transferability to alloys [9].
Machine-Learned Potentials (MLPs) utilize flexible functional forms parameterized via machine learning on quantum-mechanical data. The Neuroevolution Potential (NEP) represents a state-of-the-art approach in this category, combining high accuracy with remarkable computational efficiency [7].
Quantitative Comparison of Potential Types
Table 1: Comparative Analysis of Interatomic Potential Types for Materials Simulation
| Potential Type | Representative Examples | Accuracy Relative to DFT/Experiment | Computational Efficiency | Key Strengths | Primary Limitations |
|---|---|---|---|---|---|
| Classical Pair Potentials | Lennard-Jones (LJ) [8] | Lattice constants: <0.1% dev.Surface energies: <5% dev. [9] | Very High (~10⁸x faster than DFT) [9] | Computational efficiency; Simplicity; Compatibility with organic force fields [9] | Limited to two-body interactions; Poor transferability for complex bonding [10] |
| Semi-Empirical Many-Body Potentials | Embedded Atom Method (EAM) [7] | Lattice/elastic properties: 0.1-5% dev.Surface energies: up to 50% dev. [9] | High (~10⁵x faster than DFT) [9] | Good for bulk metallic properties; Lower cost than MLPs [7] | Limited accuracy for surfaces/interfaces; Difficult to parameterize for multi-component systems [9] |
| Machine Learning Potentials (MLPs) | Neuroevolution Potential (NEP) [11] [12] | Energy: ~2 meV/atomForces: ~50 meV/Å [11] | Medium-High (Order of magnitude faster than other MLPs) [12] [7] | Near-DFT accuracy; High efficiency; Applicable to diverse elements & systems [12] [7] | Dependent on quality/training data; Risk of overfitting [10] |
| Ab Initio Methods | Density Functional Theory (DFT) | Reference Standard | Very Low | Fundamental, parameter-free; High accuracy for electronic properties | Computationally prohibitive for large systems/long times [11] |
The Neuroevolution Potential (NEP) Framework
Fundamental Architecture
The Neuroevolution Potential represents a significant advancement in MLP architecture, designed for both high accuracy and computational efficiency. In the NEP framework, the total potential energy of a system is decomposed into atomic contributions, where the site energy Ui of a central atom i is calculated using a neural network [7]:
$$ Ui = \sum{\mu=1}^{N{\text{neu}}} w{\mu}^{(1)} \tanh\left( \sum{\nu=1}^{N{\text{des}}} w{\mu\nu}^{(0)} q{\nu i} - b_{\mu}^{(0)} \right) - b^{(1)} $$
Here, q_νi represents the descriptor vector components for atom i, w^(0) and w^(1) are weight matrices, b^(0) and b^(1) are bias vectors, and tanh is the activation function [7]. The descriptor vector is constructed from a series of radial and angular components that encode the atomic environment within a specified cutoff radius, ensuring invariance to translation, rotation, and permutation of like atoms [7].
A key innovation in NEP is the species-dependent parameterization. Each element type has its own set of neural network parameters w^I, and the radial expansion coefficients c_nk^IJ depend on both the central atom type I and neighbor atom type J. This architecture allows NEP to maintain a constant regression capacity per atom type while scaling to systems with numerous elements [7].
Universal Potentials and Specialized Implementations
The NEP framework has been successfully scaled to create universal potentials such as NEP89, which encompasses 89 elements across inorganic and organic materials [12]. This "foundation model" achieves a computational efficiency 3-4 orders of magnitude greater than comparable universal models while maintaining competitive accuracy [12].
For more focused applications, specialized NEP models have been developed, including:
- UNEP-v1: A general-purpose potential for 16 elemental metals and their alloys [7]
- Al-Cu-Li NEP: A ternary potential for lightweight aerospace alloys with training errors of 2.1 meV/atom for energy and 47.4 meV/Å for force [11]
- CuZrAl NEP: A potential for metallic glasses developed using an efficient LJ-surrogate sampling approach [10]
Application Notes and Protocols
Protocol 1: Developing a Custom NEP for Material Systems
Table 2: Research Reagent Solutions for NEP Development
| Tool/Category | Specific Examples | Function/Purpose | Key Considerations |
|---|---|---|---|
| Reference Data Generation | VASP, Quantum ESPRESSO, CP2K | Generate accurate training data via DFT calculations | Balance between accuracy (DFT method) and computational cost; Include diverse atomic environments [11] |
| Training & Optimization | GPUMD [7], LAMMPS [11] | Train NEP models using evolutionary strategies | Use separable natural evolution strategy for parameter optimization [12]; Monitor training and validation errors to prevent overfitting |
| Validation & Analysis | OVITO [11], VMD, in-house scripts | Visualize and validate simulation results against DFT and experimental data | Check structural, dynamic, energetic, and mechanical properties [10] |
| Public Databases | Materials Project [11], OMAT24 [12], SPICE [12] | Source initial structures and reference data | Ensure consistency of reference data (e.g., dispersion corrections) across sources [12] |
Workflow Overview:
Figure 1: NEP Development and Application Workflow
Step-by-Step Procedure:
Structural Sampling and Data Set Construction
- Objective: Assemble a diverse set of atomic configurations that comprehensively represent the chemical and structural space of interest.
- Methods:
- Perform ab initio molecular dynamics (AIMD) simulations at varying temperatures (e.g., 50 K to 2000 K) and pressures [11].
- Sample crystalline structures from databases like the Materials Project, ensuring coverage of relevant phases (FCC, BCC, HCP) [11].
- For disordered systems like metallic glasses, use enhanced sampling techniques like swap-Monte Carlo with a Lennard-Jones surrogate model to access deeply supercooled states [10].
- Apply descriptor-space subsampling to select the most diverse structures for training [12].
Reference Data Generation via Density Functional Theory
- Objective: Generate accurate energy, force, and virial stress labels for the sampled structures.
- Protocol:
- Perform static DFT calculations with consistent settings (e.g., KSPACING=0.2, ENCUT=600 eV, EDIFF=1×10⁻⁶ eV) [11].
- Ensure consistent treatment of dispersion interactions (e.g., D3 corrections) across all structures if combining data from multiple sources [12].
- Compile results into a structured data set containing energies, forces, and virials for each configuration.
NEP Model Training
- Objective: Optimize NEP parameters to reproduce DFT reference data.
- Protocol:
- Initialize model with appropriate cutoff radii and basis function parameters.
- Train using evolutionary algorithms implemented in GPUMD or similar packages.
- Monitor root-mean-square errors (RMSE) for energy, forces, and virials to assess convergence.
- For multi-element systems, leverage iterative training strategies to handle inconsistent energy references between different data sets [12].
Model Validation
- Objective: Assess trained model's accuracy and transferability to unseen configurations.
- Protocol:
- Calculate properties not directly included in training (e.g., elastic constants, phonon spectra, surface energies).
- Compare molecular dynamics results against experimental data where available (e.g., cluster formation energies, phase stability) [11].
- Perform iterative refinement by identifying configurations with high prediction errors and adding them to the training set [12].
Protocol 2: Applying NEP for Mechanical Properties Assessment
Workflow Overview:
Figure 2: Mechanical Properties Simulation Workflow
Step-by-Step Procedure:
System Construction
- Build simulation cells with appropriate dimensions for the target property (e.g., ≥10×10×10 nm for fracture simulations).
- For alloys, use random solid solutions or predetermined ordered structures based on the system of interest.
Equilibration Protocol
- Employ a stepped equilibration in the NPT ensemble (constant Number of particles, Pressure, and Temperature) to relax density.
- Use Langevin thermostat or Nosé-Hoover chain for temperature control.
- Equilibrate for sufficient time to ensure structural relaxation (typically 100 ps - 1 ns).
Mechanical Deformation Simulations
- Elastic Constants: Calculate from stress-strain relationships using small deformations (≤1%) or via fluctuation methods in equilibrium MD.
- Plastic Deformation: Apply uniaxial or shear strain at constant strain rate (typically 10⁷ - 10⁹ s⁻¹).
- Fracture Toughness: Introduce pre-cracks and monitor propagation under mode-I loading.
Analysis Methods
- Compute stress tensors using the virial theorem as implemented in the simulation package.
- Identify defect structures using common neighbor analysis or centrosymmetry parameter.
- Calculate radial distribution functions and Voronoi polyhedra for structural analysis.
Case Studies and Validation
Case Study: Al-Cu-Li Aerospace Alloys
Researchers developed a NEP for Al-Cu-Li alloys to predict microstructural evolution during aging treatments [11]. The potential was trained on a dataset of 1,637 structures containing approximately 180,000 atoms, achieving remarkable accuracy with training errors of 2.1 meV/atom for energy and 47.4 meV/Å for forces [11]. The validated NEP successfully simulated the formation of T1 phase precipitates and their high-temperature stability, with results consistent with experimental transmission electron microscopy observations [11]. This application demonstrates NEP's capability to capture complex precipitation phenomena critical for strength and fracture toughness in aerospace alloys.
Case Study: Metallic Glasses
For CuZrAl metallic glasses, researchers implemented an efficient training approach combining Lennard-Jones surrogate models, swap-Monte Carlo sampling, and single-point DFT corrections [10]. This methodology generated amorphous structures spanning 14 decades of supercooling, far beyond conventional MD timescales [10]. The resulting NEP accurately reproduced structural, dynamical, energetic, and mechanical properties, matching both experimental data and classical EAM predictions while maintaining the accuracy of DFT [10]. This approach provides a scalable path for developing accurate MLPs for complex disordered systems, including multi-component and high-entropy alloys.
The evolution from Lennard-Jones to Neuroevolution Potentials represents a paradigm shift in atomistic simulations of materials mechanical properties. While classical potentials remain valuable for specific applications where computational efficiency is paramount, NEP and other machine-learned potentials offer unprecedented accuracy and transferability across diverse chemical spaces. The protocols outlined herein provide researchers with practical guidance for implementing these advanced methods in their investigations of mechanical behavior in metals, alloys, and complex materials systems. As NEP methodologies continue to mature and computational resources expand, these approaches will enable increasingly predictive simulations of materials performance across multiple length and time scales.
Molecular dynamics (MD) simulation has become an indispensable tool in the research and development of materials, chemistry, and drug discovery, functioning as a "microscope with exceptional resolution" for observing atomic-scale dynamics that are difficult or impossible to access experimentally [13]. By tracking the movement of individual atoms and molecules over time, MD provides unique insights into the fundamental processes of the physical world, enabling researchers to visualize atomic-scale dynamics and gain deeper understanding of complex physical and chemical phenomena [13]. This protocol outlines the complete computational workflow for MD simulations focused on investigating mechanical properties of materials, providing researchers with a structured framework from system initialization through trajectory analysis.
The accuracy and efficiency of MD simulations depend critically on appropriate parameter selection, force field choices, and analysis methodologies. Recent advancements in machine learning interatomic potentials (MLIPs), trained on large datasets derived from high-accuracy quantum chemistry calculations, have dramatically improved both the precision and computational efficiency of MD simulations, opening the door to studying complex material systems previously considered computationally prohibitive [13]. Additionally, emerging automation tools like MDCrow demonstrate how large language model (LLM) agents can now autonomously complete complex MD workflows using expert-designed tools for handling files, setting up simulations, and analyzing outputs [14].
Initialization and System Preparation
Initial Structure Acquisition and Preparation
Every MD simulation begins with preparing the initial structure of the target atoms or molecules. For materials systems, crystal structures are often retrieved from open-access repositories such as the Materials Project or AFLOW, while for biomolecular systems, experimental structures from the Protein Data Bank (PDB) are commonly used [13]. However, database structures frequently require correction of issues such as missing atoms or incomplete regions using modeling tools. For novel materials or molecular systems not yet reported, initial structures must be built from scratch based on experimental data or theoretical predictions [13].
The accuracy of the initial model directly impacts simulation reliability. While generative AI technologies like AlphaFold2 have enabled non-experts to predict molecular and material structures more easily, expert assessment remains crucial to verify whether generated conformations are physically and chemically plausible and align with known structural motifs [13]. For mechanical properties investigations, particular attention should be paid to crystallographic orientation, defect inclusion, and surface preparation when creating the initial configuration.
Force Field Selection
The choice of interatomic potential is a critical factor determining MD simulation accuracy and applicability [13]. Force fields define the potential energy surface governing atomic interactions and must be carefully selected based on the material system and properties of interest. For polymer systems, the Interface Force Field (IFF) has been shown to accurately predict physical, mechanical, and thermal properties [15]. Reactive force fields like ReaxFF enable simulation of bond formation and breaking during chemical reactions [16], while machine learning interatomic potentials (MLIPs) offer high accuracy across diverse chemical spaces [13] [16].
Table 1: Common Force Field Types for Materials Simulation
| Force Field Type | Typical Applications | Key Characteristics | Examples |
|---|---|---|---|
| Classical Empirical | Metals, ceramics, polymers | Fast computation, transferable parameters | Lennard-Jones, Embedded Atom Method (EAM) |
| Reactive | Chemical reactions, catalysis | Describes bond formation/breaking | ReaxFF, COMB |
| Machine Learning | Complex systems, quantum accuracy | High accuracy, data-driven | Moment Tensor Potentials (MTP), Neural Network Potentials |
| Coarse-Grained | Large systems, long timescales | Reduced degrees of freedom | MARTINI, SDK |
System Size Optimization
System size selection balances computational efficiency with predictive precision. For epoxy resin systems, research indicates that approximately 15,000 atoms provides optimal efficiency without sacrificing precision in predicting mass density, elastic properties, strength, and thermal properties [15]. Studies on sodium borosilicate glasses show property convergence at systems with 1,600 atoms [15], while other epoxy systems require up to 40,000 atoms for convergence of elastic modulus, glass-transition temperature (Tg), and yield strength [15]. Statistical sampling typically requires multiple independent MD replicates (typically 3-5) with different initial velocity distributions to generate meaningful statistical averages [15].
Initialization Parameters
System initialization requires careful parameter selection to ensure physical accuracy and numerical stability:
- Initial velocities: Typically sampled from a Maxwell-Boltzmann distribution corresponding to the desired simulation temperature [13]
- Time step: Typically 0.5-1.0 femtoseconds (1 fs = 10⁻¹⁵ s) to accurately capture the fastest atomic motions while maintaining energy conservation [13]
- Periodic boundary conditions: Applied to minimize surface effects and simulate bulk behavior [17]
- Initial minimization: Performed using methods like conjugate gradient to remove high-energy atomic clashes [15]
Simulation Workflow
The core MD simulation workflow involves integrating Newton's equations of motion using numerical methods. The velocity Verlet algorithm is commonly employed due to its favorable energy conservation and stability properties, satisfying the symplectic condition that ensures conservation of a shadow Hamiltonian [17] [13]. The following diagram illustrates the complete MD simulation workflow:
Energy Minimization
Before dynamics begin, the system undergoes energy minimization to remove atomic clashes and unfavorable contacts. The conjugate-gradient method is typically employed with energy tolerance of 10⁻⁴, force tolerance of 10⁻⁶ kcal/mol-Å, and maximum iterations of 100-1000 [15]. This step ensures the system begins at a local energy minimum before temperature introduction.
System Equilibration
Equilibration prepares the system at the desired thermodynamic state before production simulation. For polymer systems like DGEBF/DETDA epoxy, this involves [15]:
- Densification: Gradually reducing simulation box volume to target density (e.g., 1.20 g/cm³ for epoxy) using the "fix/deform" command in LAMMPS over 10 ns in multiple stages
- Annealing: Heating from 27°C to 227°C and cooling back to 27°C at 20°C/ns to relax residual stresses
- Cross-linking: For polymer systems, simulating chemical bonding using protocols like REACTER in LAMMPS at elevated temperatures (e.g., 527°C) with bond formation cutoff distances of 7 Å and appropriate reaction probabilities [15]
Production Simulation
Production MD generates the trajectory data used for analysis. Key parameters include:
- Ensemble selection: NVE (microcanonical), NVT (canonical), or NPT (isothermal-isobaric) based on properties of interest
- Thermostat/Barostat: Nose-Hoover thermostat and barostat commonly used for temperature and pressure control [15]
- Simulation duration: Must be sufficient to observe the phenomena of interest; typically nanoseconds for mechanical properties
- Integration algorithm: Velocity Verlet with time steps of 0.5-2.0 fs [17] [13]
Trajectory Analysis Methods
MD simulations generate time-series data of atomic coordinates, velocities, and energies (trajectories) that require specialized analysis to extract meaningful physical insights [13]. The massive datasets produced by MD simulations necessitate efficient analysis tools and methods.
Structural Analysis
- Radial Distribution Function (RDF): Quantifies how atoms are spatially distributed around reference atoms as a function of radial distance. RDF analysis reveals characteristic interatomic distances, coordination numbers, and phase state identification through peak analysis [13]
- Mean Square Displacement (MSD): Calculates the average squared displacement of particles over time, providing diffusion coefficients through Einstein's relation: ( D = \frac{1}{6N} \lim{t \to \infty} \frac{d}{dt} \sum{i=1}^{N} \langle |ri(t) - ri(0)|^2 \rangle ) where D is the diffusion coefficient, N is the number of particles, and r_i(t) is the position of particle i at time t [13]
Mechanical Properties Analysis
Multiple approaches exist for determining mechanical properties from MD simulations:
- Equilibrium Molecular Dynamics (EMD): Utilizes fluctuation-dissipation theorems to extract properties from thermal fluctuations
- Non-Equilibrium Molecular Dynamics (NEMD): Applies external perturbations to measure response
- Bending and oscillation tests: Specialized NEMD approaches for low-dimensional materials [18]
Table 2: Mechanical Properties Calculation Methods
| Property | Method | Key Formula/Approach | Application Example |
|---|---|---|---|
| Young's Modulus | Tensile deformation | Stress-strain curve slope in elastic region | Plumbene: 28.18 GPa (bending), 32.17 GPa (oscillation) [18] |
| Bulk Modulus | Volume fluctuation | ( B = -V \frac{\partial P}{\partial V} ) | Plumbene: 8.62 GPa [18] |
| Poisson's Ratio | Lateral strain measurement | ( \nu = -\frac{\varepsilon{lateral}}{\varepsilon{axial}} ) | Plumbene: 0.23 [18] |
| Yield Strength | Tensile deformation | Maximum stress before plastic flow | Epoxy resins: Strain-dependent [15] |
Advanced Analysis Techniques
- Principal Component Analysis (PCA): Identifies orthogonal basis vectors capturing the largest variance in atomic displacements, revealing dominant modes of structural change [13]
- Machine Learning Analysis: Algorithms like logistic regression, random forest, and multilayer perceptron can identify important structural features and residues from trajectory data [19]
- Cluster Analysis: Combined with PCA to identify and characterize metastable or intermediate states [13]
Experimental Protocols
Protocol 1: Tensile Testing of 2D Materials
This protocol outlines the procedure for determining mechanical properties of 2D materials like plumbene using MD simulations [18]:
System Preparation:
- Create a plumbene sheet of dimensions 700 Å × 200 Å using modeling software
- Define atomic interactions using appropriate potentials (e.g., Tersoff, REBO, or machine learning potentials)
- Energy minimization using conjugate-gradient method
Equilibration:
- Equilibrate system in NPT ensemble at target temperature (e.g., 300K) for 100 ps
- Use Nose-Hoover thermostat and barostat for temperature and pressure control
- Ensure stress components approach zero before proceeding
Deformation:
- Apply uniaxial strain along desired crystal direction at constant strain rate
- Typical strain rates: 0.1-0.4 eV/Å for 2D materials
- Calculate stress using virial theorem: ( \sigma = \frac{1}{V} \sumi mi vi \otimes vi + \frac{1}{2} \sum{i
Analysis:
- Extract stress-strain curve
- Calculate Young's modulus from linear region (0-3% strain)
- Identify yield point as deviation from linearity
- For bending tests, use formula: ( E = \frac{F \delta L^3}{48I'} ) where F is force, δ is deformation, L is length, and I' is second moment of area [18]
Protocol 2: Polymer Mechanical Properties
This protocol describes the determination of thermo-mechanical properties of epoxy resins [15]:
Model Construction:
- Build DGEBF/DETDA monomers in 2:1 molar ratio in periodic simulation boxes
- Create multiple replicates (typically 5) for statistical sampling
- Use system size of approximately 15,000 atoms for optimal efficiency/precision balance
Cross-linking:
- Employ REACTER protocol in LAMMPS with bond formation cutoff distance of 7 Å
- Set reaction probability to 1.0 for each reactive encounter
- Conduct cross-linking at 527°C to enhance reaction rates
- Target cross-linking degree of ~90% for typical epoxy systems
Densification and Annealing:
- Use "fix/deform" command to gradually reduce box volume to target density (1.20 g/cm³ for epoxy)
- Perform annealing from 27°C to 227°C and back to 27°C at 20°C/ns
- Equilibrate at room temperature (27°C) for 1.5 ns
Mechanical Testing:
- Apply uniaxial deformation at strain rate of 0.0001-0.01 ps⁻¹
- Calculate elastic constants from fluctuation formulas in NPT ensemble
- Determine glass transition temperature by monitoring specific volume during cooling
The Scientist's Toolkit
Software and Analysis Tools
Table 3: Essential MD Software and Tools
| Tool Name | Primary Function | Key Features | Application Context |
|---|---|---|---|
| LAMMPS | MD Simulation | Highly versatile, multiple force fields, large system capability | General materials modeling, polymers, metals [15] [16] |
| GROMACS | MD Simulation | Optimized for biomolecules, high performance | Proteins, nucleic acids, lipids [20] |
| VMD | Visualization & Analysis | Advanced rendering, trajectory analysis, extensible | Biomolecular systems, animation [20] |
| MDTraj | Analysis | Fast trajectory analysis, Python-based | General purpose analysis [14] |
| OpenMM | MD Simulation | GPU acceleration, customizability | High-throughput simulations [14] |
| Plumed | Enhanced Sampling | Metadynamics, umbrella sampling, free energy calculations | Rare events, reaction coordinates [17] |
Force Fields for Materials Modeling
Table 4: Specialized Force Fields for Materials
| Force Field | Material Class | Strengths | Limitations |
|---|---|---|---|
| EAM | Metals, alloys | Accurate metallic bonding, defects | Limited to metallic systems |
| Tersoff | Covalent materials | Bond order formalism | Parameterization complexity |
| REAXFF | Reactive systems | Bond formation/breaking | Computational expense |
| IFF | Interfaces, polymers | Accurate interfacial properties | Limited material breadth |
| CHARMM | Biomolecules | Extensive validation | Primarily biological systems |
Workflow Automation and Emerging Trends
Recent advances in workflow automation demonstrate the potential for large language model (LLM) agents to autonomously execute complex MD workflows. Systems like MDCrow utilize chain-of-thought reasoning over 40 expert-designed tools for handling files, setting up simulations, and analyzing outputs [14]. These agents can retrieve PDB files, clean structures, add solvent, perform simulations, and conduct analyses with minimal human intervention, significantly accelerating research cycles [14].
Machine learning interatomic potentials represent another transformative advancement, combining the accuracy of quantum mechanical methods with the computational efficiency of classical force fields [13] [16]. MLIPs trained on high-quality quantum chemistry data enable nanosecond-scale simulations with quantum accuracy, particularly valuable for complex material systems with diverse chemical environments [16].
The integration of MD with multiscale modeling frameworks represents the future of computational materials engineering, where atomic-scale insights inform mesoscale and continuum models to predict macroscopic material behavior [15]. This integrated approach enables computationally driven design of next-generation composite materials with tailored mechanical properties for specific engineering applications [15].
The investigation of material mechanical properties through Molecular Dynamics (MD) simulations faces a fundamental challenge: the vast separation of scales between atomic interactions and macroscopic material behavior. While MD provides unparalleled insight into atomic-scale mechanisms such as dislocation dynamics, fracture initiation, and grain boundary interactions, its computational demands severely restrict accessible length and time scales. Typical MD simulations are limited to domains of approximately 10 nm for time spans under 100 ps, even on advanced parallel computing architectures, and can only simulate artificially high strain rates around 10⁶ s⁻¹, which rarely correspond to experimental conditions [21]. These limitations necessitate innovative computational approaches that transcend single-scale modeling paradigms.
Multiscale modeling emerges as a powerful framework to overcome these limitations by strategically integrating high-fidelity atomistic simulations with efficient continuum mechanics approaches. The core principle involves decomposing the physical domain into regions where atomic-scale resolution is essential and regions where continuum approximations suffice, with carefully designed handshakes that facilitate information exchange across scales [21] [22]. This integration enables researchers to simulate phenomena where atomic-scale details critically influence macroscopic behavior, such as crack propagation, plastic deformation, and interface failure, while maintaining computational tractability for experimentally relevant length and time scales.
The bridging scale method represents one particularly advanced formulation for coupling MD with continuum mechanics. This approach employs a mathematical decomposition where the total displacement field (u) is expressed as the sum of a coarse-scale component (ū), computable by continuum methods like the Finite Element Method (FEM), and a fine-scale component (u'), derived from MD simulations [21]. This decomposition achieves kinetic energy uncoupling, allowing separate treatment of scale-specific dynamics while maintaining consistent mechanical information transfer between domains.
Theoretical Framework and Key Methodologies
Bridging Scale Formulation
The bridging scale method provides a rigorous mathematical foundation for coupling atomistic and continuum simulations. The fundamental decomposition is expressed as:
u = ū + u' [21]
where:
- u represents the total displacement field
- ū denotes the coarse-scale displacement computable by continuum methods
- u' signifies the fine-scale displacement derived from MD simulations
A critical innovation in this approach is the bridging scale projection, which ensures orthogonality between the coarse and fine scale solutions. This projection removes redundant information that would otherwise exist in both MD and continuum solutions, enabling efficient momentum and energy transfer between simulation domains [21]. The coarse scale is represented throughout the entire domain using continuous interpolation functions, while the fine scale is computed only in localized regions where atomic-resolution is scientifically necessary.
The kinetic energy uncoupling achieved through this formulation yields significant computational advantages. The equations of motion for both scales become coupled only through force terms, allowing for potential temporal discretization with different time steps in different domains—an approach known as subcycling [21]. This capability is particularly valuable given the typically faster dynamics in atomistic regions compared to continuum domains.
Generalized Langevin Formulation for Boundary Conditions
A particularly challenging aspect of multiscale modeling involves the formulation of physically consistent boundary conditions at the interface between atomistic and continuum domains. The bridging scale method addresses this through the derivation of a generalized Langevin equation for atoms at the boundary of the MD region [21]. This formulation effectively represents the influence of eliminated fine-scale degrees of freedom from the continuum region on the remaining MD simulation, preventing unphysical wave reflections at the interface.
The time-history kernel embedded in this equation encapsulates the memory effects of the eliminated degrees of freedom, ensuring proper energy dissipation from the fine-scale region into the continuum [21]. For simple systems like harmonic lattices, this kernel can be derived analytically, while more complex systems require numerical approaches. This boundary formulation represents a significant advancement over earlier coupling methods that often suffered from spurious reflections and impedance mismatches at the atomistic-continuum interface.
Mesoscopic Extensions
The bridging scale concept has been successfully extended beyond atomistic-to-continuum coupling to mesoscopic systems, particularly for complex fluid simulations. The Mesoscopic Bridging Scale (MBS) method adapts the core principles to couple Dissipative Particle Dynamics (DPD)—a coarse-grained particle method—with continuum fluid mechanics described by the Navier-Stokes equations [22].
In the MBS formulation, the particle velocity (vi) is decomposed into coarse-scale (v̄i) and fine-scale (v'_i) components:
vi = v̄i + v'_i [22]
where the coarse-scale velocity is obtained through finite element interpolation of nodal velocities. This approach has shown particular promise for modeling complex colloidal flows, such as blood flow in large arteries with thrombus development, where continuum methods adequately describe global hemodynamics while discrete particle methods capture localized cellular interactions [22].
Quantitative Data and Performance Metrics
Table 1: Characteristic Scales and Limitations in Molecular Dynamics Simulations
| Parameter | MD Limitations | Continuum Scale | Bridging Scale Advantage |
|---|---|---|---|
| Length Scale | ~10 nm domain [21] | Millimeters to meters | Atomic resolution where needed, continuum elsewhere |
| Time Scale | <100 ps [21] | Seconds to hours | Subcycling allows different timesteps in different domains |
| Strain Rates | ~10⁶ s⁻¹ [21] | 10⁻³ to 10³ s⁻¹ | Physically realistic loading conditions |
| Computational Cost | ~10,000 atoms for nanoseconds [22] | Millions of elements for seconds | Selective atomic resolution reduces cost by orders of magnitude |
| Temperature Effects | Limited by small system size [23] | Macroscopic averaging | Accurate thermal fluctuations in critical regions |
Table 2: Representative Applications of Bridged Scale Simulations
| Material System | Scientific Question | MD Contribution | Continuum Contribution |
|---|---|---|---|
| SiC/Al Composites [23] | Thermal residual stress evolution during cooling | Atomic-scale dislocation formation at interface | Macroscopic stress distribution in bulk material |
| Bulk Metallic Glasses [24] | Shear band formation and propagation | Atomic rearrangement in shear transformation zones | Elastic energy distribution and stress field |
| MscL Mechanosensitive Channels [25] | Gating mechanism under membrane deformation | Protein conformational changes at atomic resolution | Membrane deformation at cellular scale |
| Carbon Nanotubes [26] | Mechanical properties and fracture behavior | Quantum-mechanical bonding interactions | Continuum deformation and stress fields |
Table 3: Residual Stress Analysis in SiC/Al Composites After Cooling from Different Initial Temperatures [23]
| Initial Temperature (K) | Residual Stress Concentration | Dominant Dislocation Types | Affected Interface Area |
|---|---|---|---|
| 600 | Moderate | Shockley partials, stair-rod | Localized at interface |
| 700 | High | Shockley partials, stair-rod | Extended beyond interface |
| 800 | Very High | Shockley partials, stair-rod | Significantly extended |
| 900 | Maximum | Shockley partials (~80%), stair-rod (~18%) | Largest observed distribution |
Application Protocols
Protocol: Bridging Scale Implementation for Defect Analysis
This protocol outlines the procedure for implementing a bridging scale simulation to analyze defect evolution in metal matrix composites under thermal processing conditions, based on methodologies applied in SiC/Al composite studies [23].
System Setup and Domain Decomposition
Step 1: Problem Domain Identification
- Define the global domain dimensions based on the macroscopic component geometry (e.g., 40×40×40 nm³ for the composite model)
- Identify critical regions requiring atomic resolution (e.g., reinforcement-particle interfaces, predicted failure initiation sites)
- Establish the handshake region where MD and FEM domains will overlap, typically 2-3 atomic layers wide
Step 2: Mesh Generation and Discretization
- Generate finite element mesh for the continuum domain with appropriate element size transition
- Create atomic coordinates for the MD region using lattice-specific generation tools
- For composite systems, implement appropriate interatomic potentials for each material phase and their interactions (e.g., EAM potential for Al-Al, Vashishta potential for Si-C, Morse potential for Al-Si and Al-C interactions) [23]
Interatomic Potential Parameterization
Step 3: Potential Selection and Validation
- Select appropriate potential formalisms for each interaction type:
- Validate potentials against known material properties (elastic constants, surface energies, interface energies)
- Ensure smooth force transitions across the handshake region
Table 4: Morse Potential Parameters for SiC/Al Interface Interactions [23]
| Atom Pair | D₀ (eV) | α (Å⁻¹) | r₀ (Å) |
|---|---|---|---|
| Al-Si | 0.4824 | 1.322 | 2.92 |
| Al-C | 0.4691 | 1.738 | 2.246 |
Simulation Workflow
Thermal Processing Simulation
Step 4: Thermal Loading Implementation
- Initialize system at target temperature (e.g., 900K, 800K, 700K, or 600K) using NPT ensemble
- Apply temperature control using Nose-Hoover thermostat for 120 ps equilibration period
- Implement cooling phase at constant rate (e.g., 10¹² K/s) to target temperature (300K)
- Follow with secondary relaxation phase (120 ps) to stabilize the system [23]
Step 5: Multiscale Data Exchange
- Compute fine-scale fluctuations in MD region: u' = u - Nū
- Project MD forces to FEM nodes: f = Nᵀf_MD
- Apply Langevin boundary conditions to eliminate spurious wave reflections
- Exchange information at appropriate frequency based on coupling strength and dynamics
Protocol: MBS Method for Complex Fluid Simulations
This protocol adapts the bridging scale methodology for mesoscopic fluid simulations, particularly applicable to colloidal systems and complex fluids [22].
Mesoscopic Domain Setup
Step 1: Fluid Domain Discretization
- Discretize the entire fluid domain into finite elements for continuum representation
- Identify local regions requiring mesoscopic resolution (e.g., near boundaries, particle interactions)
- Implement Dissipative Particle Dynamics (DPD) model in local regions with appropriate coarse-graining level
Step 2: DPD Parameterization
- Determine conservative, dissipative, and random force coefficients for DPD interactions
- Establish appropriate particle density for the desired fluid properties
- Calibrate DPD parameters against known transport properties (viscosity, diffusion coefficients)
Velocity Decomposition and Coupling
Step 3: Multiscale Velocity Formulation
- Decompose particle velocity: vi = v̄i + v'i where v̄i is the finite element interpolated velocity
- Compute fine-scale velocity fluctuations: v' = v - Nv̄
- Evaluate FE internal nodal forces using viscous stresses from mesoscale model
Step 4: Coupled Time Integration
- Implement subcycling with smaller time steps for DPD region compared to FEM domain
- Exchange velocity and stress information at coupling interfaces
- Monitor energy balance between domains to ensure numerical stability
Table 5: Essential Computational Tools for Multiscale Materials Modeling
| Tool Category | Specific Package/Utility | Primary Function | Application Notes |
|---|---|---|---|
| MD Simulation Engines | LAMMPS [23] | Primary MD solver with various integrators and potentials | Open-source, highly scalable for large systems |
| Finite Element Solvers | Custom FEM codes [21] | Continuum mechanics solution | Often requires specialized development for multiscale coupling |
| Visualization & Analysis | OVITO [23] | Atomic structure visualization and defect analysis | Dislocation Extraction Algorithm (DXA) for defect identification |
| Interatomic Potentials | EAM [23], Vashishta [23], Morse [23] | 描述原子间相互作用 | Potential selection critical for simulation accuracy |
| Bridging Scale Libraries | Custom implementations [21] [22] | Scale coupling and projection operations | Projection operator implementation and Langevin boundary conditions |
Concluding Remarks and Future Perspectives
The integration of molecular dynamics with finite element methods through bridging scale approaches represents a paradigm shift in computational materials science. By strategically deploying atomic-resolution simulations only where scientifically necessary while employing efficient continuum methods elsewhere, researchers can now address problems previously considered intractable due to scale separation challenges.
The future development of multiscale methods will likely focus on several key areas: improved concurrent coupling algorithms that minimize spurious interface effects, extended temporal scaling through advanced accelerated dynamics, and integration of data-driven approaches where machine learning models replace expensive physical models in appropriate subdomains. Additionally, the ongoing development of interatomic potentials, particularly for complex multicomponent systems and reactive interfaces, will further enhance the predictive capability of multiscale simulations.
As computational resources continue to advance and algorithms become increasingly sophisticated, bridged scale simulations are poised to become central tools in the materials design process, enabling virtual prototyping of materials with tailored mechanical properties across multiple length scales.
Advanced Methods and Real-World Applications in Biomedicine and Materials Science
Molecular Dynamics (MD) simulations have become an indispensable tool for researching the mechanical properties of materials, enabling scientists to study physical movements at the atomic scale. The computational demands of these simulations are substantial, requiring careful hardware selection to achieve optimal performance. Recent advancements in GPU acceleration and parallelization strategies have dramatically transformed the field, making previously intractable simulations of complex systems not only feasible but efficient. This is particularly relevant for materials science, where understanding properties like fracture mechanics, elastic response, and energy dissipation requires simulating large systems over meaningful timescales.
The core challenge in traditional MD lies in the timescale gap; biologically or materially relevant events often occur on microsecond to second timescales, while simulation time steps must be in femtoseconds to maintain numerical stability. This necessitates billions of integration steps. High-Performance Computing (HPC) solutions, particularly those leveraging parallel GPU architectures, are bridging this gap, allowing researchers to probe the mechanical behavior of materials—from metals and alloys to polymers and energetic composites—with unprecedented atomic-level detail.
Hardware Foundations for MD Acceleration
GPU Selection and Configuration
Graphics Processing Units (GPUs) are the cornerstone of modern accelerated MD simulations, as they excel at the massive parallel processing required for calculating interatomic forces. The choice of GPU significantly impacts simulation performance, with key considerations being CUDA core count, clock speeds, and Video RAM (VRAM) capacity. The latter is especially critical for large systems simulating hundreds of thousands of atoms [27].
Table 1: Recommended GPUs for Molecular Dynamics Simulations
| GPU Model | Architecture | CUDA Cores | VRAM | Key Strengths for MD |
|---|---|---|---|---|
| NVIDIA RTX 6000 Ada | Ada Lovelace | 18,176 | 48 GB GDDR6 | Ideal for the largest, most memory-intensive simulations of complex materials [27] |
| NVIDIA RTX 4090 | Ada Lovelace | 16,384 | 24 GB GDDR6X | Excellent price-to-performance ratio for smaller simulations; high raw processing power [27] [28] |
| NVIDIA RTX 5000 Ada | Ada Lovelace | ~10,752 | 24 GB GDDR6 | Balanced performance for standard simulations; more budget-friendly [27] |
Different MD software packages leverage GPU resources in distinct ways. For instance, AMBER is highly optimized for NVIDIA GPUs and offloads all calculations to the GPU, making CPU choice less critical. In contrast, GROMACS and NAMD utilize both CPU and GPU, requiring a balanced system design [28]. Furthermore, LAMMPS, a popular code for materials modeling, offers many models with versions that provide accelerated performance on GPUs [29].
CPU, RAM, and System Architecture
While GPUs handle the bulk of the computation, the Central Processing Unit (CPU) plays a crucial supporting role. For MD workloads, it is generally recommended to prioritize processor clock speeds over core count. A CPU with too many cores can lead to underutilization in some MD software. A well-suited choice is a mid-tier workstation CPU with a balance of higher base and boost clock speeds [27]. For example, a 32 to 64-core processor from the AMD Threadripper PRO or Intel Xeon W-3400 series provides an optimal balance [28].
The role of the CPU becomes more critical in multi-GPU setups. Workstation and server-grade CPUs (AMD Threadripper PRO, Intel Xeon W-3400, AMD EPYC, Intel Xeon Scalable) offer more PCIe lanes, which are essential for accommodating multiple GPUs without creating a data transfer bottleneck [27] [28].
For system memory (RAM), ample capacity is necessary to prevent bottlenecks. Recommendations suggest populating all DIMM slots with at least 16GB modules, with 32GB DIMMs being optimal for larger workloads. This typically translates to 64GB to 256GB of RAM, depending on the scale of the simulations and the number of simultaneous jobs planned [28].
Parallelization Strategies and Enhanced Sampling Protocols
Algorithmic Parallelization in MD Software
Effective parallelization occurs at both the software and methodological levels. MD codes like LAMMPS are designed for parallel execution using message-passing techniques and a spatial-decomposition of the simulation domain [29]. This allows a single simulation to be distributed across many CPU cores and GPUs. The spatial decomposition algorithm is key to this process, dividing the physical simulation box into smaller regions that can be processed in parallel, with communication between regions to handle cross-boundary interactions [30].
Multi-GPU configurations can be leveraged in two primary ways:
- Single Job Scaling: A single simulation is distributed across multiple GPUs to decrease its runtime. Software like NAMD is known to scale well with multiple GPUs [28].
- High-Throughput Screening: Multiple independent simulations (e.g., testing different ligands or material configurations) are run simultaneously, each on a dedicated GPU. This is an effective strategy for AMBER and GROMACS, which may not always show perfect scaling for a single job across many GPUs [28].
Advanced Protocol: Parallelized Gaussian Accelerated Molecular Dynamics (ParGaMD)
For studying rare events or complex conformational changes in materials, enhanced sampling methods are essential. A novel protocol, ParGaMD (Parallelized Gaussian accelerated Molecular Dynamics), addresses the challenge of sampling large systems (>200,000 atoms) by combining enhanced sampling with efficient parallelization.
Principle: ParGaMD runs many short Gaussian accelerated molecular dynamics (GaMD) simulations over multiple GPUs in parallel using the weighted ensemble (WE) framework. While GaMD itself accelerates sampling by adding a harmonic boost potential, it can be slow for large systems and does not always parallelize efficiently. ParGaMD overcomes this bottleneck by leveraging the efficient GPU parallelization of the WE framework [31].
Experimental Workflow:
- System Preparation: Obtain the initial atomic coordinates and topology of the material system (e.g., a polymer composite or metal alloy).
- Collective Variable (CV) Selection: Identify and define the relevant CVs (e.g., distance between grain boundaries, radius of gyration of a polymer, or coordination number) that describe the mechanical property or transition of interest.
- ParGaMD Simulation Setup: Configure the parallel simulation using the provided software repositories (e.g., the AMBER- or OpenMM-based ParGaMD Github repos [31]). This includes setting parameters for the boost potential and the weighted ensemble resampling.
- Execution on HPC Cluster: Launch the simulation on a system with multiple GPUs. The ParGaMD algorithm will spawn numerous short trajectories in parallel, with periodic resampling based on the weights assigned to different regions of the CV space.
- Trajectory Analysis: The output is a set of trajectories that collectively provide a thorough exploration of the free energy landscape of the material system. These can be analyzed to determine thermodynamic and kinetic properties, such as energy barriers for fracture initiation or phase transitions [31].
This method has been shown to significantly speed up the sampling of different configurational states and dynamics, providing a powerful tool for the materials science community [31].
Diagram 1: The ParGaMD enhanced sampling workflow, which leverages parallel GPUs for efficient free energy exploration.
Emerging Integrations: Machine Learning Potentials
A revolutionary advancement in the field is the integration of machine learning (ML) with MD simulations. Neural Network Potentials (NNPs) are being developed to achieve the accuracy of quantum mechanical methods like Density Functional Theory (DFT) at a fraction of the computational cost, enabling large-scale and long-time-scale simulations of complex materials.
Protocol: Utilizing a General NNP for Energetic Materials A specific application note involves using a general NNP like EMFF-2025, designed for C, H, N, O-based high-energy materials (HEMs) to predict mechanical properties and decomposition behavior [2].
- Model Deployment: Start with a pre-trained NNP model (e.g., EMFF-2025) which has been trained on a diverse dataset of HEMs using a transfer learning strategy. This model is integrated into an MD engine that supports ML potentials.
- Simulation Setup: Prepare the initial crystal structure of the HEM of interest. The NNP does not require reparameterization, saving significant time.
- Property Prediction:
- Mechanical Properties: Perform NPT ensemble simulations at low temperatures to calculate elastic constants, bulk modulus, and shear modulus, providing insights into mechanical stability.
- Decomposition Mechanisms: Run high-temperature simulations to observe initial reaction pathways, decomposition products, and energy release mechanisms with DFT-level accuracy.
- Data Analysis: Use principal component analysis (PCA) and correlation heatmaps to analyze the simulation data, mapping the chemical space and identifying key structural motifs that govern material properties and reactivity [2].
This approach has been validated by predicting the structure, mechanical properties, and decomposition characteristics of 20 different HEMs, successfully challenging conventional views about their material-specific decomposition behavior [2]. This ML-integrated protocol offers a versatile framework for accelerating the design and optimization of novel materials.
The Scientist's Toolkit: Essential Research Reagents and Software
Table 2: Key Software and Computational Tools for Accelerated MD
| Tool Name | Type | Primary Function in MD | Relevance to Materials Mechanical Properties |
|---|---|---|---|
| LAMMPS [29] | MD Simulator | A highly versatile and scalable classical MD code with a focus on materials modeling. | Features specialized packages like the Bonded Particle Model (BPM) for modeling solid mechanics, fracture, and granular composites [29]. |
| BIOVIA Materials Studio [32] | Modeling Environment | An integrated environment for predicting atomic/molecular structure relationships with material properties and behavior. | Used to engineer better-performing materials like polymers, composites, metals, and alloys through in-silico screening [32]. |
| AMBER, GROMACS, NAMD [27] [28] | MD Simulator | Leading MD software packages optimized for biomolecules, but also applicable to soft materials. | Well-optimized for NVIDIA GPUs; used for studying polymers, biomolecules, and other soft matter systems. |
| Rowan Platform [33] | ML & Simulation Platform | Provides fast neural network potentials (e.g., Egret-1, AIMNet2) for chemistry simulations. | Enables accurate, quantum-mechanics-level simulations of material systems millions of times faster than traditional methods [33]. |
| GROMOS 54a7 [34] | Force Field | A molecular mechanics force field parameter set. | Used in MD studies to model molecular interactions and predict properties like solvation free energy, which can influence material behavior [34]. |
The strategic application of GPU acceleration and sophisticated parallelization algorithms has fundamentally enhanced the capability of molecular dynamics simulations in materials science. By selecting appropriate hardware, such as high-CUDA-core NVIDIA GPUs, and employing advanced methods like ParGaMD and machine learning potentials, researchers can now efficiently explore the mechanical properties of complex materials at an atomic level with unprecedented speed and accuracy. These HPC-driven protocols are paving the way for the rapid, in-silico design and optimization of next-generation materials, from advanced composites and polymers to high-energy systems.
Molecular dynamics (MD) simulations have become an indispensable tool in computational materials science and drug discovery, functioning as a "microscope with exceptional resolution" for observing atomic-scale dynamics [13]. These simulations predict the motion of every atom in a system over time based on physics-governed interatomic interactions, capturing processes including conformational changes, ligand binding, and material deformation at femtosecond resolution [35]. The impact of MD has expanded dramatically in recent years due to major improvements in simulation speed, accuracy, and accessibility, alongside a proliferation of experimental structural data [35]. This application note provides a comprehensive framework for employing MD simulations to investigate the mechanical properties of diverse material systems, encompassing metals, alloys, polymers, and biomolecules, with detailed protocols designed for researchers, scientists, and drug development professionals.
Fundamental MD Simulation Workflow
The standard workflow for MD simulations consists of several interconnected stages, each requiring careful execution to ensure physically meaningful results.
Core Procedural Framework
Figure 1: Comprehensive workflow for molecular dynamics simulations illustrating the sequential stages from initial structure preparation to scientific insight generation.
Workflow Stage Specifications
Initial Structure Preparation: MD simulations begin with preparing the initial atomic coordinates of the target system [13]. For biomolecules, structures are often obtained from the Protein Data Bank (PDB), while material crystal structures can be sourced from repositories like the Materials Project or AFLOW [13]. Novel systems may require building atomic models from scratch based on experimental data or theoretical predictions. The accuracy of this initial model critically influences simulation reliability, and while emerging AI tools like AlphaFold2 have simplified structure prediction, expert validation remains essential to ensure physical and chemical plausibility [13].
System Initialization and Boundary Conditions: After structure preparation, initial velocities are assigned to all atoms, typically sampled from a Maxwell-Boltzmann distribution corresponding to the target simulation temperature [13]. Periodic Boundary Conditions (PBC) are then applied to minimize edge effects by creating a periodic replication of the simulation box in all directions [36]. For a protein system, a cubic box with a minimum 1.0 Å distance between the protein and box edges is recommended, though larger distances may be necessary for specific systems [36].
Solvation and Ionization: To mimic physiological or solution environments, the simulation system requires solvation with water molecules and ionization to neutralize overall system charge [36]. The
solvatecommand in GROMACS adds water molecules, whilegenionintroduces counterions to achieve charge neutrality [36]. For non-biological systems like metals or polymers, solvation may be omitted depending on the research objectives.Force Calculation and Integration: Interatomic forces are calculated using molecular mechanics force fields, which incorporate terms for electrostatic interactions, covalent bond stretching, angle bending, and other interatomic interactions [35] [13]. These forces are then used to numerically solve Newton's equations of motion through integration algorithms like Verlet or leap-frog, typically using time steps of 0.5–1.0 femtoseconds to maintain numerical stability while capturing atomic motions [13].
Case Study: Mechanical Properties of γ-TiAl Alloys
Experimental Objectives and Setup
This case study employs MD simulations to investigate the tensile mechanical properties and microscopic deformation mechanisms of γ-TiAl alloys, aerospace materials valued for their high-temperature strength, low density, and superior oxidation resistance [37]. The primary objectives include quantifying the effects of temperature, strain rate, and grain size on mechanical behavior, and elucidating underlying deformation mechanisms including dislocation motion, phase transformation, and grain boundary sliding [37].
Protocol Steps:
Model Construction:
- Build polycrystalline γ-TiAl models using Atomsk software with lattice constants a = 3.992 Å and c = 4.072 Å [37].
- Create a simulation box of size 300 Å × 100 Å × 100 Å containing grains with random crystallographic orientations [37].
- Generate grain sizes varying from 5–15 nm to investigate size-dependent mechanical responses [37].
Simulation Parameters:
- Perform simulations using LAMMPS software with an embedded atom method (EAM) potential for Ti-Al interactions [37].
- Set temperatures ranging from 0.1–750 K and strain rates from 1×10^8–1×10^10 s⁻¹ [37].
- Apply periodic boundary conditions in all directions and use a time step of 1–2 femtoseconds [37].
Deformation Protocol:
- Conduct uniaxial tensile deformation by applying strain along specific crystallographic directions.
- Calculate stress using the virial theorem formulation during deformation.
- Identify dislocation nucleation and motion using Common Neighborhood Analysis (CNA) and Dislocation Extraction Algorithm (DXA) [37].
Key Findings and Quantitative Results
Table 1: Effects of simulation parameters on mechanical properties of γ-TiAl alloys from MD simulations [37]
| Parameter | Variation Range | Effect on Yield Strength | Effect on Young's Modulus | Dominant Deformation Mechanism |
|---|---|---|---|---|
| Temperature | 0.1–750 K | Decreases with increasing temperature | Decreases with increasing temperature | Dislocation slip dominates at lower temperatures; grain boundary sliding increases at higher temperatures |
| Strain Rate | 1×10⁸–1×10¹⁰ s⁻¹ | Increases with higher strain rates | Increases with higher strain rates | Enhanced dislocation nucleation at higher rates; shift toward disordered atomic motion at extreme rates |
| Grain Size | 5–15 nm | Inverse Hall-Petch relationship (decreased strength with smaller grains below ~12 nm) | Minimal direct effect | Grain boundary sliding and rotation in smaller grains; dislocation-mediated plasticity in larger grains |
Analysis revealed a pronounced inverse Hall-Petch effect where strength decreased with grain size reduction below approximately 12 nm, accompanied by a transition from dislocation-mediated plasticity to grain boundary sliding [37]. At elevated temperatures, reduced strength and stiffness correlated with increased atomic diffusion and lattice distortion [37].
Advanced Integration with Machine Learning
The researchers complemented MD simulations with explainable machine learning (ML) models to predict mechanical performance and identify critical predictive features [37]. Using stress-strain data generated from MD simulations, they trained multiple ML models including Random Forest and Gradient Boosting, achieving high prediction accuracy (R² = 0.9856 for tensile strength) [37]. The SHAP (SHapley Additive exPlanations) method identified temperature as the most significant feature influencing mechanical responses, followed by strain rate and grain size [37]. This MD-ML integration demonstrated approximately 185–2100× speed-up compared to traditional MD simulations while maintaining high accuracy [38].
Case Study: Thermal Residual Stresses in SiC/Al Composites
Experimental Design and Execution
This case study examines the formation of thermal residual stresses in silicon carbide reinforced aluminum composites (SiC/Al) during cooling from processing temperatures, investigating how thermal history influences residual stress distribution, dislocation evolution, and resultant mechanical properties [23].
Protocol Steps:
Model Construction:
- Create a 40.0 × 40.0 × 40.0 nm³ cubic aluminum matrix with a 20.0 nm diameter spherical SiC particle at its center [23].
- Align the x, y, and z coordinates with the [100], [010], and [001] lattice directions, respectively [23].
- Incorporate approximately 3.9 million atoms to minimize boundary effects [23].
Potential Selection:
Cooling Simulation:
- Initialize systems at temperatures of 600 K, 700 K, 800 K, and 900 K [23].
- Apply energy minimization using the conjugate gradient algorithm [23].
- Equilibrate systems in an NPT ensemble for 120 ps at target temperatures under zero external pressure [23].
- Cool systems to 300 K at a constant rate of 10¹² K/s [23].
- Perform post-cooling relaxation for 120 ps to ensure stability [23].
Mechanical Testing:
Residual Stress and Dislocation Analysis
Table 2: Cooling-induced defects and mechanical property changes in SiC/Al composites [23]
| Initial Cooling Temperature (K) | Residual Stress Concentration | Dominant Dislocation Types | Dislocation Length Distribution | Reduction in Mechanical Properties |
|---|---|---|---|---|
| 600 K | Moderate interface stress | Shockley partials, stair-rod dislocations | ~80% Shockley partials, ~18% stair-rod dislocations | Minimal reduction |
| 700 K | High interface stress | Shockley partials, stair-rod dislocations | ~80% Shockley partials, ~18% stair-rod dislocations | Moderate reduction |
| 800 K | Very high interface stress | Shockley partials, stair-rod dislocations | ~80% Shockley partials, ~18% stair-rod dislocations | Significant reduction |
| 900 K | Severe interface stress | Shockley partials, stair-rod dislocations | ~80% Shockley partials, ~18% stair-rod dislocations | Severe reduction |
Analysis revealed that residual stresses primarily concentrated at the SiC/Al interface, with higher initial cooling temperatures producing greater stress values and larger affected areas [23]. During cooling, Shockley partials and stair-rod dislocations dominated the dislocation structures, with approximately 80% of dislocation length comprising Shockley partials and 18% stair-rod dislocations [23]. Mechanical properties consistently degraded after cooling, with more significant reductions following higher initial temperature cycles [23].
The Scientist's Toolkit: Essential Research Reagents and Software
Table 3: Essential software tools for molecular dynamics simulations across material systems
| Tool Name | Primary Application Domain | Key Features | Typical Use Cases |
|---|---|---|---|
| LAMMPS | Metals, alloys, polymers, general materials [29] [39] | Robust parallel computing, supports various potentials (EAM, Tersoff), flexible [29] [39] | Large-scale metallic systems, nanocomposites, mechanical deformation [37] [23] |
| GROMACS | Biomolecules, polymers, soft matter [36] [39] | Optimized for biomolecular systems, high performance for proteins, lipids [36] [39] | Protein dynamics, drug binding, polymer behavior in solution [36] |
| MS Maestro | Materials science, drug discovery [40] | Integrated workflows, quantum mechanics/MD/ML, user-friendly interface [40] | Catalyst design, battery materials, polymer formulation [40] |
| OVITO | All material classes (visualization and analysis) [23] | Dislocation Extraction Algorithm (DXA), Common Neighborhood Analysis [23] | Defect identification, deformation mechanism analysis, trajectory visualization [23] |
| Python/Pymatgen | All material classes (analysis and setup) [38] | Materials analysis, structure manipulation, automated workflow scripting [38] | High-throughput simulation setup, data analysis, machine learning integration [38] |
Advanced Techniques and Emerging Trends
Machine Learning-Enhanced Simulations
Machine learning has revolutionized MD simulations through several advanced applications. Machine Learning Interatomic Potentials (MLIPs) are trained on quantum chemistry datasets, enabling accurate and efficient force calculations for complex material systems previously considered computationally prohibitive [13]. Surrogate models using 3D Convolutional Neural Networks (CNNs) can predict material properties from atomistic structures, achieving 185–2100× speed-up compared to traditional MD while maintaining high accuracy (RMSE < 0.65 GPa for elastic constants) [38]. Deep learning algorithms also facilitate advanced trajectory analysis through techniques like interactive visual analysis of simulation embeddings and automated identification of metastable states [41].
Specialized Simulation Approaches
Table 4: Advanced molecular dynamics simulation methodologies
| Methodology | Key Principles | Application Examples |
|---|---|---|
| Quantum Mechanics/Molecular Mechanics (QM/MM) | Combines quantum mechanical accuracy for reaction centers with molecular mechanics efficiency for surroundings [35] | Chemical reactions, electron transfer processes, photochemical phenomena [35] |
| Machine Learning Force Fields (MLFF) | Uses machine learning to create accurate, transferable force fields from quantum mechanical data [40] | Complex multi-element systems, reactive processes, accelerated property prediction [40] |
| Coarse-Grained Modeling | Reduces system complexity by grouping multiple atoms into effective interaction sites [40] | Large biomolecular systems, polymer dynamics, long-time scale processes [40] |
| Enhanced Sampling Methods | Accelerates exploration of configuration space through bias potentials or collective variables [35] | Protein folding, rare events, phase transitions, free energy calculations [35] |
Molecular dynamics simulations provide an powerful atomic-scale framework for investigating the mechanical properties of diverse material systems, from structural metals and alloys to functional polymers and biomolecules. The integration of MD with machine learning approaches dramatically accelerates materials discovery while maintaining physical accuracy, enabling researchers to establish robust structure-property relationships across multiple length and time scales. As simulation methodologies continue advancing alongside computational hardware, MD will play an increasingly central role in rational materials design and drug development, allowing scientists to virtually screen candidate systems and optimize performance characteristics before experimental synthesis and testing.
Molecular dynamics (MD) simulations have emerged as a pivotal technology in structural biology and drug discovery, enabling researchers to probe the dynamic behavior of proteins and their interactions with ligands at an atomic level. While traditionally prominent in materials science for investigating mechanical properties, these computational methods provide unparalleled insights into the conformational flexibility of biological macromolecules, which is crucial for understanding function and facilitating rational drug design [42]. Proteins are not static entities; they exist as ensembles of interconverting conformations, and their dynamics are central to biological activities such as signal transduction and allosteric regulation [43] [42]. The ability of MD simulations to capture these atomic-scale motions and the detailed process of ligand binding offers a powerful complement to experimental techniques, helping to elucidate the molecular basis of diseases and their treatments [42]. This document outlines key protocols and applications of MD simulations in drug discovery, focusing on their capacity to unveil protein dynamics and ligand binding mechanisms, thereby accelerating the development of therapeutic compounds.
Key Application Note: Capturing Protein Dynamics for Ligand Binding
The Challenge of Protein Flexibility in Drug Design
A significant challenge in structure-based drug discovery is the inherent dynamics of protein targets. Traditional molecular docking methods, a key component of virtual screening, often treat proteins as rigid bodies to manage computational costs [43]. However, this simplification fails to capture the ligand-induced conformational changes that are often essential for binding. For instance, AlphaFold-predicted structures, while revolutionary, typically represent a single conformational state and may not present the optimal side-chain configurations or backbone arrangements for ligand binding [43]. Consequently, using these apo-like structures for rigid docking can yield inaccurate ligand poses and misleading results for drug discovery campaigns.
MD Simulations as a Solution
MD simulations address this limitation by modeling the full flexibility of the protein-ligand system over time. By applying Newton's equations of motion to all atoms in the system, MD can simulate the physical movements of proteins and ligands, allowing for the observation of large-scale conformational changes, side-chain rearrangements, and the formation of transient binding pockets [43] [44]. This capability is crucial for studying processes like the well-known DFG-in to DFG-out transition in kinase proteins, which is a major conformational change relevant to drug binding [43]. Furthermore, advanced sampling techniques like accelerated MD (aMD) enhance the efficiency of simulating these rare biological events, making it feasible to observe ligand binding processes within computationally accessible timescales [44].
Quantitative Performance of Advanced Methods
Recent advances integrate deep learning with physical principles to push the boundaries of dynamic docking. The following table summarizes the performance of DynamicBind, a deep generative model for dynamic docking, compared to traditional rigid docking and other deep learning baselines.
Table 1: Performance Benchmark of DynamicBind on Different Test Sets [43]
| Method | Test Set | Success Rate (RMSD < 2 Å, Clash < 0.35) | Success Rate (RMSD < 5 Å, Clash < 0.5) | Key Capability |
|---|---|---|---|---|
| DynamicBind | PDBbind | 33% | 65% | Recovers holo-structures from apo-like inputs |
| DynamicBind | Major Drug Target (MDT) | 39% | 68% | Samples large conformational changes (e.g., DFG flip) |
| DiffDock (Baseline) | PDBbind | 19% | Not Reported | Treats protein as largely rigid |
| Traditional Docking | General | Low (Due to rigidity) | Low (Due to rigidity) | Fast but limited by fixed protein conformation |
Experimental Protocols
Protocol 1: Accelerated MD (aMD) for Simulating Ligand Binding to GPCRs
This protocol describes the use of aMD, an enhanced sampling technique, to simulate the binding of diverse ligands to G-protein coupled receptors (GPCRs), a pharmaceutically important protein family [44].
Materials and System Setup
- Initial Coordinate File: Obtain a protein structure from a database like the Protein Data Bank (e.g., PDB: 4DAJ for the M3 muscarinic receptor). Remove the crystallographic ligand if simulating binding from the bulk [44].
- Molecular Visualization and Modeling Software: VMD is used for system preparation, including:
- Removing non-essential fusion proteins (e.g., T4 lysozyme in ICL3).
- Capping chain termini with neutral groups.
- Maintaining resolved disulphide bonds.
- Setting standard protonation states for residues (e.g., protonating Asp1132.50 in M3R, deprotonating Asp1473.32) [44].
- Ligand Topology and Parameter Files: Generate force field parameters for the ligand using tools like GAAMP (General Automated Atomic Model Parameterization) or retrieve them from databases like CGenFF if available [44].
- Simulation Software: NAMD or a similar MD engine that supports aMD [44].
- Force Fields:
- System Building:
- Insert the protein into a POPC lipid bilayer using the Membrane plugin in VMD, removing overlapping lipids.
- Solvate the system in a water box using the Solvate plugin.
- Place multiple ligand molecules (e.g., 4) at least 40 Å away from the orthosteric binding site in the bulk solvent.
- Neutralize the system charge by adding ions (e.g., Cl⁻) [44].
Step-by-Step Procedure
- Energy Minimization:
- Fix all non-lipid atoms and minimize the lipid tails for 1000 steps using the conjugate gradient algorithm to melt the tails [44].
- System Equilibration:
- Gradually heat the system to the target temperature (e.g., 310 K) over tens of picoseconds.
- Equilibrate the entire system in the NPT ensemble (constant Number of particles, Pressure, and Temperature) for several nanoseconds until density and energy stabilize [44].
- Accelerated MD (aMD) Production Simulation:
- Apply the aMD modification to the potential energy. A non-negative boost potential is added when the system's potential energy falls below a defined threshold, effectively reducing energy barriers and accelerating conformational transitions [44].
- Run the aMD simulation for hundreds of nanoseconds to observe ligand binding events. Use a 2 fs integration time-step and employ the SHAKE algorithm to constrain bonds involving hydrogen.
- Apply periodic boundary conditions and use a 12 Å cutoff for van der Waals and short-range electrostatic interactions. Calculate long-range electrostatics using the Particle Mesh Ewald (PME) method [44].
- Trajectory Analysis:
- Monitor the root-mean-square deviation (RMSD) of the protein and ligand.
- Calculate the distance between the ligand and the center of the orthosteric binding site over time to identify binding events.
- Use visualization software (e.g., VMD, PyMOL) to inspect the trajectory and identify metastable binding sites, such as the extracellular vestibule in GPCRs [44].
Protocol 2: A Multiscale (BD/MD) Approach for Calculating Association Rate Constants (kₒₙ)
This protocol combines Brownian Dynamics (BD) and MD simulations to efficiently compute protein-ligand association rate constants, a key pharmacokinetic parameter [45].
Materials and System Setup
- Protein Structure: A solvated protein structure file (PDB format).
- Ligand Structure: A parameterized ligand file.
- BD Simulation Software: e.g., SDA (Simulation of Diffusional Association).
- MD Simulation Software: e.g., GROMACS, NAMD, or OpenMM.
Step-by-Step Procedure
- Brownian Dynamics (BD) Simulation:
- Objective: Simulate the long-range diffusion and formation of diffusional encounter complexes between the protein and ligand.
- Setup: Place the protein fixed in space and simulate the random diffusion of the ligand under the influence of Brownian motion and simplified intermolecular forces.
- Execution: Run multiple BD trajectories until a sufficient number of "hits" are recorded, where the ligand comes very close to the protein's active site. This ensemble of structures represents the starting points for the MD stage [45].
- Structure Preparation for MD:
- Select multiple encounter complexes generated from the BD simulations where the ligand is near the active site.
- For each complex, create a fully atomistic system with explicit solvent and ions, following standard MD setup procedures (similar to Section 3.1.1).
- Molecular Dynamics (MD) Simulation:
- Objective: Capture the short-range interactions and molecular flexibility as the encounter complex transitions to the fully bound state.
- Execution: Run multiple, relatively short MD simulations (e.g., tens to hundreds of nanoseconds) starting from the different BD-generated encounter complexes. This step allows for side-chain and backbone adjustments, induced-fit binding, and the final "docking" step [45].
- Analysis and kₒₙ Calculation:
- Identify successful binding events from the MD trajectories.
- The association rate constant, kₒₙ, is calculated based on the probability of forming a stable bound complex from the BD and MD simulations [45].
The following diagram illustrates the logical workflow of this multiscale approach:
The following table details key computational tools, software, and data resources essential for conducting MD studies on protein-ligand interactions.
Table 2: Key Research Reagent Solutions for MD Simulations in Drug Discovery
| Item Name | Type | Function/Brief Explanation | Example/Note |
|---|---|---|---|
| CHARMM Force Field | Force Field | Defines potential energy functions for proteins, nucleic acids, lipids, and carbohydrates, governing atomic interactions. | Includes parameters for standard amino acids and lipids; CGenFF for small molecules [44]. |
| GAAMP | Parameterization Tool | Generates CHARMM-compatible force field parameters for novel ligand molecules using ab initio QM calculations. | Used for ligands like tiotropium when pre-parameterized files are unavailable [44]. |
| VMD | Software | A molecular visualization and analysis program used for system setup, trajectory analysis, and rendering. | Used for embedding proteins in membranes, solvation, and adding ions [44]. |
| NAMD / GROMACS / OpenMM | Software | High-performance MD simulation engines that perform the numerical integration of Newton's equations of motion. | NAMD was used in the aMD protocol for GPCRs [44]; OpenMM is used for MM/GBSA calculations [46]. |
| DynamicBind | Software/Model | A deep learning model for "dynamic docking" that predicts ligand-bound structures while accommodating large protein conformational changes. | Handles transitions like the DFG flip in kinases from apo-like structures [43]. |
| PDBbind Database | Database | A curated collection of experimentally determined protein-ligand complex structures and their binding affinities. | Used for training and benchmarking docking and scoring methods [43]. |
| BindingDB | Database | A public database of measured binding affinities for drug-like molecules and proteins. | Used for model validation and dataset construction in binding affinity prediction studies [46]. |
| MM/PBSA & MM/GBSA | Method | End-point methods to estimate binding free energy from MD snapshots by combining molecular mechanics with implicit solvation. | Faster than FEP but less accurate; often used for ranking ligands [46]. |
Molecular dynamics simulations have fundamentally expanded the toolkit available to drug discovery researchers, moving beyond static structural pictures to a dynamic paradigm where protein motion is recognized as a key determinant of function and druggability. Through protocols like accelerated MD for capturing binding events and multiscale approaches for calculating kinetic parameters, MD provides critical insights that are difficult to obtain experimentally. The integration of these methods with machine learning, as exemplified by tools like DynamicBind, promises to further enhance the accuracy and efficiency of computational drug design. As force fields, sampling algorithms, and computing power continue to advance, MD simulations will play an increasingly central role in unraveling the complexities of protein dynamics and ligand binding, ultimately accelerating the development of novel therapeutics for a wide range of diseases.
The design of next-generation structural materials, particularly complex concentrated alloys (CCAs) and multi-principal element alloys (MPEAs), requires a deep understanding of the atomic-scale mechanisms that govern their mechanical strength and deformation behavior. Molecular dynamics (MD) simulations have emerged as a powerful tool for probing these mechanisms at the discrete atomic scale, providing insights that are often challenging to obtain experimentally [47]. The integration of machine learning interatomic potentials (ML-IAPs) has further revolutionized this field, enabling simulations that approach the accuracy of density functional theory (DFT) while accessing the larger spatial and temporal scales necessary to study dislocation dynamics and plastic deformation [48]. This case study examines the application of advanced MD simulation frameworks, enhanced by machine learning, to predict and elucidate the complex strengthening mechanisms in refractory MPEAs, with a specific focus on the NbMoTaW alloy system.
Experimental Protocols
Development of a Machine Learning Interatomic Potential
Objective: To generate a highly accurate spectral neighbor analysis potential (SNAP) for the quaternary NbMoTaW MPEA system capable of reproducing DFT-level accuracy in energy and force predictions for diverse atomic configurations [48].
Workflow:
- Elemental Potential Fitting: Initially, individual SNAP models were fitted for each component element (Nb, Mo, Ta, W). The training data included DFT-computed energies and forces for ground-state structures, strained structures, surface structures, and snapshots from ab initio molecular dynamics (AIMD) simulations. The optimized cutoff radii (({R}_{{\rm{c}}}^{{\rm{El}}})) ranged from 4.5 to 4.7 Å [48].
- Atomic Weight Grid Search: The elemental cutoff radii were fixed, and a grid search was performed for the atomic weights (({S}_{{\rm{atom}}}^{k})) by generating a series of SNAP models with different combinations. Only the inner optimization loop was run in this step [48].
- Full Model Optimization: The ten best combinations of atomic weights from the previous step were selected for a full optimization, which included optimizing the data weights in the outer loop of the optimization unit. The model with the smallest mean absolute error (MAE) in energies and forces was selected as the final MPEA SNAP model [48].
Validation: The finalized MPEA SNAP model was validated against a test set of structures comprising approximately 10% of the training data size [48]. The model demonstrated excellent performance, with overall training and test MAEs for energies and forces within 6 meV/atom and 0.15 eV/Å, respectively [48]. Table 1 summarizes key validation metrics.
Table 1: Performance Metrics of the NbMoTaW MPEA SNAP Model [48]
| Property | Performance Metric | Value |
|---|---|---|
| Energy Prediction | Mean Absolute Error (MAE) | < 6 meV/atom |
| Force Prediction | Mean Absolute Error (MAE) | < 0.15 eV/Å |
| Elastic Moduli | Error for elemental systems | < 10% (typically) |
| Dislocation Core | Predicted structure | Non-degenerate (consistent with DFT) |
Analysis of Dislocation Dynamics and Strengthening
Objective: To utilize the validated MPEA SNAP model to simulate screw dislocations and compute the Peierls stress in the NbMoTaW MPEA, comparing the results to its constituent elemental metals [48].
Workflow:
- System Preparation: An atomistic simulation cell containing a single 1/2〈111〉 screw dislocation was created for the NbMoTaW MPEA using a special quasi-random structure (SQS) and for each elemental bcc metal (Nb, Mo, Ta, W).
- Core Structure Analysis: The core structure of the screw dislocation was relaxed and analyzed using classical differential displacement plots at multiple points (0b, 4b) along the dislocation line to account for compositional fluctuations [48].
- Peierls Stress Calculation: A shear strain was applied incrementally to the simulation cell at a temperature of 0 K. The Peierls stress was identified as the critical resolved shear stress (CRSS) required to initiate irreversible dislocation motion [48].
- Generalized Stacking Fault (GSF) Energy Calculation: The γ-surface for the {110} plane in the 〈111〉 direction was computed by rigidly sliding two halves of a crystal and calculating the energy of the resulting fault [48].
Results and Data Analysis
Quantitative Data on Strengthening Mechanisms
The atomistic simulations revealed fundamental differences in the deformation behavior of the MPEA compared to its constituent elements.
Table 2: Peierls Stress and Stacking Fault Energy of NbMoTaW vs. Elemental Metals [48]
| Material | Screw Dislocation Peierls Stress (GPa) | Edge Dislocation Peierls Stress (GPa) | Unstable Stacking Fault Energy (mJ/m²) |
|---|---|---|---|
| Nb | Data from simulation | Data from simulation | ~300 |
| Mo | Data from simulation | Data from simulation | ~650 |
| Ta | Data from simulation | Data from simulation | ~550 |
| W | Data from simulation | Data from simulation | ~700 |
| NbMoTaW MPEA | Greatly increased | Greatly increased | ~600 |
Table 3: Key Strengthening Mechanisms Identified in NbMoTaW MPEA [48]
| Mechanism | Description | Atomic-Level Cause | Effect on Mechanical Properties |
|---|---|---|---|
| Solid Solution Strengthening | Impediment of dislocation motion due to atomic-size and modulus mismatch. | Different atomic radii and elastic moduli of Nb, Mo, Ta, and W. | Increases yield strength. |
| Short-Range Order (SRO) Strengthening | Dislocations must break preferential atomic bonds. | Thermochemically driven local chemical ordering. | Significantly increases strength. |
| Grain Boundary Segregation | Stabilization of grain boundaries (GBs) against deformation. | Thermodynamically driven Nb segregation to GBs. | Increases GB stability and strength. |
Multiscale Simulation Workflow
The following diagram illustrates the automated, intelligent multiscale simulation framework that bridges atomic-scale discrete mechanics with mesoscale continuum mechanics to predict mechanical properties [47].
Machine Learning Interatomic Potential Development
The workflow for developing the high-accuracy machine-learned potential is detailed below, highlighting the multi-step optimization process [48].
The Scientist's Toolkit
Table 4: Essential Research Reagents and Computational Tools
| Tool/Solution | Function in Workflow | Application in this Study |
|---|---|---|
| Spectral Neighbor Analysis Potential (SNAP) | Machine-learning interatomic potential that provides near-DFT accuracy for complex multi-element systems. | Enabled large-scale atomistic simulations of the NbMoTaW MPEA to study dislocation dynamics [48]. |
| Conditional Generative Adversarial Network (CGAN) | A generative ML model that learns the mapping between atomic configurations and corresponding strain fields. | Automatically transformed atomic configurations of CCAs into discrete atomic strain tensors for multiscale simulation [47]. |
| Density Functional Theory (DFT) | First-principles computational method for electronic structure calculations. | Generated reference data on energies and forces for training and validating the ML-IAP [48]. |
| Discrete Dislocation Dynamics (DDD) | Mesoscale simulation method for modeling collective behavior of large dislocation ensembles. | Simulated dislocation mechanisms at the mesoscale, informed by atomic-scale strain data [47]. |
| Crystal Plasticity Finite Element (CPFE) | Continuum-scale simulation method relating polycrystal microstructure to macroscopic response. | Predicted macroscopic mechanical response, incorporating effects of grain orientation and boundaries [47]. |
| VMD / PyContact | Molecular visualization and analysis software. PyContact provides a GUI for analyzing noncovalent interactions in MD trajectories. | Visualization of simulation trajectories and analysis of interaction networks; synergistic connection with VMD for result mapping [49] [41]. |
Intrinsically Disordered Proteins (IDPs) are a class of proteins that lack a well-defined tertiary structure under physiological conditions, yet perform critical biological functions in cellular signaling, regulation, and disease pathways. Unlike folded proteins, IDPs exist as dynamic structural ensembles of rapidly interconverting conformations. This inherent flexibility makes their structural characterization extremely challenging, as traditional structural biology methods are geared toward defining single, stable conformations. Molecular dynamics (MD) simulations provide a powerful approach for determining atomic-resolution conformational ensembles of IDPs in silico, bridging the gap between sequence and function. This case study examines current methodologies, protocols, and applications of MD simulations for sampling IDP conformational ensembles, with particular emphasis on integrative approaches that combine computational and experimental data.
The Challenge of IDP Conformational Sampling
Fundamental Limitations in IDP Characterization
The structural characterization of IDPs presents unique challenges that differentiate them from folded proteins:
- Structural Heterogeneity: IDPs populate a broad ensemble of conformations rather than a single dominant structure, making traditional structure determination methods inadequate [50].
- Sparse Experimental Data: Experimental techniques provide ensemble-averaged measurements that are consistent with numerous possible conformational distributions, creating an underdetermined problem [51] [52].
- Dynamic Timescales: IDPs interconvert between conformational states on timescales that can challenge both experimental observation and computational sampling [50].
Limitations of Molecular Dynamics Simulations
While MD simulations can provide atomically detailed structural information, their accuracy for IDPs is constrained by several factors:
- Force Field Accuracy: The quality of IDP ensembles derived from MD is highly dependent on the physical models (force fields) used, with different force fields often producing varying conformational distributions [51].
- Sampling Limitations: The flatter energy landscape of IDPs contains many local minima separated by modest barriers, requiring exponentially longer simulation times to achieve representative sampling compared to folded proteins [50].
- Convergence Challenges: Even long timescale simulations (e.g., 30 μs for a 40-residue peptide) may show limited convergence at the secondary structure level [50].
Methodologies for Conformational Ensemble Determination
Integrative Structural Biology Approaches
Integrative approaches that combine MD simulations with experimental data have emerged as powerful strategies for determining accurate IDP conformational ensembles:
- Maximum Entropy Reweighting: This approach introduces minimal perturbation to computational models required to match experimental data, preserving the physical realism of the simulation while improving agreement with experiments [51].
- Experimental Restraints: Nuclear Magnetic Resonance (NMR) spectroscopy, Small-angle X-ray Scattering (SAXS), and single-molecule Förster Resonance Energy Transfer (smFRET) provide complementary data for validating and refining computational ensembles [51] [52].
- ENSEMBLE Approach: This method selects a subset of conformations from a large starting pool to achieve agreement with experimental data, effectively reweighting the ensemble based on experimental constraints [52].
Enhanced Sampling Techniques
Advanced sampling methods have been developed to address the limitations of standard MD simulations:
- Replica Exchange MD: This technique uses multiple replicas at different temperatures to enhance conformational sampling over energy barriers [50].
- Accelerated MD: Modifies the potential energy surface to reduce energy barriers between states, facilitating more rapid transitions [50].
- Metadynamics: Uses a history-dependent bias potential to encourage exploration of under-sampled regions of conformational space [50].
The following workflow illustrates the integrative approach for determining accurate conformational ensembles of IDPs:
Experimental Protocols
Maximum Entropy Reweighting Protocol
A robust, automated maximum entropy reweighting procedure for determining accurate atomic-resolution IDP ensembles involves the following steps [51]:
Perform Extended MD Simulations: Conduct all-atom MD simulations (e.g., 30 μs) using multiple state-of-the-art force fields (e.g., a99SB-disp, CHARMM22*, CHARMM36m) to generate initial conformational ensembles.
Calculate Experimental Observables: Use forward models to predict experimental measurements (NMR chemical shifts, SAXS profiles, etc.) from each frame of the MD ensemble.
Determine Restraint Uncertainties: Calculate the uncertainty (σ_i) for each experimental observable based on the variance of predictions across the unbiased ensemble.
Apply Maximum Entropy Principle: Optimize conformational weights to maximize the entropy of the final ensemble while satisfying experimental restraints, using the Kish effective sample size (K = 0.10) as the key parameter controlling ensemble size.
Validate Against Independent Data: Compare reweighted ensembles to experimental data not used in the reweighting process to assess transferability and prevent overfitting.
Integrative Modeling with Multiple Experimental Techniques
For the N-terminal region of Sic1 protein, the following protocol was employed [52]:
Sample Generation: Generate a large pool of conformations (e.g., 100 million) representing possible states of the IDP using computational methods.
Experimental Data Integration:
- Collect NMR data (chemical shifts, J-couplings, paramagnetic relaxation enhancements)
- Acquire SAXS data to inform on global dimensions
- Perform smFRET measurements for end-to-end distance distributions
Ensemble Selection: Use the ENSEMBLE algorithm to select the smallest set of conformations that simultaneously agree with all experimental data within specified tolerances.
Cross-Validation: Validate final ensembles against data not used in the selection process to ensure physical relevance and avoid overfitting.
Research Reagent Solutions
Table 1: Essential Research Reagents and Computational Tools for IDP Ensemble Studies
| Item | Function/Application | Specifications |
|---|---|---|
| CHARMM36m Force Field | MD simulations of IDPs | Optimized for disordered proteins; includes CMAP corrections [50] |
| a99SB-disp Force Field | IDP simulations with disp water model | Provides balanced protein-water interactions [51] |
| SWM4-NDP Water Model | Polarizable water for Drude FF | Used with polarizable force fields; improves dielectric properties [53] |
| AMOEBA Polarizable FF | Polarizable force field | Includes electronic polarization effects [53] |
| GROMACS/NAMD/OpenMM | MD simulation software | Enable high-performance MD simulations on CPU/GPU hardware [53] [13] |
| DPC/CHAPSO Micelles | Membrane mimic systems | For studying membrane-associated IDPs [54] |
| Alexa Fluor 488/647 | smFRET dye pair | For single-molecule fluorescence measurements (R₀ = 52.2 Å) [52] |
Data Presentation and Analysis
Quantitative Comparison of Force Field Performance
Table 2: Comparison of Force Field Performance for IDP Conformational Ensemble Generation
| Force Field | Water Model | Strengths | Limitations | Representative IDPs Studied |
|---|---|---|---|---|
| CHARMM36m | TIP3P | Balanced secondary structure propensity; good for both folded and disordered proteins | May produce overly compact conformations in some cases | Aβ40, α-synuclein, ACTR [51] |
| a99SB-disp | a99SB-disp water | Accurate dimensions for disordered proteins; good agreement with SAXS data | Limited compatibility with standard water models | drkN SH3, PaaA2 [51] |
| CHARMM22* | TIP3P | Improved backbone dihedrals; better helix-coil balance | Older version with known limitations for IDPs | Historical comparisons [51] |
| Amber ff99SB-ILDN | TIP3P/TIP4P | Good for folded proteins; modified side-chain torsions | Less accurate for disordered states without modifications | Benchmark studies [50] |
| Drude Polarizable | SWM4-NDP | Includes electronic polarization; improved dielectric properties | Computational expensive; ongoing development | Small peptides and nucleic acids [53] |
Analysis of Conformational Properties
The mechanical and structural properties of IDP ensembles can be quantified using various analytical approaches:
- Radius of Gyration (Rg): Calculated from SAXS data to assess global compactness [52]
- End-to-End Distance (Ree): Derived from smFRET efficiency measurements [52]
- Secondary Structure Propensity: Analyzed using DSSP or similar algorithms applied to MD trajectories [51]
- Principal Component Analysis (PCA): Identifies essential collective motions from high-dimensional trajectory data [13]
- Free Energy Landscapes: Constructed from reaction coordinates to identify metastable states and transitions [50]
The relationship between experimental techniques and the structural information they provide for IDP ensemble validation is summarized below:
Applications in Materials and Mechanical Properties Research
The methodologies developed for studying IDP conformational ensembles have direct relevance to materials science and mechanical properties research:
Mechanical Behavior of Disordered Biomaterials
IDPs share fundamental characteristics with synthetic amorphous materials, making insights transferable:
- Structure-Property Relationships: Both IDPs and amorphous materials derive their mechanical properties from ensemble characteristics rather than specific atomic arrangements [55].
- Deformation Mechanisms: The study of mechanical responses in metallic glasses reveals similarities to how IDPs might respond to mechanical stress [55].
- Multi-scale Modeling Approaches: Techniques developed for simulating metallic nanoglasses can be adapted for large IDP systems and vice versa [50] [55].
Quantitative Mechanical Properties
MD simulations enable the calculation of specific mechanical properties relevant to both materials science and biological function:
- Stress-Strain Relationships: Can be computed from MD trajectories to evaluate mechanical strength and deformation behavior [13].
- Young's Modulus: Determined from the slope of stress-strain curves in the elastic deformation region [13].
- Yield Stress and Tensile Strength: Identified from stress-strain curves to characterize plastic deformation onset and maximum stress tolerance [13] [55].
The accurate determination of conformational ensembles for intrinsically disordered proteins represents a significant challenge at the intersection of structural biology, computational chemistry, and materials science. Integrative approaches that combine molecular dynamics simulations with experimental data through maximum entropy reweighting or similar methods have demonstrated substantial progress toward force-field independent ensemble determination. The protocols and methodologies outlined in this case study provide a framework for researchers to generate physically realistic conformational ensembles of IDPs, with applications ranging from fundamental biological inquiry to drug discovery and biomaterials design. Future developments in machine learning potentials, enhanced sampling algorithms, and multi-scale modeling promise to further bridge the gaps in current capabilities, ultimately enabling predictive modeling of IDP conformational ensembles and their functional interactions at unprecedented accuracy and scale.
Overcoming Computational Hurdles: Strategies for Efficient and Accurate Simulations
Molecular dynamics (MD) simulations are a powerful tool for investigating the mechanical properties of materials at the atomic level. However, a significant challenge is that conventional MD simulations can rarely sample the complete conformational space of complex systems within a practical simulation time, as they often become trapped in local energy minima [56]. Enhanced sampling techniques are thus critical for obtaining statistically meaningful results. This note details the application of two prominent methods—Replica Exchange Molecular Dynamics (REMD) and Gaussian Accelerated Molecular Dynamics (GaMD)—within the context of materials science research.
The core challenge in molecular simulations is overcoming high energy barriers that separate metastable states. Without enhanced sampling, simulations may never observe critical transitions, such as protein folding, peptide binding, or polymer rearrangement, on accessible timescales [56] [57]. Enhanced sampling methods circumvent this by modifying the sampling process to facilitate escape from these local minima.
Two primary philosophies exist: collective variable (CV)-based methods, which require a priori knowledge of the reaction coordinates, and CV-free methods, which do not. This protocol focuses on two powerful CV-free methods:
- Replica Exchange MD (REMD): Also known as parallel tempering, it runs multiple parallel simulations ("replicas") at different temperatures and periodically attempts to exchange configurations between them [56] [58].
- Gaussian Accelerated MD (GaMD): It adds a harmonic boost potential to the system's potential energy, effectively smoothing the energy landscape and lowering energy barriers [57] [59].
Table 1: Comparison of REMD and GaMD Techniques
| Feature | Replica Exchange MD (REMD) | Gaussian Accelerated MD (GaMD) |
|---|---|---|
| Core Principle | Exchanges configurations between parallel simulations at different temperatures [56]. | Adds a harmonic boost potential to smooth the energy landscape [57]. |
| Sampling Scope | Global exploration of conformational space. | Enhanced sampling of local transitions and barriers. |
| Key Requirement | Multiple parallel simulations (replicas); temperature ladder. | Calculation of boost potential parameters from a preliminary "search" run [59]. |
| Computational Load | High (scales with number of replicas). | Lower (single simulation after parameterization). |
| Free Energy Calculation | Direct from the ensemble. | Requires reweighting of the simulation trajectory [57]. |
| Best For | Systems with rough energy landscapes and multiple metastable states. | Targeting specific molecular events without predefined coordinates [59]. |
Replica Exchange MD (REMD): Protocol and Application
Theoretical Basis of REMD
In REMD, M non-interacting replicas of the system are simulated in parallel at different temperatures, ( T1, T2, ..., TM ). Periodically, an exchange between configurations of neighboring replicas (e.g., replica i at temperature ( Tm ) and replica j at temperature ( T_n )) is attempted. The swap is accepted with a probability given by the Metropolis criterion:
[ w(X \rightarrow X') = \min(1, \exp(-\Delta)) ]
where ( \Delta = (\betan - \betam)(V(q[i]) - V(q[j])) ), ( \beta = 1/k_B T ), and ( V(q) ) is the potential energy [56]. This probability ensures detailed balance is maintained in the generalized ensemble. The acceptance rule depends only on potential energies and temperatures, allowing higher-temperature replicas to cross barriers and sample broadly, while lower-temperature replicas provide a correct Boltzmann-weighted ensemble.
Detailed REMD Protocol for a Peptide Dimer System
The following protocol, adapted from a study of the hIAPP(11-25) peptide dimer, outlines the key steps for running a REMD simulation using GROMACS [56].
Initial Setup and Equilibration
- Construct the Initial Configuration: Use a tool like VMD to build the starting structure of your system (e.g., a peptide dimer in a solvation box) [56].
- Energy Minimization: Perform energy minimization to remove any steric clashes or inappropriate geometry in the initial structure.
- Conventional MD Equilibration: Run a short conventional MD simulation in the NVT (constant Number of particles, Volume, and Temperature) and NPT (constant Number of particles, Pressure, and Temperature) ensembles to equilibrate the system's density and temperature.
REMD Simulation Setup and Execution
- Generate Replicas: Create the necessary number of replicas, each with an identical starting structure but a different temperature. The temperature range and spacing should be chosen to ensure a sufficient exchange acceptance rate (typically 20-30%) [56].
- Prepare GROMACS Configuration Files: Create a
.tprfile for each replica. The key GROMACS.mdpparameters for a REMD run include:integrator = mdgen-vel = yesld-seed = -1exchange = ex(orsingledepending on the GROMACS version)
- Launch the REMD Simulation: Execute the REMD run using MPI for parallelization. For example:
The
-replexflag specifies the frequency (in steps) for attempting replica exchanges [56].
Data Analysis
- Analyze Replica Exchanges: Use tools like
gmx demuxto process the output log files and trace the trajectory of each temperature through replica space. - Free Energy Landscape Calculation: After "demuxing" the trajectories, combine data from the lowest-temperature replica and use the weighted histogram analysis method (WHAM) or similar techniques to construct free energy landscapes as a function of relevant reaction coordinates (e.g., root-mean-square deviation (RMSD), radius of gyration) [56].
Gaussian Accelerated MD (GaMD): Protocol and Application
Theoretical Basis of GaMD
GaMD enhances sampling by adding a harmonic boost potential, ( \Delta V(\vec{r}) ), to the system's original potential energy, ( V(\vec{r}) ), when ( V(\vec{r}) ) is below a threshold energy ( E ).
[ \Delta V(\vec{r}) = \frac{1}{2}k(E - V(\vec{r}))^2, \quad V(\vec{r}) < E ]
The modified potential becomes: [ V^*(\vec{r}) = V(\vec{r}) + \Delta V(\vec{r}) ] where ( k ) is the harmonic force constant [57]. The threshold energy ( E ) and force constant ( k ) are determined based on three enhanced sampling principles to ensure the boost potential is both effective and reweightable [59]. A key advantage is that the boost potential follows a near-Gaussian distribution, which allows for accurate reweighting of the simulation trajectory using cumulant expansion to the second order to recover the unbiased free energy landscape [57].
Detailed GaMD Protocol for Biomolecular Conformational Sampling
This protocol describes a flexible selective GaMD implementation, which allows boosting specific parts of a system (e.g., a ligand, a peptide, or a polymer chain) [59].
Parameterization via a "Search" Run
- Run a Short Conventional MD Simulation: Perform a nanosecond-scale conventional MD simulation of your system.
- Calculate GaMD Parameters: From the short simulation, calculate the maximum ( (V{max}) ), minimum ( (V{min}) ), average ( (V{avg}) ), and standard deviation ( (\sigmaV) ) of the system potential.
- Set the Threshold Energy ( E ) and Force Constant ( k ): The parameters are set to satisfy the condition ( V{max} \leq E \leq V{min} + 1/k ), where ( k \leq 1/(V{max} - V{min}) ). For example, one can set ( E = V{max} ) and ( k0 = (1/\sigmaV) \cdot k ), where ( k0 ) is a dimensionless constant between 0 and 1 [59]. This "search" run provides the initial parameters for the accelerated production simulation.
Production GaMD Simulation
- Define Acceleration Regions (for Selective GaMD): For complex systems, define specific atom groups to which the boost potential will be selectively applied. This is crucial for studying processes like ligand binding or polymer-surface interactions.
- For ligand binding, define one group for the ligand and another for the protein/polymer binding site [59].
- The code automatically splits the potential energy into bonded terms, nonbonded self-energies, and interaction energies between the defined groups.
- Configure and Run GaMD: Use the parameters from the search run to configure the production GaMD simulation. The simulation can be run using implemented modules in software like GROMOS [59] or other packages such as AMBER and NAMD.
Trajectory Reweighting and Analysis
- Reweight the Simulation: Use the boost potential statistics recorded during the simulation to reweight the trajectory. The
pyreweighttool suite can be used for this purpose, applying cumulant expansion to the second order to recover the unbiased free energy [59]. - Calculate Free Energy Landscapes: Project the reweighted probabilities onto relevant reaction coordinates (e.g., dihedral angles, distances) to construct free energy landscapes and identify metastable states and transition barriers.
Successful implementation of enhanced sampling simulations relies on a suite of specialized software and hardware.
Table 2: Key Research Reagents and Computational Tools
| Tool / Resource | Function / Purpose | Example / Note |
|---|---|---|
| MD Simulation Engine | Core software for performing energy minimization, equilibration, and production MD/REMD/GaMD runs. | GROMACS [56], AMBER, NAMD, GROMOS (for GaMD) [59]. |
| High-Performance Computing (HPC) Cluster | Provides the parallel computing power required for running multiple, long-timescale simulations. | Typically requires multiple cores per replica for REMD; equipped with Intel Xeon CPUs or GPUs [56]. |
| Visualization & Analysis Software | Used for system setup, trajectory visualization, and analysis of results. | VMD (Visual Molecular Dynamics) [56]. |
| Message Passing Interface (MPI) Library | Enables communication between parallel processes in REMD and GaMD simulations. | Standard MPI library (e.g., OpenMPI, MPICH). |
| Reweighting Toolkit | A script or software package for reweighting GaMD trajectories to recover unbiased free energies. | pyreweight tools [59]. |
Workflow Visualization
The following diagram illustrates the logical workflow and key decision points for applying REMD and GaMD, helping researchers select and implement the appropriate technique.
Molecular dynamics (MD) simulations are an indispensable tool for researching the mechanical properties of materials, yet they have long been constrained by a fundamental trade-off [60]. Traditional empirical potentials offer speed but lack the accuracy for modeling complex reactive processes, while first-principles methods like density functional theory (DFT) provide high accuracy at a computational cost that prohibits large-scale or long-time simulations [2] [61]. Machine-learned potentials (MLPs) have emerged as a transformative solution, using machine learning to interpolate pre-computed quantum mechanical data and thereby achieving near-first-principles accuracy with the computational efficiency of classical force fields [2] [60] [61]. This paradigm shift is creating new opportunities for accurate material property prediction and design within materials science and drug development. This document provides application notes and detailed experimental protocols for researchers integrating MLPs into their MD workflows for mechanical properties research.
Quantitative Performance Comparison of MLP Methodologies
The table below summarizes key performance metrics for different computational methods, illustrating the balance that MLPs strike between accuracy and speed.
Table 1: Comparative analysis of computational methods for molecular dynamics.
| Method | Computational Speed | Predictive Accuracy | Key Applicability | Data/Parameterization Effort |
|---|---|---|---|---|
| First-Principles (DFT) | Very Slow (Baseline) | Very High | Universal, but system size limited | Low human effort, high computation [60] |
| Traditional Empirical Potentials | Very Fast | Low to Medium | System-specific, limited reactivity | High human parameterization effort [60] |
| State-of-the-Art MLPs (e.g., NNPs) | Slow (orders faster than DFT) | High (DFT-level) | Broad for trained systems [2] | High computation for data generation [2] |
| Ultra-Fast MLPs (e.g., UF) | Very Fast (comparable to empirical) | Medium to High | Broad for trained systems [60] | Medium |
The performance of MLPs is quantitatively assessed by their error relative to DFT reference data. For instance, the EMFF-2025 potential for high-energy materials reports a mean absolute error (MAE) for energy within ± 0.1 eV/atom and for forces within ± 2 eV/Å across a wide temperature range [2]. Other ML models demonstrate similar precision, such as an MAE of 0.058 eV/atom for formation energy prediction [62]. For mechanical properties, MLPs have been shown to accurately predict elastic constants and simulate complex processes like the thermal decomposition of molecular crystals, achieving close agreement with experimental results [2] [60].
Table 2: Representative accuracy metrics of MLPs for specific material property predictions.
| Material System | MLP Model | Predicted Property | Accuracy / Error Metric | Reference Method |
|---|---|---|---|---|
| C, H, N, O-based HEMs | EMFF-2025 | Energy, Forces | MAE: ± 0.1 eV/atom, ± 2 eV/Å [2] | DFT |
| Inorganic Crystals | Deep Neural Network | Formation Energy | MAE: 0.058 eV/atom [62] | DFT (Materials Project) |
| Inorganic Crystals | Graph Convolutional Network | Band Gap | MAE: 0.388 eV [62] | Experiment/DFT |
Experimental Protocol: Developing and Validating a Specialized MLP
This protocol outlines the key stages for creating a general neural network potential, using the EMFF-2025 framework for high-energy materials (HEMs) as a template [2].
The following diagram illustrates the integrated, iterative workflow for developing a robust MLP.
Stage 1: Data Generation and Initial Sampling
Objective: To create a diverse and representative dataset of atomic configurations with corresponding DFT-level energies and forces.
Procedure:
- System Selection: Define the chemical space (e.g., elements C, H, N, O for HEMs).
- Initial Configuration Sampling:
- Collect a variety of relevant structures (molecular crystals, isolated molecules, surfaces, defect-containing cells).
- Perform ab-initio MD (AIMD) simulations at different temperatures (e.g., 300 K, 1000 K) to sample finite-temperature configurations.
- Use path-integral MD if nuclear quantum effects are significant.
- Apply stochastic methods to displace atoms from their equilibrium positions.
- Reference Calculations:
- Use a consistent DFT setup (functional, basis set/pseudopotential, convergence criteria) for all configurations.
- Compute and store the total energy, atomic forces, and stress tensors for each configuration.
Stage 2: Model Training with a Transfer Learning Strategy
Objective: To train a neural network that maps atomic configurations to their potential energy.
Procedure:
- Model Architecture Selection: Choose a suitable MLP architecture (e.g., Deep Potential (DP) [2], Moment Tensor Potential (MTP) [60], or Atomic Cluster Expansion (PACE) [60]).
- Leverage Pre-trained Models:
- Start with a broadly pre-trained model (e.g., DP-CHNO-2024 for C/H/N/O systems [2]).
- This provides a robust initial set of weights, reducing the required system-specific data.
- Fine-Tuning:
- Use the dataset from Stage 1 to further train (fine-tune) the pre-trained model.
- The loss function ( L ) is typically a weighted sum: ( L = wE \cdot \text{MSE}(E^{\text{DFT}}, E^{\text{MLP}}) + wF \cdot \sumi \text{MSE}(\mathbf{F}i^{\text{DFT}}, \mathbf{F}_i^{\text{MLP}}) )
- Optimize weights ( wE ) and ( wF ) to balance energy and force accuracy.
Stage 3: Active Learning and Robustness Improvement
Objective: To iteratively improve the model's robustness and extrapolation capability by identifying and incorporating poorly predicted configurations.
Procedure:
- Run Exploratory MD: Perform large-scale MD simulations using the newly trained MLP on target systems (e.g., thermal decomposition of an explosive crystal).
- Identify Failure Modes: Use the DP-GEN framework or similar to monitor the simulation [2]. Configurations where the model is uncertain (e.g., high deviation in predicted energy/forces) are flagged.
- Incorporate New Data: Select the most uncertain configurations, compute their DFT-level energies and forces, and add them to the training dataset.
- Re-train Model: Return to Stage 2 and re-train the model with the expanded dataset. Repeat until model performance is stable and uncertainty is low across the relevant chemical space.
Stage 4: Model Validation and Property Prediction
Objective: To rigorously benchmark the final MLP against held-out DFT data and experimental observables.
Procedure:
- Static Property Validation:
- Energy/Force Accuracy: Predict energies and forces for a held-out test set of configurations. Calculate MAE and ensure it meets targets (e.g., energy MAE < 0.1 eV/atom [2]).
- Crystal Structure: Compare MLP-predicted lattice parameters, crystal densities, and cohesive energies with DFT and experimental values.
- Mechanical Property Validation:
- Elastic Constants: Deform the simulation box along different strain modes and use the MLP to compute the stress response. Calculate the full elastic constant matrix (Cij).
- Derived Properties: Compute the bulk modulus (K), shear modulus (G), and Young's modulus (E) from the elastic constants. Compare with experiment.
- Dynamic Process Validation:
- Thermal Decomposition: Simulate the material at high temperatures (e.g., 2000-3000 K). Analyze the decomposition pathways, reaction rates, and products.
- Comparison: Validate that the decomposition mechanism and final products match known experimental or high-level theoretical results [2].
Table 3: Key software and computational resources for MLP development and application.
| Tool / Resource | Type | Primary Function | Relevance to MLP Workflow |
|---|---|---|---|
| VASP, Quantum ESPRESSO | Electronic Structure Code | Generate reference data [60] | Performs DFT calculations for energies/forces in Stage 1. |
| DP-GEN | Software Framework | Active learning [2] | Automates the iterative exploration and data generation in Stage 3. |
| DeePMD-kit | MLP Code | Model training & inference [2] | Implements the Deep Potential architecture for Stages 2 & 4. |
| LAMMPS | MD Engine | Large-scale MD simulations [60] | Runs efficient MD using the trained MLP for validation and production (Stage 4). |
| UF3 | MLP Code | Ultra-fast linear potential [60] | Provides a very fast, interpretable B-spline-based MLP model. |
| MLIP | General Concept | Bridge DFT accuracy and MD speed [61] | The overarching methodology enabling high-fidelity, large-scale simulations. |
Machine-learned potentials have fundamentally altered the landscape of molecular simulation by breaking the traditional accuracy-speed trade-off. Through structured methodologies that leverage transfer learning, active learning, and rigorous validation, researchers can now develop robust potentials that provide DFT-level accuracy for large-scale systems and long time scales. The provided protocols and toolkit offer a practical foundation for integrating these powerful tools into research on the mechanical properties of materials, accelerating discovery in fields ranging from energetic materials to pharmaceuticals.
Molecular dynamics (MD) simulation is a pivotal tool in computational materials science and drug development for predicting the thermo-mechanical properties of materials and the behavior of biomolecules at the atomic level [15]. A critical choice in setting up these simulations is the treatment of the solvent environment. This application note examines the strategic selection between implicit and explicit solvent models, focusing on their impact on system size, simulation timescale, and the accuracy of predicted mechanical and thermodynamic properties within the context of materials science research. The core trade-off involves balancing computational cost against the physical fidelity required for specific research questions, such as predicting elastic properties, strength, and thermal behavior of polymer resins or nanomaterials [15] [63].
Core Concepts and Energetic Principles
Explicit Solvent Models
Explicit solvent models treat solvent molecules as individual entities, interacting with the solute via a molecular mechanics force field. This approach provides a high-resolution picture of solute-solvent interactions, capturing specific effects like hydrogen bonding, solvent structure, and bridging water molecules. However, this high resolution comes at a steep computational cost, as the solvent molecules contribute the vast majority of the system's degrees of freedom, drastically increasing the computational resources required [64] [65].
Implicit Solvent Models
Implicit solvent models approximate the solvent as a continuous medium, replacing explicit solvent molecules with a potential of mean force (PMF) [64]. This approach effectively averages out the solvent degrees of freedom, leading to a much simpler and computationally efficient system. The free energy of solvation (ΔGsol) in these models is typically decomposed into contributions from cavity formation (ΔGcav), van der Waals interactions (ΔGvdW), and electrostatic interactions (ΔGele) [64]: ΔGsol = ΔGcav + ΔGvdW + ΔGele
Popular implicit models include:
- SASA (Solvent-Accessible Surface Area): Models non-polar solvation contributions as being proportional to the atom's solvent-accessible surface area [64].
- Generalized Born (GB): Provides an approximate solution for the electrostatic contribution to solvation [64].
- Poisson-Boltzmann (PB): Offers a more rigorous, though computationally heavier, solution for the electrostatic interactions by numerically solving the PB equation [64].
Quantitative Comparison of Model Performance
The choice between solvent models has direct, quantifiable consequences on simulation setup and outcomes. The tables below summarize key comparative data.
Table 1: Computational Requirements and Sampling Characteristics
| Feature | Implicit Solvent Models | Explicit Solvent Models |
|---|---|---|
| Typical System Size | Solvent adds no/few degrees of freedom [64] | >90% of atoms are typically solvent [65] |
| Relative Simulation Speed | 10 to 50 times faster than explicit solvent [66] | Baseline (1x) |
| Sampling of Solvent Degrees of Freedom | Approximated via mean force potential [64] | Directly simulated, includes thermal fluctuations |
| Recommended Application Scope | Equilibration processes, isotropic/bulk solvent approximation [64] | Processes where specific solvent structure/slow relaxation is critical [65] |
Table 2: Accuracy and Practical Performance in Biomolecular Simulations
| Property | Implicit Solvent (Brownian Dynamics) | Explicit Solvent (DPD Method) |
|---|---|---|
| Final Nanoparticle Size/Structure | Similar to explicit solvent [65] | Similar to implicit solvent [65] |
| Diffusion Coefficient (D) | D ∝ M⁻¹ (Rouse behavior) [65] | D ∝ R⁻¹ (Stokes-Einstein relation) [65] |
| Aggregation Dynamics | Slows unphysically for larger nanoparticles [65] | Matches expected physical evolution [65] |
| Surface Area per Polymer | 2-4 times larger than experimental values [65] | Agrees well with experimental values [65] |
Table 3: Impact of MD System Size on Prediction Precision for an Epoxy Resin [15]
| Number of Atoms | Precision in Thermo-Mechanical Properties | Simulation Time |
|---|---|---|
| 5,265 | Lower precision, higher standard deviation | Fastest |
| 10,530 | Converging precision | Fast |
| 14,625 | Converging precision | Moderate |
| 20,475 | Converging precision | Slow |
| 31,590 | High precision | Slower |
| 36,855 | High precision | Slowest (but no significant gain over 31,590) |
Decision Framework and Selection Protocol
The choice between solvent models is not merely a technical preference but a strategic decision that dictates the feasibility and physical relevance of a simulation. The following workflow provides a guided path for researchers to select the appropriate model based on their scientific objective and computational constraints.
Detailed Experimental Protocols
Protocol A: Setting Up an Implicit Solvent Simulation for a Polymer System
This protocol is designed for efficiently simulating the thermo-mechanical properties of a polymer resin, such as an epoxy, using an implicit solvent model.
System Construction:
- Building and Cross-linking: Mix monomer units (e.g., DGEBF and DETDA in a 2:1 molar ratio) in a periodic simulation box. Use a protocol like REACTER in LAMMPS to simulate cross-linking reactions, specifying pre- and post-reaction templates, a bond formation cutoff distance (e.g., 7 Å), and a reaction probability [15].
- System Size: Aim for a system size of approximately 15,000 atoms to optimally balance precision and computational efficiency for properties like density, elastic modulus, and strength [15].
Energy Minimization and Equilibration:
- Minimization: Perform energy minimization using the conjugate-gradient method with tolerances for energy (10⁻⁴) and force (10⁻⁶ kcal/mol·Å) [15].
- Densification: Use a "fix/deform" command to gradually compress the low-density initial system to the target mass density (e.g., 1.20 g/cm³ for epoxy) in multiple stages [15].
- Annealing: Perform an annealing heat cycle (e.g., from 27°C to 227°C and back to 27°C) to relax residual stresses from densification [15].
- Ensemble Equilibration: Equilibrate the system in the NPT ensemble (constant Number of particles, Pressure, and Temperature) at the target temperature and pressure (e.g., 27°C and 1 atm) using a thermostat and barostat (e.g., Nose-Hoover) [15].
Property Prediction:
- Mechanical Testing: Perform uniaxial tensile or shear tests by applying a constant strain rate to the simulation box while maintaining zero pressure in the other directions.
- Analysis: Calculate the stress tensor from the virial theorem to plot stress-strain curves and derive properties like elastic modulus, peak stress, and flow stress [63].
Protocol B: Running an Explicit Solvent Simulation for a Biomolecular System
This protocol is suited for studying processes where specific solvent interactions are critical, such as protein-ligand binding or self-assembly.
System Construction:
- Solvation: Place the solute (e.g., a protein or block copolymer) in a periodic box and solvate it with explicit water molecules (e.g., TIP3P, SPC/E models). Ensure a sufficient buffer distance (e.g., >10 Å) between the solute and the box edge.
- Ion Addition: Add ions to neutralize the system's net charge and to achieve a physiologically relevant ionic concentration.
Energy Minimization and Equilibration:
- Minimization: Use steepest descent or conjugate gradient algorithms to relieve any steric clashes introduced during solvation.
- Equilibration: Conduct a multi-stage equilibration:
- NVT Ensemble: Equilibrate the system at the target temperature (e.g., 300 K) using a thermostat (e.g., Langevin, Nose-Hoover) for 100-500 ps.
- NPT Ensemble: Further equilibrate the system at the target temperature and pressure (1 atm) using a thermostat and barostat for 100-500 ps to achieve the correct solvent density.
Production Simulation and Analysis:
- Production Run: Run a production simulation, typically in the NPT or NVT ensemble, for a duration sufficient to sample the phenomenon of interest (nanoseconds to microseconds).
- Trajectory Analysis: Analyze the saved trajectories for properties of interest. For self-assembly studies, this may involve calculating the radius of gyration, solvent-accessible surface area, or diffusion coefficients. Note that explicit-solvent nanoparticles exhibit diffusion coefficients that follow the Stokes-Einstein relation, a more physically realistic behavior than in implicit solvent for these processes [65].
The Scientist's Toolkit: Essential Research Reagents and Software
Table 4: Key Software and Model Components for Solvent Modeling
| Tool Name | Type | Primary Function | Application Context |
|---|---|---|---|
| LAMMPS | MD Software | Large-scale atomic/molecular massively parallel simulator for materials modeling [15]. | Simulating polymer resins, nanomaterials, and employing cross-linking protocols [15]. |
| Gaussian | Quantum Chemistry | Models solvent effects via Self-Consistent Reaction Field (SCRF) methods [67]. | Calculating solvation free energies (ΔG) and electronic properties in solution [67]. |
| Q-Chem | Quantum Chemistry | Implements various implicit solvent models (PCM, SMD, SMx) with smooth potential energy surfaces [68]. | Geometry optimizations and ab initio MD in solution without discontinuities [68]. |
| IEFPCM | Implicit Solvent Model | A popular Polarizable Continuum Model using integral equation formalism [67] [68]. | Default SCRF method in Gaussian; provides a robust continuum electrostatics treatment. |
| SMD | Implicit Solvent Model | A continuum solvation model based on electron density of the solute [68]. | Recommended for calculating solvation free energies (ΔG) with high accuracy [67]. |
| SASA | Implicit Solvent Term | Computes non-polar solvation energy based on solvent-accessible surface area [64]. | Often used in conjunction with PB or GB to model cavity formation and van der Waals interactions. |
| REACTER | Cross-linking Algorithm | A LAMMPS protocol for simulating bond formation and molecular topology changes [15]. | Building realistic, cross-linked polymer networks for MD simulations [15]. |
Molecular dynamics (MD) simulations have long been the cornerstone of computational studies for exploring the structural and dynamic properties of biomolecules and materials at atomic resolution. Despite their widespread use, traditional MD simulations face significant challenges, particularly when applied to complex systems such as intrinsically disordered proteins (IDPs) or heterogeneous materials. The primary limitations include prohibitive computational costs for sampling rare events and inadequate force field accuracy, which can bias the simulated conformational landscape [69] [51].
The integration of artificial intelligence (AI) with MD simulations has emerged as a transformative paradigm to overcome these limitations. AI methods, particularly deep learning (DL), leverage large-scale datasets to learn complex, non-linear relationships, enabling efficient and scalable conformational sampling without being constrained by traditional physics-based approaches alone [69] [70]. This integration creates a powerful synergy: MD provides physically-grounded, atomic-level detail, while AI offers enhanced sampling efficiency and the ability to extract meaningful patterns from high-dimensional data. In the context of materials science, particularly for investigating mechanical properties, these hybrid approaches facilitate a more accurate and comprehensive exploration of conformational spaces, defect dynamics, and structure-property relationships that are critical for designing advanced materials [23].
This article outlines specific application notes and detailed protocols for implementing hybrid AI-MD approaches, providing researchers with practical methodologies to enhance their conformational sampling capabilities.
Application Notes
Key Methodological Frameworks
Table 1: Summary of Primary Hybrid AI-MD Methodologies
| Method Category | Core Function | Representative Tools/Studies | Demonstrated System Size | Key Advantages |
|---|---|---|---|---|
| AI-Driven Ensemble Emulators | Generative models trained on MD data to sample conformations directly | AlphaFlow [70], DiG [70], UFConf [70] | Up to 768 AA [70] | Statistically independent samples; fixed computational cost per sample |
| Coarse-Grained ML Potentials | Neural networks parameterizing the potential energy surface | Majewski et al. [70], Charron et al. [70] | Up to 189 AA [70] | Smoother energy landscape; faster dynamics than all-atom MD |
| Maximum Entropy Reweighting | Biasing MD ensembles to achieve optimal agreement with experimental data | Borthakur et al. [51] | 40-140 residues (IDPs) [51] | Force-field independent ensembles; integrates diverse experimental data |
| ML-Defined Collective Variables (CVs) | Using AI to identify optimal low-dimensional descriptors for enhanced sampling | AF2RAVE [70] | Up to 369 AA [70] | Automates the difficult task of CV discovery for complex transitions |
Performance and Applications
Hybrid methods have demonstrated superior performance in various domains. For instance, generative models like AlphaFlow and DiG have shown improved recall of conformational states observed in the Protein Data Bank (PDB) compared to static structure prediction tools, successfully modeling systems of up to 768 amino acids [70]. In the study of IDPs, a fully automated maximum entropy reweighting procedure successfully integrated extensive NMR and SAXS data with MD simulations, producing highly accurate conformational ensembles for proteins like Aβ40 and α-synuclein. Notably, for three out of five IDPs studied, ensembles derived from different MD force fields converged to highly similar distributions after reweighting, suggesting a path toward force-field independent structural characterization [51].
In materials science, ML-potentials have revolutionized the simulation of composite materials. For example, MD simulations of SiC/Al composites have provided atomic-level insight into the evolution of residual stresses and dislocation networks during cooling processes, which are critical for understanding mechanical properties like yield strength and fracture resistance [23]. The integration of AI can further accelerate such simulations by providing accurate potentials and guiding sampling toward critical defect states.
Experimental Protocols
Protocol 1: Maximum Entropy Reweighting of MD Ensembles for IDPs
This protocol describes how to refine MD simulations of Intrinsically Disordered Proteins (IDPs) using experimental data to obtain a more accurate conformational ensemble [51].
- Objective: To determine an accurate, atomic-resolution conformational ensemble of an IDP by reweighting an initial MD ensemble to match experimental NMR and SAXS data.
- Primary Materials/Software:
- MD Simulation Software: GROMACS, AMBER, or OPENMM for generating initial ensembles.
- Reweighting Code: The custom Python code available from
github.com/paulrobustelli/Borthakur_MaxEnt_IDPs_2024/[51]. - Experimental Data: NMR chemical shifts, J-couplings, residual dipolar couplings (RDCs), and SAXS profiles.
- System: Intrinsically disordered protein (e.g., Aβ40, α-synuclein).
Procedure:
- Generate Initial MD Ensemble: Perform long-timescale (e.g., 30 µs) all-atom MD simulations of the IDP using state-of-the-art force fields (e.g.,
a99SB-disp,Charmm36m). Extract a large set of conformations (e.g., ~30,000 frames) [51]. - Calculate Theoretical Observables: For each conformation in the MD ensemble, use forward models to calculate the theoretical values of all experimental observables (e.g., NMR chemical shifts, SAXS intensity).
- Define the Kish Ratio Threshold: Set a target for the effective ensemble size, typically using a Kish Ratio (K) threshold of 0.10. This ensures the final ensemble retains about 10% of the initial conformations with significant weight, balancing agreement with experiment and ensemble diversity [51].
- Perform Maximum Entropy Reweighting: Execute the reweighting algorithm to assign new statistical weights to each conformation in the MD ensemble. The algorithm iteratively adjusts weights to achieve the best agreement with the experimental data while maximizing the entropy of the distribution, using the Kish threshold as the sole major free parameter.
- Validation and Analysis:
- Validate the reweighted ensemble by checking its agreement with experimental data not used in the reweighting procedure.
- Analyze the structural properties of the reweighted ensemble, such as radius of gyration, secondary structure propensity, and contact maps.
- Compare ensembles derived from different force fields to assess convergence toward a force-field independent solution.
The workflow for this integrative approach is summarized in the diagram below:
Integrative Ensemble Determination Workflow
Protocol 2: Developing a Coarse-Grained Machine Learning Potential
This protocol outlines the steps for creating a transferable coarse-grained ML potential from all-atom MD data, enabling faster and broader exploration of conformational landscapes [70].
- Objective: To train a neural network potential that captures the potential of mean force of a system, allowing for efficient coarse-grained simulations that reproduce the behavior of more expensive all-atom simulations.
- Primary Materials/Software:
- All-Atom MD Engine: LAMMPS, OPENMM, GROMACS.
- Training Dataset: A diverse set of short all-atom MD trajectories for multiple proteins or materials systems.
- ML Potential Framework: Software implementing variational force-matching or a similar method.
- Coarse-Grained Simulator: A molecular dynamics code that can integrate the learned ML potential.
Procedure:
- Dataset Generation:
- Perform all-atom MD simulations for a diverse set of training systems (e.g., 12 fast-folding proteins or 50 CATH domains). For each system, run multiple short simulations (totaling ~200 µs per system) to sample a variety of conformational states [70].
- For each frame in the trajectories, extract the atomic coordinates and the corresponding instantaneous forces.
- Coarse-Graining Mapping: Define a mapping from all-atom coordinates to a reduced coarse-grained representation (e.g., one bead per amino acid located at the Cα atom).
- Neural Network Training:
- Train a deep neural network to predict the potential energy and forces in the coarse-grained representation.
- Use the variational force-matching method: the network is trained so that the forces it predicts for a coarse-grained configuration match the conditional expectation of the all-atom forces for that same configuration [70].
- Regularize the training to ensure the model generalizes to systems not in the training set.
- Validation:
- Run simulations using the trained ML potential on test systems (miniproteins or small complexes with low sequence similarity to the training set).
- Validate by comparing the resulting free energy landscapes, native structure stability, and folding pathways against reference all-atom MD simulations or experimental data.
- Production Simulation: Use the validated ML potential for enhanced sampling studies, free energy calculations, or to simulate large-scale conformational changes in proteins and complexes.
The process of developing and deploying a coarse-grained ML potential is visualized as follows:
Coarse-Grained ML Potential Development
The Scientist's Toolkit: Research Reagent Solutions
Table 2: Essential Software and Force Fields for Hybrid AI-MD Research
| Reagent / Tool Name | Type | Primary Function in Hybrid Research | Application Example |
|---|---|---|---|
| LAMMPS | MD Simulation Software | Highly flexible platform for running all-atom and coarse-grained simulations; supports custom potentials. | Simulating defect evolution in SiC/Al composites [23]. |
| Charmm36m | Molecular Force Field | Optimized for proteins, including IDPs; provides a physically accurate prior for reweighting/generative models. | Generating initial conformational ensembles for IDPs [51]. |
| a99SB-disp | Molecular Force Field | State-of-the-art force field known for accurate modeling of disordered proteins and folded globular proteins. | Benchmarking and generating initial MD ensembles [51]. |
| OVITO | Visualization & Analysis | Atomistic visualization and analysis, including dislocation analysis (DXA) in materials science. | Analyzing dislocation networks in composites [23]. |
| AlphaFlow/DiG | Generative AI Model | Diffusion-based generative models for sampling protein conformational ensembles conditioned on sequence. | Generating diverse protein conformations beyond training data [70]. |
| Maximum Entropy Reweighting Code | Analysis Algorithm | Integrative software for reweighting MD ensembles against experimental data. | Determining force-field independent IDP ensembles [51]. |
| Vashishta & EAM Potentials | Interatomic Potential | Describe atomic interactions in non-biological materials (e.g., Si-C, Al-Al) for MD simulations. | Simulating interfaces in metal-matrix composites [23]. |
In molecular dynamics (MD), "optimization" refers to the careful selection of simulation parameters to ensure computational efficiency, numerical stability, and physical accuracy. The choice of timestep for integrating Newton's equations of motion and the method for calculating interatomic forces are two foundational pillars of any MD simulation. Within the context of researching materials' mechanical properties, these choices directly influence the reliability of computed properties such as elastic moduli, stress-strain relationships, and deformation mechanisms. This note details established and emerging best practices for these critical parameters, providing structured protocols for researchers.
Timestep Selection and Optimization
The timestep (Δt) is the time interval used for the numerical integration of the equations of motion. A poorly chosen timestep can lead to energy drift, inaccurate dynamics, or catastrophic simulation failure.
Core Principles and Guidelines
The central principle is that the timestep must be small enough to resolve the highest frequency motions in the system. [71] A good rule of thumb is that the timestep should be at least an order of magnitude smaller than the period of the fastest vibration.
Table 1: Recommended Timesteps for Different System Types
| System Characteristics | Recommended Timestep (fs) | Rationale & Notes |
|---|---|---|
| Systems with heavy atoms only (e.g., Au) | 2 - 5 | The absence of high-frequency bonds (e.g., C-H, O-H) allows for larger timesteps. [71] |
| Standard systems (typical organic/materials) | 1 | A safe and common starting point for most systems without light atoms. [71] |
| Systems with light atoms (e.g., H) | 0.5 - 1 | The high vibrational frequency of bonds involving hydrogen necessitates a smaller timestep. [71] [72] |
| Using constraint algorithms (e.g., SHAKE, RATTLE) | 2 | Constraining bond vibrations involving H allows for a timestep of ~2 fs. [73] |
| Machine Learning Force Fields (MLFF) | 1.5 - 3 | For oxygen-containing compounds, ≤1.5 fs is recommended; for heavy elements like Si, up to 3 fs may be stable. [72] |
Practical Protocol: Establishing a Valid Timestep
Objective: To determine the largest, stable timestep for a new system. Principle: A valid timestep in the microcanonical (NVE) ensemble results in good long-term conservation of the total energy. [71]
Initial Setup:
- Begin with an energy-minimized structure.
- Assign initial velocities corresponding to the desired temperature.
- Select a candidate timestep based on Table 1 (e.g., 1 fs for a standard system).
NVE Equilibration Test:
- Run a short simulation (e.g., 10-50 ps) in the NVE ensemble using the candidate timestep.
- Do not use a thermostat, as it can mask energy drift.
Monitoring and Analysis:
- Plot the total energy (potential + kinetic) as a function of simulation time.
- A stable, flat profile with small fluctuations indicates a good timestep.
- A systematic upward or downward drift in the total energy signifies an unstable integration, requiring a smaller timestep.
Iterative Optimization:
- If the total energy is stable, incrementally increase the timestep (e.g., by 0.5 fs) and repeat the NVE test.
- The largest timestep that does not produce a significant energy drift is optimal for production runs.
Diagram 1: A workflow for empirically determining the maximum stable timestep for an MD simulation.
Force Calculation and Force Field Optimization
The force field comprises the functions and parameters that define the potential energy of a system, from which interatomic forces are derived. Its selection is paramount for achieving physically meaningful results.
Understanding Force Field Components
The total potential energy is typically a sum of bonded and non-bonded interactions: [74] ( U(\vec{r}) = \sum U{bonded}(\vec{r}) + \sum U{non-bonded}(\vec{r}) )
Bonded Interactions:
- Bond Stretching: ( V{Bond} = kb(r{ij} - r0)^2 ) (harmonic potential)
- Angle Bending: ( V{Angle} = k\theta(\theta{ijk} - \theta0)^2 ) (harmonic potential)
- Torsional Dihedral: ( V{Dihed} = k\phi(1 + \cos(n\phi - \delta)) ) (periodic potential)
Non-Bonded Interactions:
- van der Waals: Often modeled by the Lennard-Jones potential: ( V_{LJ}(r) = 4\epsilon [ (\frac{\sigma}{r})^{12} - (\frac{\sigma}{r})^{6} ] )
- Electrostatics: Modeled by Coulomb's law: ( V{Elec} = \frac{qi qj}{4\pi\epsilon0 \epsilonr r{ij}} )
Force Field Parameterization via Force Matching
Force matching is a powerful technique for deriving accurate classical force fields from ab-initio (e.g., DFT) reference data. [75]
Objective: To optimize force field parameters so that the forces from the classical MD simulation closely match those from a high-level reference calculation.
Table 2: Key "Research Reagent Solutions" for Force Field Development
| Item / Resource | Function in Optimization |
|---|---|
| Ab-initio MD (AIMD) Trajectory | Serves as the reference dataset, providing target forces and energies for a set of configurations. [75] |
| Parameter Optimization Algorithm | Minimizes the difference between classical and reference forces (the "loss function"). [75] |
| Training System | A representative, smaller system used to generate the initial force field parameter set. |
| Validation Properties | Macroscopic properties (e.g., radial distribution functions, vibrational spectra) not used in training, used to validate the force field's transferability. [75] |
Experimental Protocol: Automated Force Matching for Materials
Generate Reference Data:
- Perform a short ab-initio MD simulation (e.g., using DFT) of the material system. The simulation box should be large enough to capture relevant phonons and collective motions. [72]
- Extract and save the atomic positions and forces for hundreds or thousands of snapshots along the trajectory.
Define the Force Field Functional Form:
- Choose the mathematical expressions for the bonded and non-bonded terms (e.g., CHARMM, AMBER). [75]
Set Up the Optimization Loop:
- Initialize a set of guess parameters for the force field.
- For each snapshot in the reference dataset:
- Calculate forces using the current classical force field.
- Compute the loss function, typically the mean squared error (MSE) between the classical and reference forces: ( \text{Loss} = \frac{1}{N} \sum{i=1}^{N} | \vec{F}{i}^{\,ref} - \vec{F}_{i}^{\,FF} |^2 )
Iterate and Converge:
- Use an optimization algorithm (e.g., gradient descent) to adjust the force field parameters to minimize the loss function.
- Iterate until the force difference falls below a predefined threshold.
Validate the Force Field:
- Run a new, independent classical MD simulation using the optimized force field.
- Compare structural (e.g., RDF), dynamical (e.g., diffusion coefficient), and thermodynamic properties against the ab-initio reference or experimental data. [75]
Diagram 2: The force matching protocol for deriving classical force field parameters from ab-initio reference data.
Integrated Protocol for Materials Property Simulation
This protocol combines timestep selection and force field best practices for simulating the mechanical properties of a material, such as a metal-organic framework (MOF) or an alloy.
Workflow: From System Setup to Production Analysis
System Preparation:
- Build an orthogonal simulation cell of sufficient size to minimize self-interaction. The cell should be larger than twice the cut-off distance of the potential. [71]
- For non-equilibrium deformation simulations, ensure the cell shape and dimensions are compatible with the intended applied strain.
Force Field Selection:
- Option A (Established FF): Select a well-validated, literature force field for your material.
- Option B (Custom FF): If no suitable force field exists, employ the Force Matching protocol (Section 3.2) to develop one.
Energy Minimization:
- Use a steepest descent or conjugate gradient algorithm to relax the initial structure and remove any high-energy clashes.
Equilibration:
- Thermalization: Run an NVT simulation to heat the system to the target temperature. The Nose-Hoover thermostat is generally recommended for its reliable canonical sampling. [71] For materials under constant pressure, follow with an NPT simulation to adjust the density using a reliable barostat like MTK or Bernetti-Bussi. [71]
- Timestep Validation: Perform the NVE test (Section 2.2) during the final stage of equilibration to confirm timestep stability.
- Convergence Check: Monitor potential energy, density, and pressure until they stabilize around a steady average. [76]
Production Simulation:
- Execute a long simulation using the optimized timestep and validated force field.
- For mechanical properties, this may involve:
- Elastic Constants: Applying small strains and measuring the stress response.
- Stress-Strain Curves: Deforming the simulation box at a constant strain rate and calculating the resulting stress tensor.
Analysis and Validation:
- Calculate target properties (e.g., elastic moduli, yield stress) from the production trajectory.
- Always assess the convergence of calculated properties by checking if their running averages have reached a stable plateau. [76]
Ensuring Predictive Power: Validation Frameworks and Comparison with AI Methods
Molecular dynamics (MD) simulations provide unparalleled atomistic insight into the structural dynamics and mechanical properties of biological materials. However, the predictive power and quantitative accuracy of these simulations must be rigorously validated against experimental observables to ensure reliability, particularly in research focused on materials' mechanical properties. This protocol details methodologies for correlating MD simulation results with three key experimental techniques: Nuclear Magnetic Resonance (NMR) spectroscopy, Small- and Wide-Angle X-Ray Scattering (SAXS/WAXS). The integration of computational and experimental approaches enables researchers to construct and validate high-fidelity models of molecular behavior, which is crucial for applications in materials science and rational drug design.
Table: Key Experimental Techniques for MD Validation
| Technique | Spatial Resolution | Temporal Resolution | Key Validated Parameters | Applications in Materials Science |
|---|---|---|---|---|
| NMR | Atomic-level | Nanoseconds to milliseconds | Interatomic distances, dihedral angles, conformational dynamics, structural ensembles | Protein flexibility, ligand binding interactions, domain dynamics |
| SAXS/WAXS | Low to medium (1-100 nm) | Milliseconds to seconds | Radius of gyration (Rg), particle size and shape, ensemble properties | Global structural changes, aggregation states, material compaction |
| Mechanical Testing | Macroscopic to molecular | Seconds to hours | Stiffness, elasticity, rupture forces, stress-strain relationships | Polymer mechanics, nanomaterial strength, biomaterial durability |
Theoretical Foundation: The Critical Role of Validation
Molecular dynamics simulations model the time-dependent behavior of molecular systems, but their accuracy is fundamentally limited by the empirical force fields that describe interatomic interactions and the finite timescales accessible to computation. Experimental validation serves multiple critical functions in the simulation workflow, including force field selection, assessment of sampling adequacy, and verification of predicted physical properties.
The integration of MD with experimental data follows several established paradigms. First, experiments can provide quantitative validation of MD-generated ensembles, allowing researchers to select the most accurate force fields for their specific system [77] [78]. Second, experimental data can be used to refine structural ensembles through methods such as maximum entropy reweighting or Bayesian inference, improving agreement with observed measurements [79] [78]. Finally, the comparison can drive force field improvement, creating transferable parameters that enhance predictive capability for novel systems [78].
For materials mechanical properties research, this validation is particularly crucial as mechanical behavior often emerges from collective phenomena spanning multiple length and time scales, and subtle force field inaccuracies can propagate into significant errors in predicted material performance.
Experimental Protocols and Correlation Methodologies
Nuclear Magnetic Resonance (NMR) Spectroscopy
Protocol: NMR Data Collection for Proteins
Sample Preparation:
- Express and purify the protein of interest (e.g., using pET vector system in E. Rosetta2 cells) [80].
- For isotopic labeling, grow bacterial culture in minimal medium containing 15NH4Cl as sole nitrogen source and/or 13C-glucose as sole carbon source [80].
- Purify using affinity (Ni2+ HisTrap), gel filtration (Superdex75), and ion exchange (SP column) chromatography [80].
- Confirm purity and identity by SDS-PAGE and mass spectrometry.
- Concentrate to required NMR levels using Centriprep devices and exchange into NMR-compatible buffer.
Data Collection:
- Acquire standard 2D 1H-15N HSQC spectra for backbone assignment.
- Collect paramagnetic relaxation enhancement (PRE) data by introducing a paramagnetic spin label at specific sites (e.g., via cysteine mutation and spin-labeling) [80].
- Measure residual dipolar couplings (RDCs) in aligned media.
- Perform relaxation experiments (T1, T2, heteronuclear NOE) to characterize dynamics.
Protocol: MD-NMR Correlation Analysis
Structural Restraints from NMR:
- Convert PRE measurements into distance restraints for MD simulations (typically 15-25 Å range) [80].
- Use dihedral angles from chemical shift analysis (e.g., TALOS+) as restraints.
- Incorporate RDCs as orientation restraints during MD refinement.
Quantitative Comparison:
- Calculate theoretical NMR observables (chemical shifts, J-couplings, relaxation parameters) directly from MD trajectories using specialized software.
- Compute Pearson correlation coefficients between experimental and back-calculated NMR parameters.
- For multi-domain proteins with flexible linkers, analyze domain orientation distributions from MD and compare with PRE and RDC data [80].
Advanced Integration:
- Apply maximum entropy reweighting to adjust MD ensembles to match NMR data [78].
- Use Bayesian inference methods to derive structural ensembles consistent with both MD and NMR data [79].
Small- and Wide-Angle X-Ray Scattering (SAXS/WAXS)
Protocol: SAXS/WAXS Data Collection
Sample Preparation and Characterization:
- Purify protein or material to homogeneity using size-exclusion chromatography.
- Characterize oligomeric state via analytical ultracentrifugation or multi-angle light scattering.
- For temperature-dependent studies, use precise temperature control (e.g., 10°C and 30°C for lipid phase transitions) [79].
Data Collection:
- Perform SEC-SAXS to separate monodisperse particles from potential aggregates [79].
- Collect scattering data across a wide q-range (typically 0.01-5 nm⁻¹), covering both SAXS and WAXS regions [81].
- Measure matching buffer blank for background subtraction.
- Use standard samples (water, silver behenate) for calibration and q-range determination.
Data Processing:
- Subtract buffer scattering from sample scattering to obtain excess intensity I(q).
- Process data to obtain pair-distance distribution function P(r) and radius of gyration Rg using GNOM or similar software [79].
Protocol: MD-SAXS/WAXS Correlation Analysis
Theoretical Scattering Calculation:
- Use explicit-solvent methods to compute scattering profiles from MD trajectories, which eliminates free parameters associated with solvation layer modeling [81].
- Define a spatial envelope around the solute that encompasses all conformational states and the solvation layer [81].
- Calculate the excess scattering intensity I(q) using the equation:
I(q) = ⟨|Ã(q)|²⟩Ω − ⟨|B̃(q)|²⟩Ω
where Ã(q) and B̃(q) are Fourier transforms of the electron densities of the solution and pure solvent systems, respectively, and ⟨⟩Ω denotes orientational averaging [81].
Quantitative Comparison:
- Compute χ² values to quantify agreement between experimental and calculated profiles.
- Analyze Rg distributions from MD trajectories and compare with experimental values.
- For nanodisc systems, use molecular-constrained geometrical models with elliptical cross-sections to jointly analyze SAXS and SANS data [79].
Advanced Integration:
- Incorporate thermal fluctuations from MD simulations, which significantly improves agreement with experimental WAXS data [81].
- Use WAXS profiles to detect minor conformational rearrangements (e.g., loop flexibility changes or Rg variations <1%) [81].
Diagram Title: Workflow for Experimental Validation of MD Simulations
Correlation with Mechanical Testing
While the search results provide limited specific information about direct correlation between MD and mechanical testing, several principles can be extrapolated for materials mechanical properties research.
Nanoscale Mechanical Properties from MD:
- Calculate stress-strain relationships from steered MD simulations.
- Determine elastic moduli from fluctuations and deformation simulations.
- Predict rupture forces for molecular complexes and materials interfaces.
Experimental Correlation:
- Compare simulated mechanical properties with atomic force microscopy (AFM) measurements.
- Validate predicted rupture forces with single-molecule force spectroscopy.
- Correlate computed elastic moduli with bulk mechanical testing results.
The Scientist's Toolkit: Essential Research Reagents and Materials
Table: Essential Research Reagents and Computational Tools
| Category | Specific Examples | Function/Application | Implementation Notes |
|---|---|---|---|
| Force Fields | CHARMM36, AMBER, GROMOS | Define potential energy functions governing atomic interactions | CHARMM36 recommended for lipids; AMBER for nucleic acids; validate selection [80] [78] |
| MD Software | GROMACS, NAMD, AMBER | Perform molecular dynamics simulations | GROMACS offers cost-efficiency for most systems; requires GPU acceleration [82] |
| Analysis Tools | MDAnalysis, VMD, MDTraj | Process MD trajectories and calculate properties | MDAnalysis provides Python API for programmable analysis pipelines [83] |
| Experimental Integration | BME, EOM, ISD | Combine experimental data with MD simulations | BME (Bayesian Maximum Entropy) optimally balances simulation and experiment [79] |
| Specialized Reagents | 15NH4Cl, 13C-glucose, spin labels (TEMPOL) | Isotopic labeling and paramagnetic probes | Enable specific NMR experiments (PRE, relaxation) for dynamics studies [80] [82] |
Implementation Guide: Practical Considerations
Workflow Integration
Successful integration of MD with experimental validation requires careful planning and execution. Begin with system setup using the most appropriate force field for your specific material or biomolecule, considering recent validation studies. Perform sufficient sampling through conventional MD or enhanced sampling methods, then calculate experimental observables directly from the trajectory for comparison with real data.
The MDAnalysis Python library provides a robust framework for analyzing MD simulations, including RMSD calculations, hydrogen bond analysis, and distance measurements [83]. For integrative structural biology, combine data from multiple sources (NMR, SAXS, SANS) with MD simulations through Bayesian/maximum entropy approaches to derive conformational ensembles consistent with all available information [79].
Troubleshooting Common Issues
Poor Agreement with NMR Data:
- Ensure sufficient sampling of conformational space, particularly for flexible regions.
- Verify the accuracy of the forward model used to calculate NMR observables.
- Consider force field limitations and test alternative parameter sets.
Discrepancies in SAXS/WAXS Profiles:
- Use explicit solvent methods for scattering calculations to minimize free parameters [81].
- Incorporate thermal fluctuations, which significantly improve agreement with WAXS data [81].
- Check for systematic errors in buffer subtraction or concentration determination.
Limited Sampling of Relevant States:
- Employ enhanced sampling techniques for complex transitions.
- Extend simulation time or use replica-exchange methods.
- Validate convergence through multiple independent simulations.
Diagram Title: Troubleshooting Common MD Validation Issues
The rigorous validation of molecular dynamics simulations against experimental data is fundamental to establishing their predictive power for materials mechanical properties research. The protocols outlined herein for correlating MD with NMR spectroscopy and SAXS/WAXS scattering provide a robust framework for this essential validation process. By following these detailed methodologies—from sample preparation and data collection through quantitative analysis and integration—researchers can significantly enhance the reliability of their computational models. The resulting validated MD simulations offer profound insights into molecular-scale mechanical behavior, enabling the rational design of advanced materials with tailored mechanical properties. As force fields continue to improve and computational resources expand, this integrative approach will become increasingly central to materials discovery and development.
Within the broader thesis on molecular dynamics (MD) simulations for materials mechanical properties research, benchmarking the performance of modern computational tools is a critical endeavor. The accurate prediction of fundamental properties like the elastic modulus and the simulation of complex phenomena like phase transitions are cornerstones of computational materials design [35]. Traditional methods, such as Density Functional Theory (DFT), provide high accuracy but are often associated with prohibitive computational costs, especially for high-throughput screening or large-scale simulations [84]. The emergence of machine learning interatomic potentials (MLIPs) offers a promising alternative, bridging the gap between quantum-mechanical accuracy and classical simulation efficiency [85]. This document provides detailed application notes and protocols for benchmarking the performance of these advanced simulation methodologies in predicting elastic properties and phase transitions, framed for an audience of researchers, scientists, and professionals in materials science and related fields.
Quantitative Benchmarking of Elastic Property Prediction
The elastic modulus, particularly the Young's modulus, is a fundamental mechanical property that measures a material's stiffness. Accurate prediction of this and related properties is essential for applications ranging from structural engineering to battery systems [84]. Universal MLIPs (uMLIPs) have been developed to model a wide range of materials, but their performance in predicting elastic properties, which requires an accurate evaluation of the second derivatives of the potential energy surface, must be systematically validated [84].
A recent large-scale benchmark study evaluated four state-of-the-art uMLIPs—SevenNet, MACE, MatterSim, and CHGNet—against DFT reference data for nearly 11,000 elastically stable materials from the Materials Project database [84]. The performance was quantified using metrics like Mean Absolute Error (MAE) and Root Mean Square Error (RMSE) for key elastic constants and their derived mechanical parameters.
Table 1: Performance Benchmark of uMLIPs for Elastic Properties on a Large-Scale Dataset (n ≈ 11,000 structures) [84]
| uMLIP Model | Key Architectural Feature | Performance in Elastic Prediction | Computational Efficiency |
|---|---|---|---|
| SevenNet | Scalable EquiVariance-Enabled Neural Network | Achieved the highest accuracy in predicting elastic constants. | --- |
| MACE | Higher-order equivariant message passing with explicit many-body interactions | Balanced high accuracy with good computational efficiency. | High |
| MatterSim | Periodic-aware Graphormer backbone | Balanced high accuracy with good computational efficiency. | High |
| CHGNet | Graph neural network with embedded charge information via magnetic moments | Performed less effectively overall in this benchmark. | --- |
Table 2: Detailed Accuracy Metrics for uMLIPs on Elastic Constants (C₁₁, C₁₂, C₄₄) and Moduli (Bulk Modulus K, Shear Modulus G) [84]
| Property | SevenNet (MAE/RMSE) | MACE (MAE/RMSE) | MatterSim (MAE/RMSE) | CHGNet (MAE/RMSE) |
|---|---|---|---|---|
| C₁₁ | Best performance | Good performance | Good performance | Lower performance |
| C₁₂ | Best performance | Good performance | Good performance | Lower performance |
| C₄₄ | Best performance | Good performance | Good performance | Lower performance |
| Bulk Modulus (K) | Best performance | Good performance | Good performance | Lower performance |
| Shear Modulus (G) | Best performance | Good performance | Good performance | Lower performance |
Application Notes: Accuracy in Phase Transition Predictions
Beyond elastic properties, the prediction of phase stability and phase transitions is crucial for materials design, especially for high-entropy alloys (HEAs) [85]. Molecular dynamics simulations powered by MLIPs enable the efficient exploration of phase diagrams by capturing temperature-dependent thermodynamic properties.
Case Study: Ni-Re Binary System
The Ni-Re alloy system, relevant for high-temperature aerospace applications, features several phases, including FCCA1, HCPA3, and intermetallic compounds like D019 and D1a [85]. Benchmarking here involves using MLIPs to compute the phase diagram and comparing the results to established DFT (e.g., VASP) calculations and experimental data.
Protocol: Phase Diagram Benchmarking with PhaseForge Workflow
- Structure Generation: Use the Alloy Theoretic Automated Toolkit (ATAT) to generate Special Quasirandom Structures (SQS) for various phases (FCC, HCP) and intermetallic compounds (D019, D1a) across different compositions [85].
- Energy Calculation at 0 K: Relax the generated SQS and calculate their energies at 0 K using the MLIP model being benchmarked (e.g., Grace, SevenNet, CHGNet) [85].
- Liquid Phase Handling: Perform MD simulations on the liquid phase at different compositions to account for its free energy [85].
- Thermodynamic Modeling: Fit all the calculated energies (solid and liquid) using CALPHAD modeling within ATAT [85].
- Phase Diagram Construction: Construct the final phase diagram using software like Pandat [85].
- Validation & Benchmarking:
- Qualitative Comparison: Visually compare the topology of the MLIP-predicted phase diagram (phase fields, transition temperatures) with the DFT-based and experimental diagrams [85].
- Quantitative Classification: Use the Zero-Phase Fraction (ZPF) lines as classifiers. Define True Positive (TP), True Negative (TN), False Positive (FP), and False Negative (FN) regions for each phase field compared to the DFT ground truth. Calculate classification error metrics (e.g., accuracy, precision) to quantitatively evaluate the MLIP's performance [85].
Results Interpretation: In the Ni-Re case, the Grace MLIP captured most of the phase diagram topology successfully compared to VASP, though it predicted a lower peritectic temperature. SevenNet overestimated the stability of intermetallic compounds, while CHGNet showed large energy errors, leading to a phase diagram inconsistent with thermodynamic expectations [85]. This illustrates how phase diagram computation serves as an effective, application-oriented benchmark for MLIP quality.
Case Study: Cr-Ni Binary System and Mechanical Instability
This system presents a challenge due to the mechanical instability of FCC structures on the Cr-rich side and BCC structures on the Ni-rich side [85]. This tests an MLIP's ability to handle unstable regions, which is critical for accurate free-energy modeling.
Protocol: Handling Mechanically Unstable Structures
- Structure Generation & Relaxation: Generate BCC and FCC SQS structures across the composition range and relax them using the MLIP [85].
- Stability Assessment: Evaluate the relaxation magnitude for each SQS. A significant relaxation indicates mechanical instability. A common cutoff (e.g., 0.05) can be used to identify unstable structures [85].
- Energy Referencing: For the final CALPHAD fit, use the energies of mechanically stable SQSs. For unstable compositions (e.g., FCC Cr), use the inflection-detection energy derived from ab-initio calculations as a reference point to ensure thermodynamic consistency [85].
Experimental Protocols and Workflows
General Workflow for Benchmarking MLIPs
The following diagram outlines a generalized protocol for benchmarking the performance of interatomic potentials in predicting material properties, integrating workflows for both elastic properties and phase transitions.
Detailed Protocol: Predicting Elastic Constants with uMLIPs
This protocol details the steps for benchmarking uMLIPs against elastic properties, as performed in large-scale studies [84].
- Objective: To evaluate the accuracy and computational efficiency of selected uMLIPs in predicting the full elastic constant tensor and derived moduli for a wide range of crystal structures.
- Materials/Software:
- Reference Dataset: A curated set of crystal structures with known DFT-calculated elastic properties (e.g., from the Materials Project database). The benchmark should include a diverse set of elements (e.g., B, C, N, O, Li, Mg, transition metals) and crystal systems (cubic, tetragonal, orthorhombic, etc.) [84].
- uMLIPs: Pre-trained models of uMLIPs to be evaluated (e.g., SevenNet, MACE, MatterSim, CHGNet).
- Software Framework: A compatible software environment to run the uMLIPs, such as the respective model repositories or integrated materials simulation platforms.
- Procedure:
- Data Preparation: Download the CIF files and corresponding elastic property data (Cᵢⱼ, bulk modulus, shear modulus) for the benchmark dataset.
- Structure Optimization: For each structure in the dataset, perform a full structural relaxation using each uMLIP to find the ground-state configuration at zero pressure.
- Elastic Constant Calculation:
- For the relaxed structure, apply a set of small, finite strains (±δ) to the lattice.
- For each strain configuration, compute the resulting stress tensor using the uMLIP.
- The elastic constants (Cᵢⱼ) are obtained from the linear relationship between the applied strain and the computed stress, typically by fitting the stress-strain data.
- Moduli Calculation: Calculate the bulk modulus (K) and shear modulus (G) from the elastic constant tensor using established relationships (e.g., Voigt-Reuss-Hill average).
- Performance Metric Calculation: For each uMLIP and each property, calculate the MAE and RMSE against the DFT reference data across the entire dataset.
- Validation: Compare the calculated MAE and RMSE values across the different uMLIPs. The model with the lowest error metrics for the key elastic constants and moduli is considered the most accurate for this specific task [84].
This section details the key computational tools and resources essential for conducting benchmark studies on material properties.
Table 3: Essential Computational Tools for MD and MLIP Benchmarking
| Tool Name | Type | Primary Function | Relevance to Benchmarking |
|---|---|---|---|
| Universal MLIPs (uMLIPs) | Software Model | Provides near-DFT accuracy forces/energies for MD simulations at lower computational cost. | The core object of benchmarking; used to predict energies, forces, and stresses for property calculation [84] [85]. |
| Density Functional Theory (DFT) | Computational Method | Ab-initio calculation of electronic structure and material properties. | Provides the reference ("ground truth") data against which uMLIP predictions are validated [84]. |
| Materials Project Database | Online Database | Repository of computed properties for thousands of known and predicted materials. | Source of reference crystal structures and their DFT-calculated properties for benchmarking [84]. |
| ATAT (Alloy Theoretic Automated Toolkit) | Software Toolkit | Suite of tools for studying alloy thermodynamics, including SQS generation and cluster expansion. | Used in phase diagram workflows to generate representative disordered structures and perform thermodynamic integration [85]. |
| PhaseForge | Software Workflow | Integrated tool that incorporates MLIPs into the ATAT framework for phase diagram calculations. | Enables automated, high-throughput phase diagram prediction and serves as a benchmarking platform for MLIPs from a thermodynamics perspective [85]. |
| Special Quasirandom Structures (SQS) | Modeling Technique | Supercells that best mimic the perfectly random state of an alloy for a given size and composition. | Used to approximate the configurational disorder in alloys for energy and property calculations in phase stability studies [85]. |
| CALPHAD | Modeling Method | Computational approach to calculate phase diagrams by modeling thermodynamic properties. | The framework for integrating MLIP-calculated energies to construct multi-component phase diagrams [85]. |
The accurate prediction of conformational ensembles is a cornerstone of understanding biomolecular function, particularly for intrinsically disordered proteins (IDPs) that lack a fixed three-dimensional structure. For decades, Molecular Dynamics (MD) simulations have been the primary computational tool for this task, providing atomic-level insights based on physical principles. Recently, Artificial Intelligence (AI) and deep learning (DL) approaches have emerged as powerful alternatives, leveraging data-driven strategies to predict ensembles directly from sequence. This application note provides a comparative analysis of these paradigms, detailing their methodologies, applications, and protocols, framed within the broader context of materials and mechanical properties research for an audience of scientists and drug development professionals.
The following table summarizes the core characteristics of MD and AI methods for conformational ensemble prediction.
Table 1: Comparative Analysis of MD and AI Approaches for Ensemble Prediction
| Feature | Molecular Dynamics (MD) | AI/Deep Learning (AI/DL) |
|---|---|---|
| Fundamental Basis | Newtonian physics, empirical force fields [69] | Data-driven, statistical learning from large datasets [69] |
| Sampling Mechanism | Numerical integration of equations of motion; sequential trajectory [70] | Direct generation of statistically independent conformations [70] |
| Computational Cost | High (GPU-days for µs-scale simulations) [70] | Low (GPU-seconds to minutes for predictions) [70] |
| Timescale Challenge | Struggles with millisecond+ transitions and rare events [70] [69] | Bypasses explicit simulation timescales [70] |
| Atomic Resolution | Native, all-atom detail [51] | Varies; often coarse-grained or all-atom [70] |
| Force Field Dependence | High; accuracy limited by force field quality [51] | Independent of classical force fields [69] |
| Primary Strength | Physics-based interpretation; provides dynamical trajectories | High throughput and computational efficiency |
| Key Limitation | Computationally expensive, limited sampling [69] | Dependence on quality and breadth of training data [69] |
Methodologies and Experimental Protocols
Molecular Dynamics Simulation Protocol
MD simulations derive conformational ensembles from physical principles. The following protocol is adapted from recent studies on IDPs like Aβ40 and α-synuclein [51].
Table 2: Key Research Reagents and Computational Solutions for MD
| Item | Function/Description | Example Specifications |
|---|---|---|
| Protein Force Field | Defines potential energy and atomic interactions. | a99SB-disp, CHARMM36m, CHARMM22* [51] |
| Water Model | Solvents the protein and mediates interactions. | a99SB-disp water, TIP3P [51] |
| MD Software | Engine for running simulations. | GROMACS, AMBER, NAMD |
| System Builder | Prepares the solvated simulation box. | CHARMM-GUI, pdb2gmx (GROMACS) |
| Experimental Data (NMR, SAXS) | Used for validation and integrative refinement. | Chemical shifts, J-couplings, SAXS profiles [51] |
Step-by-Step Workflow:
System Setup:
- Initial Structure: Obtain a starting protein structure, which can be an extended chain or a structure predicted by tools like AlphaFold2.
- Force Field Selection: Choose a modern, IDP-optimized force field (e.g., CHARMM36m, a99SB-disp).
- Solvation: Place the protein in a simulation box (e.g., dodecahedron) and solvate it with an appropriate water model.
- Neutralization: Add ions (e.g., Na⁺, Cl⁻) to neutralize the system's charge and mimic physiological salt concentration.
Energy Minimization:
- Use a steepest descent or conjugate gradient algorithm to relieve steric clashes and high-energy contacts in the initial structure.
Equilibration:
- Perform a short simulation (typically < 1 ns) in the NVT ensemble (constant Number of particles, Volume, and Temperature) to stabilize the system temperature.
- Follow with a simulation in the NPT ensemble (constant Number of particles, Pressure, and Temperature) to stabilize the system density and pressure. Positional restraints are often applied to the protein backbone during these phases and gradually released.
Production MD:
- Run an unrestrained simulation for the desired timescale (microseconds for IDPs). Use a thermostat (e.g., Nosé-Hoover) and barostat (e.g., Parrinello-Rahman) to maintain constant temperature and pressure.
- Save atomic coordinates at regular intervals (e.g., every 100 ps) for analysis.
Integrative Refinement (Optional but Recommended):
- To improve accuracy and achieve force-field independence, integrate experimental data using a maximum entropy reweighting procedure [51].
- Calculate Observables: Use forward models to predict experimental observables (NMR chemical shifts, SAXS profiles) from each saved simulation frame.
- Reweighting: Apply a robust, automated algorithm to reweight the ensemble so that the averaged back-calculated observables match the experimental data, minimally perturbing the original simulation weights [51].
AI-Based Deep Learning Protocol
AI methods learn to generate conformational ensembles from data. The protocol below is representative of generative models like AlphaFlow and DiG [70].
Table 3: Key Research Reagents and Computational Solutions for AI
| Item | Function/Description | Example Specifications |
|---|---|---|
| Pre-trained Model | Core AI model for generating structures. | AlphaFlow, DiG, UFConf [70] |
| Training Data | Data used to train the model. | PDB, AlphaFold DB, MD datasets (e.g., ATLAS) [70] |
| Multiple Sequence Alignment (MSA) | Provides co-evolutionary information for conditioning. | Generated from sequence databases (e.g., UniRef) |
| DL Framework | Software environment for model execution. | PyTorch, JAX |
| Fine-tuning Datasets | Specialized MD data for improving ensemble diversity/accuracy. | Public MD trajectory sets [70] |
Step-by-Step Workflow:
Input Preparation:
- Sequence: Provide the amino acid sequence of the target protein.
- MSA Generation (if required by the model): Use the target sequence to query large sequence databases and generate a multiple sequence alignment. This MSA is processed by the model's internal architecture to extract evolutionary constraints.
Ensemble Generation:
- Conditional Sampling: For a generative model (e.g., a diffusion model), the process involves conditioning the model on the target protein's sequence and MSA, then sampling multiple, statistically independent conformations. This is a single forward pass through the network for each conformation.
- Diversity Promotion: Many models incorporate mechanisms to ensure the generated ensemble is diverse and not just a set of variations of a single, low-energy state.
Validation and Fine-Tuning (Advanced):
- Validation: Compare the generated ensemble against experimental data (NMR, SAXS) or metrics from long-timescale MD simulations (e.g., radius of gyration, secondary structure propensity).
- Fine-Tuning: To enhance physical realism and accuracy, models can be fine-tuned on MD simulation data of specific proteins or general MD datasets. This helps the AI learn physically plausible transitions and state populations [70].
Visualization of Workflows
The following diagrams illustrate the logical workflows for the MD and AI protocols described above.
MD Simulation and Refinement Workflow
AI-Based Ensemble Generation Workflow
The fields of MD simulation and AI are not mutually exclusive but are increasingly synergistic. MD provides physically detailed, dynamical data that can be used to train and validate more accurate AI models. Conversely, AI can serve as a powerful surrogate model, rapidly generating initial ensembles that can be refined with targeted MD simulations or experimental data. The future of conformational ensemble prediction lies in hybrid approaches that integrate the physical grounding of MD with the speed and scalability of AI [69]. For researchers focused on material properties or drug development, the choice between MD and AI depends on the specific question: MD remains invaluable for probing detailed mechanistic pathways and dynamics, while AI offers unparalleled efficiency for high-throughput screening and initial characterization.
Hybrid modeling represents a paradigm shift in computational science, strategically blending the rigorous principles of physics-based modeling with the adaptive, pattern-recognizing capabilities of data-driven approaches. In Molecular Dynamics (MD) simulations for materials mechanical properties research, this fusion addresses critical limitations inherent in using either method independently. Physics-based models, derived from first principles, provide excellent interpretability and stability but struggle with accuracy and computational expense as system complexity increases [86]. Conversely, purely data-driven models can establish deep mapping relationships between inputs and outputs yet often lack physical consistency and generalize poorly beyond their training data [87].
The core value of hybrid frameworks lies in their ability to leverage the complementary strengths of both paradigms. By integrating physical laws with data science, researchers can develop models that are not only predictive but also physically consistent, interpretable, and robust across diverse conditions [86]. This is particularly crucial in materials science and drug development, where understanding the fundamental mechanisms behind material failure, protein folding, or drug-target interactions is as important as predicting the outcome.
Fundamental Principles of Hybrid MD Frameworks
Core Components and Their Integration
Hybrid MD frameworks are constructed from three fundamental components whose integration creates a system greater than the sum of its parts:
- Physics-Based Foundation: This component encompasses the fundamental physical laws governing molecular interactions, typically expressed through force fields and classical mechanics equations. These first-principles models provide the foundational structure, ensuring predictions remain physically plausible [87].
- Data-Driven Adaptation: Utilizing machine learning (ML) and deep learning (DL) algorithms, this component learns complex, non-linear patterns and relationships from large datasets—either experimental or synthetic. It compensates for phenomena that are computationally prohibitive or poorly captured by simplified physical models [87].
- Fusion Mechanism: This is the strategic layer that integrates the first two components. The mechanism can range from using physical laws to inform ML model architecture to incorporating data-driven corrections into physical simulations. This fusion enhances generalizability, improves predictive accuracy where physics is incomplete, and maintains interpretability [86] [87].
Dominant Coupling Strategies in Hybrid Models
The fusion of physical and data-driven components can be achieved through several coupling strategies, which can be categorized based on how information flows between them. The following diagram illustrates three primary coupling architectures.
Table: Hybrid Model Coupling Strategies and Their Characteristics
| Coupling Strategy | Description | Key Advantage | Example Application in MD |
|---|---|---|---|
| Physics-Informed Input [87] | Outputs of a physical model serve as inputs to a data-driven model. | Leverages physical principles for feature generation, reducing the data needed for training. | Using a coarse-grained physics simulation to generate initial states for an ML model predicting protein folding pathways. |
| Output Integration [87] | Independent physical and data-driven model outputs are fused. | Combines interpretability of physics with the accuracy of data-driven patterns in complex regimes. | Using an Unscented Kalman Filter to fuse sensor data with first-principle models for real-time state prediction [86]. |
| Physics Model Enhancement [87] | Data-driven models learn correction terms for a physics-based model. | Maintains a physically consistent core while improving accuracy in specific conditions. | An ML model learns the error in a classical force field and provides corrections to improve energy calculations. |
Application Notes: Hybrid Frameworks in Action
Quantifiable Performance Metrics
The implementation of hybrid frameworks in MD simulations has demonstrated significant, measurable improvements across various performance metrics critical to research and development.
Table: Performance Metrics of Hybrid vs. Traditional Models in MD Applications
| Application Domain | Pure Physics-Based Model Limitation | Pure Data-Driven Model Limitation | Hybrid Model Improvement |
|---|---|---|---|
| Drug Discovery & Design [88] | Computationally expensive to screen large compound libraries; limited accuracy in binding affinity prediction. | Predictions may be physically implausible; poor generalizability to novel protein targets. | Increased hit rates in virtual screening; reduced failure rates in later-stage experimental and clinical trials. |
| Materials Engineering [88] [87] | Difficulty predicting macroscopic properties (e.g., strength, conductivity) from complex atomic interactions. | Requires massive, high-quality datasets that are costly to generate; lacks interpretability. | Faster prototyping cycles and optimized material performance by guiding synthesis with accurate, atomic-level insights. |
| Tool Wear Monitoring (TWM) [87] | Inaccurate prediction of tool wear due to complex, multi-mechanism coupling in real-world environments. | Fits trained data well but adapts poorly to unseen machining conditions or tool variations. | Enhanced model robustness and generalization, enabling accurate predictions in complex, real workshop conditions. |
Detailed Experimental Protocol: Enhancing a Force Field with ML
This protocol provides a step-by-step methodology for a "Physics Model Enhancement" strategy, where a machine learning model is trained to correct the potential energy surface of a classical, physics-based force field.
Objective: To improve the accuracy of a classical MD force field for predicting the mechanical properties of a polymer material by learning a quantum-mechanical correction term.
Workflow Overview:
Step-by-Step Methodology:
Reference Data Generation (Quantum Mechanics - QM):
- Action: Perform ab initio (e.g., Density Functional Theory) calculations on a diverse set of molecular configurations of the polymer. This set should cover a wide range of bond stretches, angle bends, and dihedral rotations relevant to mechanical deformation.
- Data Captured: For each configuration
i, record the high-fidelity QM energy,E_QM(i), and the atomic forces. - Tools: Quantum chemistry software (e.g., Gaussian, VASP, Quantum ESPRESSO). High-Performance Computing (HPC) resources are essential.
Target Variable Calculation:
- Action: For the same set of molecular configurations, calculate the potential energy using the classical force field (FF),
E_FF(i). - Calculation: Compute the target variable for the ML model: the energy difference
ΔE(i) = E_QM(i) - E_FF(i). ThisΔErepresents the error of the classical force field.
- Action: For the same set of molecular configurations, calculate the potential energy using the classical force field (FF),
Featurization:
- Action: Convert the raw atomic coordinates of each configuration into a suitable input feature vector for the ML model. This step is critical for capturing rotational and translational invariances.
- Method: Use a feature scheme such as:
- Symmetry Functions: Describe the chemical environment of each atom by radial (distances to neighbors) and angular functions.
- SOAP Descriptors: Smooth Overlap of Atomic Positions, a powerful descriptor for atomic environments.
- Output: A feature vector
X(i)for each configurationi.
Machine Learning Model Training:
- Action: Train a supervised ML model (e.g., Neural Network, Gaussian Process Regression) to learn the mapping
f(X(i)) → ΔE(i). - Protocol:
- Split the dataset (
X(i),ΔE(i)) into training, validation, and test sets (e.g., 70/15/15). - Train the model to minimize the loss between predicted
ΔE_MLand trueΔE. - Use the validation set for hyperparameter tuning and to monitor for overfitting.
- The final model quality is assessed on the held-out test set.
- Split the dataset (
- Action: Train a supervised ML model (e.g., Neural Network, Gaussian Process Regression) to learn the mapping
Hybrid Molecular Dynamics Simulation:
- Action: Integrate the trained ML model into the MD engine.
- Integration: The total potential energy in the simulation becomes:
E_Total = E_FF + E_ML. - Force Calculation: The forces on atoms are computed as the negative gradient of the total potential:
F_Total = -∇E_Total = F_FF + F_ML. This ensures energy conservation and correct dynamics. - Software: Custom modifications to MD packages like LAMMPS or GROMACS are typically required to call the ML model during force calculations.
Validation and Analysis:
- Action: Run hybrid MD simulations to predict macroscopic mechanical properties (e.g., Young's modulus, yield strength, stress-strain curves).
- Benchmarking: Compare the results against:
- Simulations using only the classical force field.
- Available experimental data from tensile tests or nanoindentation.
- Metrics: Quantify the percentage improvement in accuracy for key properties achieved by the hybrid model.
Successful implementation of hybrid MD frameworks requires a combination of computational tools, data sources, and theoretical knowledge.
Table: Essential Resources for Hybrid MD Research
| Category / Item | Function / Purpose | Examples & Notes |
|---|---|---|
| Simulation & Data Generation | ||
| MD Simulation Software | Engine for running physics-based simulations and integrating ML potentials. | LAMMPS, GROMACS, NAMD, OpenMM, AMBER [88]. |
| Ab Initio / QM Software | Generates high-fidelity reference data for training and validation. | VASP, Gaussian, Quantum ESPRESSO, CP2K [88]. |
| High-Performance Computing (HPC) | Provides the computational power for large-scale MD and QM calculations. | Cloud computing platforms are increasingly used to reduce hardware barriers [88]. |
| Data Management & Analysis | ||
| Multi-source Sensor Data | Provides real-world observational data for fusion and model calibration. | Cutting force, vibration, Acoustic Emission (AE) sensors; used for input and validation [87]. |
| Data Analysis Platforms | For processing, visualizing, and analyzing simulation and experimental data. | Python (Pandas, NumPy, Matplotlib), Jupyter Notebooks, R. |
| Machine Learning & Fusion | ||
| ML/DL Frameworks | Provides algorithms and environment for building and training data-driven models. | TensorFlow, PyTorch, Scikit-learn. |
| Physics-Informed ML Libraries | Specialized tools for embedding physical constraints into ML models. | NVIDIA SimNet, IBM Physics-Informed ML tools, MIT PDE-Net. |
| Fusion Algorithms | Core mathematical methods for combining model outputs or constraints. | Unscented Kalman Filter [86], Gaussian Process Regression with physical constraints [86], Variational Autoencoders (e.g., primaDAG) [86]. |
Molecular dynamics (MD) simulations have become an indispensable tool for researching the mechanical properties of materials, providing atomic-level insights that are often challenging to obtain experimentally. The accuracy of these simulations fundamentally hinges on the chosen simulation methods and the force fields that describe interatomic interactions. This application note provides a critical assessment of current simulation methodologies and force field parameterizations, framed within the broader context of a thesis on MD simulations for materials mechanical properties research. We present standardized protocols and community standards to guide researchers in selecting and validating appropriate computational approaches for their specific material systems, with a focus on achieving predictive accuracy for mechanical property characterization.
Critical Analysis of Force Fields
Traditional Force Fields
Classical force fields utilize mathematical functions parameterized against experimental data or quantum mechanical calculations to compute potential energy. Their accuracy varies significantly across different material systems and properties.
Table 1: Comparison of Traditional Force Fields for Material Property Prediction
| Force Field | Strengths | Limitations | Optimal Use Cases |
|---|---|---|---|
| GAFF [89] | Good balance of accuracy for organic molecules; broad applicability | Limited accuracy for transport properties like viscosity | General organic molecules in thermodynamic studies [89] |
| OPLS-AA/CM1A [89] | Accurate density prediction; good for organic liquids | Underestimates shear viscosity; charge scaling required | Systems where density fidelity is paramount [89] |
| CHARMM36 [89] [90] | High accuracy for biomembranes; extensively validated | Poor prediction of mutual solubilities in mixed systems | Biological membranes; lipid bilayers [89] [90] |
| COMPASS [89] | Accurate interfacial tension and solubility | Complex parameterization; lower computational efficiency | Interfacial systems and complex solutions [89] |
Specialized and Machine Learning Force Fields
For systems where traditional force fields are inadequate, specialized and machine learning-driven approaches have emerged.
Specialized Force Fields: For complex material systems like the unique lipids in the Mycobacterium tuberculosis membrane, general force fields fail to capture critical properties. The dedicated BLipidFF was developed using a modular parameterization strategy with quantum mechanical calculations at the B3LYP/def2TZVP level. This approach accurately describes properties such as tail rigidity and diffusion rates, which are poorly captured by GAFF, CGenFF, or OPLS [90].
Machine Learning Potentials (MLPs): Neural network potentials (NNPs) like the EMFF-2025 represent a significant advancement for complex systems such as C, H, N, O-based high-energy materials (HEMs). These potentials achieve density functional theory (DFT)-level accuracy in predicting structures, mechanical properties, and decomposition mechanisms while being computationally efficient for large-scale molecular dynamics simulations. The EMFF-2025 model was developed using a transfer learning approach, building upon a pre-trained model with minimal new DFT data, enabling high accuracy with reduced computational cost [2].
Standardized Validation Protocols
Protocol 1: Validation for Thermodynamic and Transport Properties
This protocol outlines the steps for validating a force field's ability to reproduce key experimental thermodynamic and transport properties, using a liquid system as an example [89].
Step-by-Step Workflow:
- System Construction: Build a simulation cell with a sufficient number of molecules (e.g., 3375 molecules) to minimize size effects and ensure reproducible properties.
- Equilibration: Perform equilibration in the isothermal-isobaric (NPT) ensemble at the target temperature and pressure (e.g., 1 atm) until the system density stabilizes.
- Production Run: Conduct a production simulation in the canonical (NVT) ensemble using the equilibrated density. A minimum of 50 ns is recommended for reliable property calculation.
- Property Calculation:
- Density: Calculate as the average system mass divided by volume over the production trajectory.
- Shear Viscosity: Compute using the Green-Kubo relation applied to the off-diagonal elements of the pressure tensor.
- Validation: Compare computed values against experimental data across a temperature range (e.g., 243-333 K). A force field is considered validated if density errors are <1% and viscosity errors are <15% [89].
Protocol 2: Validation for Mechanical Properties
This protocol is designed for validating simulations aimed at predicting mechanical properties of solid materials, such as polymers or composites [91] [62].
Step-by-Step Workflow:
- Model Construction: Build an atomistic model of the material system. For complex microstructures (e.g., honeycomb cores in composites), consider using homogenization techniques to derive equivalent macroscopic properties from a Representative Volume Element (RVE), significantly reducing computational cost [92].
- Equilibration: Equilibrate the system thoroughly in the NPT ensemble to achieve zero pressure and a stable equilibrium structure.
- Deformation Simulation: Apply a controlled strain rate (e.g., 0.0001-0.001 ps⁻¹) to the simulation box in the desired direction using the NPT ensemble with a barostat and thermostat.
- Stress Calculation: Calculate the stress tensor components throughout the deformation process using the virial theorem.
- Property Extraction: Plot the stress-strain curve and extract key mechanical properties:
- Elastic Modulus: Slope of the initial linear region of the stress-strain curve.
- Tensile Strength: Maximum stress value before failure [91].
- Validation: Compare predicted elastic modulus and tensile strength with experimental data from tensile tests or reliable literature values. For homogenized models, validate against analytical solutions or full-scale experimental bending tests [92].
The Scientist's Toolkit
Table 2: Essential Research Reagents and Computational Tools
| Tool / Reagent | Function / Description | Application Context |
|---|---|---|
| Quantum Mechanics (QM) Software | Provides reference data for force field parameterization and validation. | Charge derivation (e.g., RESP charges), torsion parameter optimization [90]. |
| Representative Volume Element (RVE) | A minimal volume representing the overall properties of a heterogeneous material. | Homogenization of complex structures (e.g., honeycomb cores) for efficient macroscale simulation [92]. |
| Neural Network Potential (NNP) | A machine-learning model trained on QM data to achieve QM accuracy at near-classical MD cost. | Simulating reactive processes and complex materials like high-energy materials (HEMs) [2]. |
| High-Throughput Screening | Automated workflow to run thousands of simulations for dataset generation. | Building large, consistent datasets for training machine learning models on formulation properties [93]. |
| Active Learning Framework | A machine learning strategy that iteratively selects the most informative data points for simulation. | Accelerating the discovery of optimal material compositions or formulations [93]. |
Integrated Workflows and Community Standards
Multiscale Modeling Framework
Integrating different simulation scales is crucial for accurately predicting macroscopic material properties from atomic interactions. A robust hybrid framework combines atomic-scale simulations with continuum mechanics [62].
This workflow allows for the efficient bridging of scales: electronic structure calculations inform machine learning potentials, which enable accurate and efficient MD simulations. The results of these atomistic simulations (e.g., stress-strain responses) can then be homogenized to provide parameters for continuum-level Finite Element analysis, which finally predicts the macroscopic mechanical behavior of the material [62].
Community Standards and Best Practices
- Force Field Selection: Prioritize specialized force fields (e.g., BLipidFF for bacterial lipids) over general ones for complex, non-standard systems. When using traditional force fields, conduct a thorough comparison to identify the best fit for the target properties [89] [90].
- MLP Development and Usage: For systems with complex reactive chemistry or where traditional force fields fail, consider developing or using pre-trained NNPs. Employ transfer learning strategies to adapt existing models to new systems with minimal data, as demonstrated by the EMFF-2025 potential [2].
- Validation and Reporting: Always validate simulation results against multiple experimental or high-level computational benchmarks. Key properties for validation include density, elastic moduli, and transport coefficients. Report all validation data and simulation parameters (e.g., box size, simulation time, force field version) transparently [89] [93].
- Embracing High-Throughput and Data-Driven Methods: Leverage high-throughput MD simulations to generate consistent, large-scale datasets for benchmarking and machine learning model training. Implement active learning frameworks to guide experimental efforts and efficiently explore vast design spaces, such as those of chemical formulations [93].
Conclusion
Molecular Dynamics simulations have firmly established themselves as an indispensable computational microscope, providing unprecedented atomic-level insights into the mechanical properties of a vast range of materials, from high-strength alloys to biomolecules central to drug discovery. The integration of machine learning, particularly through neuroevolution and other machine-learned potentials, is dramatically enhancing both the accuracy and efficiency of these simulations, overcoming longstanding challenges in sampling and computational cost. Hybrid frameworks that marry the physical rigor of MD with the pattern-recognition power of AI represent the forefront of this field, enabling more robust predictions of complex material behavior and biomolecular interactions. Future directions point toward increasingly multiscale and interactive simulations, the wider adoption of quantum-mechanical accuracy, and the continued refinement of force fields. For biomedical and clinical research, these advancements promise to accelerate rational drug design by more accurately predicting target dynamics and binding interactions, ultimately paving the way for novel therapeutics and a deeper understanding of biological mechanisms at the molecular level.
References
- 1. Molecular Dynamics Simulations and Drug Discovery - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC10705576/]
- 2. EMFF-2025: a general neural network potential for ... [https://www.nature.com/articles/s41524-025-01809-w]
- 3. Molecular Dynamics Simulations in Drug Discovery and ... [https://www.mdpi.com/2227-9717/9/1/71]
- 4. 2.12: Applications of Newton's Equations of Motion [https://phys.libretexts.org/Bookshelves/Classical_Mechanics/Variational_Principles_in_Classical_Mechanics_(Cline)/02%3A_Review_of_Newtonian_Mechanics/2.12%3A_Applications_of_Newton's_Equations_of_Motion]
- 5. Newtonian Mechanics and Numerical Integration [https://research.coe.drexel.edu/cbe/abramsgroup/msim/node23.html]
- 6. Molecular Dynamics Simulation [https://people.ece.cornell.edu/land/courses/ece5760/FinalProjects/s2022/pjm326_pm623_tji8/pjm326_pm623_tji8/index.html]
- 7. General-purpose machine-learned potential for 16 elemental ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11589123/]
- 8. Lennard-Jones Fluid Properties | NIST [https://www.nist.gov/mml/csd/chemical-informatics-group/lennard-jones-fluid-properties]
- 9. Accurate simulation of surfaces and interfaces of ten FCC ... [https://www.nature.com/articles/s41524-020-00478-1]
- 10. Efficient training of machine learning potentials for metallic ... [https://arxiv.org/html/2501.00589v2]
- 11. Development of a Neuroevolution Machine Learning ... [https://www.mdpi.com/2075-4701/15/1/48]
- 12. NEP89: Universal neuroevolution potential for inorganic ... [https://arxiv.org/html/2504.21286v1]
- 13. Molecular Dynamics Simulations for Materials and ... [https://matlantis.com/en/resources/blog/md-intro/]
- 14. MDCrow: Automating Molecular Dynamics Workflows with ... [https://arxiv.org/html/2502.09565v1]
- 15. Optimal Molecular Dynamics System Size for Increased ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11075082/]
- 16. Review of molecular dynamics simulation in extraction ... [https://www.sciencedirect.com/science/article/abs/pii/S0927025625004549]
- 17. Molecular dynamics — AMS 2025.1 documentation [https://www.scm.com/doc/AMS/Tasks/Molecular_Dynamics.html]
- 18. Molecular dynamics simulation study to evaluate ... [https://www.sciencedirect.com/science/article/abs/pii/S0927025623006729]
- 19. Using Machine Learning to Analyze Molecular Dynamics Simulations of Biomolecules - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC12147208/]
- 20. Available Instruments for Analyzing Molecular Dynamics Trajectories - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC4797681/]
- 21. Coupling of atomistic and continuum simulations using a ... [https://www.sciencedirect.com/science/article/abs/pii/S0021999103002730]
- 22. A mesoscopic bridging scale method for fluids and ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC3693461/]
- 23. Molecular Dynamics Simulation Study on the Cooling ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12387285/]
- 24. Molecular dynamics simulation study on structure and ... [https://www.sciencedirect.com/science/article/abs/pii/S0925838825041787]
- 25. A Continuum Mechanics-Based Hierarchical Framework [https://pmc.ncbi.nlm.nih.gov/articles/PMC2440431/]
- 26. Bridging scales - from Quantum Mechanics to Continuum ... [https://www.ltm.tf.fau.eu/research/material-mechanics/bridging-scales-from-quantum-mechanics-to-continuum-mechanics-a-finite-element-approach/]
- 27. Best CPU, GPU, RAM for Molecular Dynamics in 2024 ... [https://bizon-tech.com/blog/best-cpu-gpu-ram-for-molecular-dynamics?srsltid=AfmBOoq2dMD5SjEaK_EgKagWA6B8ANKGnYzK__9nGjnSk5-Q_YXldDYf]
- 28. Best CPU, GPU, RAM for Molecular Dynamics [https://www.sabrepc.com/blog/life-sciences/best-cpu-gpu-and-ram-for-md-workstation-server?srsltid=AfmBOoqcAWhiR0kGh3xh178hnDatJ_9KZXiDmA_8JyBZDjVjw1lW6oOW]
- 29. LAMMPS Molecular Dynamics Simulator [https://www.lammps.org/]
- 30. Achieving Scalable Parallel Molecular Dynamics Using ... [https://www.sciencedirect.com/science/article/pii/S0743731597914088]
- 31. Accelerating free energy exploration using parallelizable ... [https://chemrxiv.org/engage/chemrxiv/article-details/68311c2fc1cb1ecda01075e9]
- 32. BIOVIA Materials Studio [https://www.3ds.com/products/biovia/materials-studio]
- 33. Rowan | ML-Powered Molecular Design and Simulation [https://www.rowansci.com/]
- 34. Machine learning analysis of molecular dynamics ... [https://www.nature.com/articles/s41598-025-11392-1]
- 35. Molecular dynamics simulation for all - PMC - PubMed Central [https://pmc.ncbi.nlm.nih.gov/articles/PMC6209097/]
- 36. Protocol for Molecular Dynamics Simulations of Proteins [https://en.bio-protocol.org/en/bpdetail?id=2051&type=0]
- 37. Mechanism-Informed Prediction of γ-TiAl Alloy ... [https://www.sciencedirect.com/science/article/abs/pii/S2352492825021427]
- 38. Rapid and accurate predictions of perfect and defective ... [https://www.nature.com/articles/s41598-023-50893-9]
- 39. Research Status of Molecular Dynamics Simulation ... [https://www.mdpi.com/2072-666X/16/10/1185]
- 40. MS Maestro - Materials Science - Schrödinger [https://www.schrodinger.com/platform/products/ms-maestro/]
- 41. From complex data to clear insights: visualizing molecular ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11043564/]
- 42. Editorial: Understanding Protein Dynamics, Binding and ... [https://www.frontiersin.org/journals/molecular-biosciences/articles/10.3389/fmolb.2021.681364/full]
- 43. DynamicBind: predicting ligand-specific protein ... [https://www.nature.com/articles/s41467-024-45461-2]
- 44. Accelerated Molecular Dynamics Simulations of Ligand ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC5435230/]
- 45. A multiscale simulation approach to compute protein ... [https://chemrxiv.org/engage/chemrxiv/article-details/685a5ad83ba0887c3347dc85]
- 46. Exploring Protein–Ligand Binding-Affinity Prediction | Rowan [https://rowansci.com/blog/exploring-protein-ligand-binding-affinity-prediction]
- 47. Automatic intelligent multiscale simulation to predict ... [https://www.sciencedirect.com/science/article/abs/pii/S1359645425006457]
- 48. Complex strengthening mechanisms in the NbMoTaW ... [https://www.nature.com/articles/s41524-020-0339-0]
- 49. PyContact: Rapid, Customizable, and Visual Analysis of ... [https://www.sciencedirect.com/science/article/pii/S0006349517350518]
- 50. Advanced Sampling Methods for Multiscale Simulation of ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8533332/]
- 51. Determining accurate conformational ensembles of ... [https://www.nature.com/articles/s41467-025-64098-3]
- 52. Conformational ensembles of an intrinsically disordered ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9987321/]
- 53. Current Status of Protein Force Fields for Molecular ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC4554537/]
- 54. Experimental methods to study the structure and dynamics ... [https://www.sciencedirect.com/science/article/pii/S2665928X24000151]
- 55. Molecular dynamics simulation on the mechanical ... [https://www.frontiersin.org/journals/materials/articles/10.3389/fmats.2024.1355522/full]
- 56. Replica Exchange Molecular Dynamics [https://pmc.ncbi.nlm.nih.gov/articles/PMC6484850/]
- 57. Gaussian accelerated molecular dynamics (GaMD) [https://pmc.ncbi.nlm.nih.gov/articles/PMC8658739/]
- 58. Multiplexed-Replica Exchange Molecular Dynamics ... [https://www.sciencedirect.com/science/article/pii/S0006349503748978]
- 59. Flexible Gaussian Accelerated Molecular Dynamics to ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10536968/]
- 60. Ultra-fast interpretable machine-learning potentials [https://www.nature.com/articles/s41524-023-01092-7]
- 61. Machine learning interatomic potential: Bridge the gap ... [https://www.sciencedirect.com/science/article/pii/S2589004224008952]
- 62. Enhancing phase change thermal energy storage material ... [https://www.frontiersin.org/journals/materials/articles/10.3389/fmats.2025.1616233/full]
- 63. Molecular Dynamics Simulation Study of the Mechanical ... [https://www.mdpi.com/2571-9637/3/3/28]
- 64. Design and application of implicit solvent models in ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC4045398/]
- 65. A comparison of implicit - and explicit - solvent of... simulations [https://pubmed.ncbi.nlm.nih.gov/21528979/]
- 66. An Efficient Mean Solvation Force Model for Use in ... [https://www.sciencedirect.com/science/article/abs/pii/S0022283696901394]
- 67. SCRF [https://gaussian.com/scrf/]
- 68. 11.2 Chemical Solvent Models [https://manual.q-chem.com/5.3/topic_solvation.html]
- 69. Use of AI-methods over MD simulations in the sampling ... [https://www.frontiersin.org/journals/molecular-biosciences/articles/10.3389/fmolb.2025.1542267/full]
- 70. AI-based Methods for Simulating, Sampling, and Predicting ... [https://arxiv.org/html/2509.17224v1]
- 71. Molecular Dynamics - QuantumATK [https://docs.quantumatk.com/manual/technicalnotes/molecular_dynamics/molecular_dynamics.html]
- 72. Best practices for machine-learned force fields [https://www.vasp.at/wiki/index.php/Best_practices_for_machine-learned_force_fields]
- 73. Best Practices for Foundations in Molecular Simulations ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC6884151/]
- 74. Practical considerations for Molecular Dynamics - GitHub Pages [https://computecanada.github.io/molmodsim-md-theory-lesson-novice/aio/index.html]
- 75. Fast and efficient optimization of Molecular Dynamics force ... [https://www.sciencedirect.com/science/article/abs/pii/S1387181114003412]
- 76. Convergence and equilibrium in molecular dynamics ... [https://www.nature.com/articles/s42004-024-01114-5]
- 77. Integrating experimental data with molecular simulations to ... [https://www.sciencedirect.com/science/article/abs/pii/S0959440X22001828]
- 78. Integrating experimental data with molecular simulations to ... [https://arxiv.org/html/2207.08622v4]
- 79. Structure and dynamics of a nanodisc by integrating NMR ... [https://elifesciences.org/articles/56518]
- 80. Integrating NMR, SAXS, and Atomistic Simulations: Structure ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC5985006/]
- 81. Validating Solution Ensembles from Molecular Dynamics ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC4104061/]
- 82. Hyperpolarized NMR Combined with Quantum Mechanical ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12461679/]
- 83. T020 · Analyzing molecular dynamics simulations [https://projects.volkamerlab.org/teachopencadd/talktorials/T020_md_analysis.html]
- 84. Benchmarking Universal Machine Learning Interatomic ... [https://arxiv.org/html/2510.22999v1]
- 85. Machine learning potentials for alloys: a detailed workflow ... [https://www.nature.com/articles/s41524-025-01814-z]
- 86. Editorial: Hybrid modeling-blending physics with data [https://www.frontiersin.org/journals/mechanical-engineering/articles/10.3389/fmech.2025.1612929/full]
- 87. A Review of Physics-Based, Data-Driven, and Hybrid ... [https://www.mdpi.com/2075-1702/12/12/833]
- 88. Molecular Dynamics Simulation Software in the Real World [https://www.linkedin.com/pulse/molecular-dynamics-simulation-software-real-6faqf]
- 89. Force field comparison for molecular dynamics simulations ... [https://www.sciencedirect.com/science/article/abs/pii/S0167732224024061]
- 90. Development of force field parameters for the atomic ... [https://www.nature.com/articles/s42004-025-01722-9]
- 91. Atomistic molecular dynamics simulations of the tensile ... [https://www.sciencedirect.com/science/article/pii/S0927025625002095]
- 92. Homogenization Method for Modeling and Analysis of the ... [https://www.mdpi.com/1996-1944/18/16/3884]
- 93. Leveraging high-throughput molecular simulations and ... [https://www.nature.com/articles/s41524-025-01552-2]