Beyond the Timescale Barrier: Modern Strategies to Overcome Sampling Limits in Small Protein Simulations
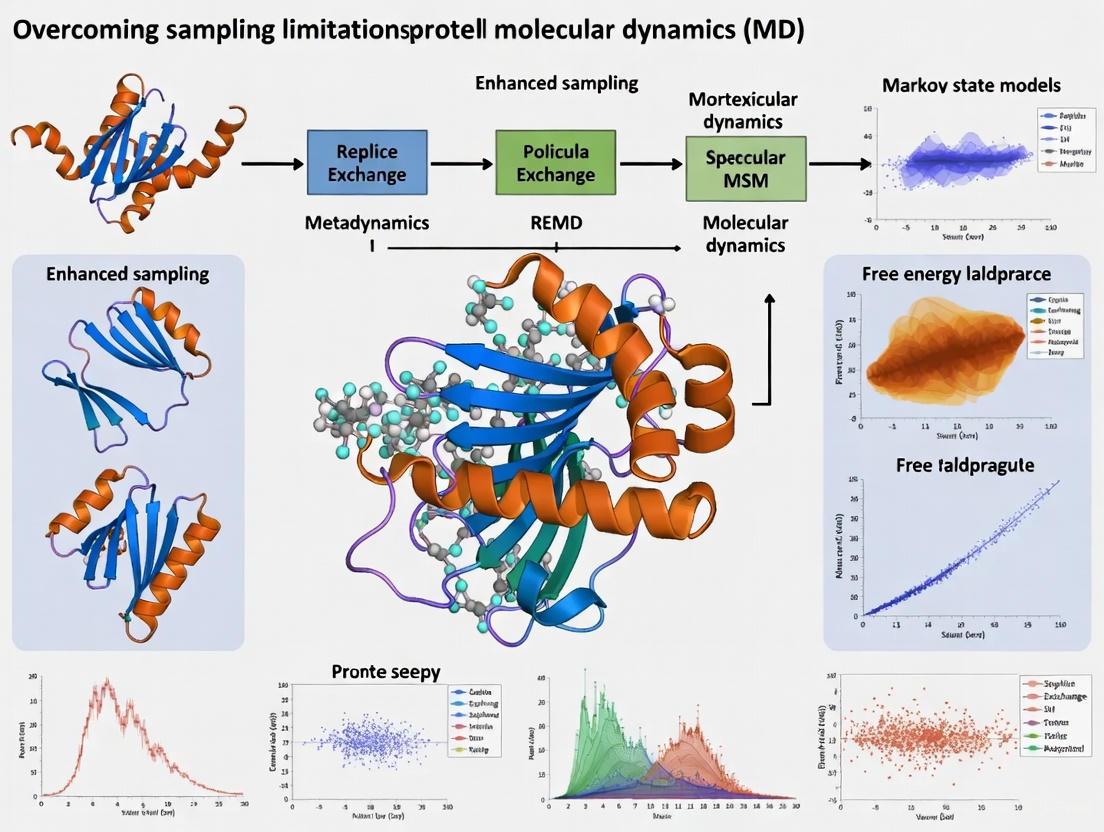
Molecular dynamics (MD) simulations are a cornerstone of structural biology and drug discovery, yet their utility is fundamentally constrained by the limited timescales accessible for sampling the conformational landscapes of...
Beyond the Timescale Barrier: Modern Strategies to Overcome Sampling Limits in Small Protein Simulations
Abstract
Molecular dynamics (MD) simulations are a cornerstone of structural biology and drug discovery, yet their utility is fundamentally constrained by the limited timescales accessible for sampling the conformational landscapes of small proteins. This article provides a comprehensive guide for researchers and drug development professionals on overcoming these sampling limitations. We explore the foundational challenges of rare events and energy barriers, detail cutting-edge methodological solutions including enhanced sampling algorithms and AI-driven generative models, and present best practices for troubleshooting and quantitative validation. By comparing the performance and applications of these diverse approaches, this review serves as a strategic roadmap for obtaining statistically robust and biologically meaningful insights from protein simulations, thereby accelerating therapeutic discovery.
The Sampling Problem: Why Small Proteins Challenge Conventional MD
Technical Support Center
Frequently Asked Questions (FAQs)
1. What is the primary cause of the "timescale dilemma" in molecular dynamics simulations? The core issue is that biomolecular motion is governed by rough energy landscapes with many local minima separated by high-energy barriers [1]. While the fundamental timestep of a simulation (the femtosecond) is sufficient to capture atomic vibrations, the functionally relevant conformational changes (such as protein folding or activation) often occur on microsecond to millisecond timescales or longer. This means that in a straightforward MD simulation, the system can become trapped in a non-functional state for an exceptionally long computational time, failing to sample all biologically important conformations [1].
2. My simulations are not converging. How can I enhance sampling of rare events? Lack of convergence often indicates insufficient sampling across energy barriers. You should consider implementing enhanced sampling algorithms. The choice of method depends on your system and the property you are studying [1]:
- Replica-Exchange MD (REMD): Well-suited for a broad range of systems, this method runs parallel simulations at different temperatures and exchanges configurations, facilitating escape from local energy minima [1].
- Metadynamics: This method is effective for exploring free-energy landscapes by adding a bias potential that discourages the system from revisiting previously sampled states. It is particularly useful when you can define a small set of collective variables that describe the process of interest [1].
- Adaptive Sampling: This approach involves running multiple short, unbiased simulations and then using data from those runs to seed new simulations from promising states. This can be guided by metrics like evolutionary coupling distances to efficiently sample pathways like receptor activation or protein folding [2].
3. How do I choose appropriate collective variables for metadynamics? Collective variables (CVs) should be descriptors of the essential slow degrees of freedom involved in the conformational change. Using a small set of physically meaningful CVs is critical for the success of metadynamics [1]. Recent methods also leverage evolutionary coupling information; distances between residues identified as evolutionarily coupled can serve as excellent, physically motivated reaction coordinates to guide sampling towards functional states [2].
4. What is the computational cost of these enhanced sampling methods? The cost varies significantly:
- REMD requires running multiple replicas simultaneously, which can be computationally prohibitive for large systems due to the high number of replicas needed [1].
- Metadynamics typically runs a single simulation but adds a computational overhead for managing the bias potential.
- Adaptive Sampling strategies, like Evolutionary Couplings-guided Adaptive Sampling (ECAS), can greatly reduce the time required to observe events like protein folding or activation by focusing computational resources on under-sampled regions of conformational space [2].
Troubleshooting Guides
Problem: Simulation is trapped in a single conformational state. Solution:
- Diagnose: Calculate the root-mean-square deviation (RMSD) over time. A flat, non-fluctuating RMSD profile indicates trapping.
- Implement REMD: This is a robust first choice for escaping local minima. Ensure you select an appropriate temperature range. The maximum temperature should be chosen slightly above the temperature where the folding enthalpy vanishes for optimal efficiency [1].
- Alternative - Use Metadynamics: If you have a good hypothesis for the reaction coordinate, apply metadynamics to "fill" the free energy well you are currently trapped in, encouraging the system to explore new areas [1].
Problem: Unable to observe a complete functional cycle (e.g., protein activation). Solution:
- Diagnose: Confirm you have a suitable starting structure and that your simulation time is theoretically sufficient (though it may not be practically feasible).
- Implement Path-Sampling Methods: Use adaptive sampling to iteratively explore the path to the active state. A specific protocol is outlined below:
- Step 1: Run an initial set of short, unbiased MD simulations.
- Step 2: For each simulation frame, calculate a score based on distances from a target functional state. The "change in the sum of evolutionary couplings pair distances (ΔSEC)" is a powerful metric for this [2].
- Step 3: Cluster the frames and select structures with the highest ΔSEC scores (i.e., those most different from the starting state) as starting points for the next round of simulations.
- Step 4: Repeat this process, building a Markov State Model (MSM) to understand the kinetics and identify the pathways of conformational change [2].
Problem: High computational cost of REMD for a large system. Solution:
- Consider Hamiltonian REMD (H-REMD): Instead of exchanging temperatures, run replicas with different Hamiltonians (e.g., different force field parameters). This can sometimes achieve similar sampling with fewer replicas [1].
- Use a Variant: Reservoir REMD (R-REMD) or multiplexed-REMD (M-REMD) can offer better convergence, though M-REMD has a high total computational cost [1].
- Switch Methods: For very large systems, generalized simulated annealing (GSA) can be a lower-cost alternative for characterizing flexible systems and large macromolecular complexes [1].
Experimental Protocols & Data
Quantitative Timescale Comparison
The table below summarizes the vast difference between the simulation timestep and the biologically relevant processes, creating the core "dilemma" [1] [3].
| Timescale | Unit (in seconds) | Relevant Molecular Process |
|---|---|---|
| Femtosecond | 1.0E-15 to 1.0E-12 s | Atomic bond vibrations; MD simulation timestep [1] [3]. |
| Picosecond | 1.0E-12 to 1.0E-9 s | Local side-chain motions; water dynamics. |
| Nanosecond | 1.0E-9 to 1.0E-6 s | Loop motions; helix formation. |
| Microsecond | 1.0E-6 to 1.0E-3 s | Allosteric transitions; small protein folding. |
| Millisecond | 1.0E-3 to 1.0E+0 s | Large-domain motions; enzyme catalytic cycles; protein-protein association. |
Detailed Method: Evolutionary Couplings-Guided Adaptive Sampling (ECAS)
This protocol is designed to efficiently sample rare conformational transitions using bioinformatic data [2].
I. Pre-Simulation Setup
- Calculate Evolutionary Couplings: Use a server like EVCouplings with the pseudolikelihood maximization method on a multiple sequence alignment of your protein's homologs to obtain a list of evolutionarily coupled residue pairs [2].
- Define a Reference State: Select a known functional structure (e.g., an active-state crystal structure) as your reference.
II. Adaptive Sampling Loop
- Initial Seeding: Begin with one or more starting structures (e.g., an inactive state).
- Run Parallel Simulations: Launch a set of multiple, short, unbiased MD simulations from your current set of structures.
- Analyze Trajectories and Calculate ΔSEC: For every saved frame in all trajectories, calculate the ΔSEC score:
- Compute the sum of distances between all evolutionarily coupled residue pairs identified in Step I.1.
- Subtract from this the same sum calculated for your reference state (from Step I.2). This gives the ΔSEC value for that frame.
- Select New Starting Structures: Cluster all frames from the current round of simulations based on their structural properties. From these clusters, select the frames with the highest ΔSEC values. These represent conformations that are most different from your reference in the evolutionarily informed degrees of freedom and are therefore prime candidates for seeding simulations that will explore new regions of conformational space.
- Iterate: Use the selected structures as the starting points for the next round of simulations (return to Step II.2). Repeat for several rounds.
III. Model Building and Analysis
- Construct a Markov State Model (MSM): Combine all simulation data from every round. Cluster the combined data to define discrete states, and then build an MSM to analyze the thermodynamics and kinetics of the processes you've sampled [2].
- Identify Pathways: Use the MSM to extract the dominant pathways connecting different functional states (e.g., from inactive to active).
Research Reagent Solutions
The table below lists key computational "reagents" for tackling sampling limitations.
| Item / Software | Function / Description |
|---|---|
| GROMACS | A high-performance MD software package that includes implementations of methods like REMD and metadynamics [1]. |
| NAMD | A parallel MD code designed for high-performance simulation of large biomolecular systems, also supporting enhanced sampling methods [1]. |
| Amber | A suite of biomolecular simulation programs with support for various REMD protocols and force fields [1]. |
| MSMBuilder | A software package for building and analyzing Markov State Models from MD simulation data [2]. |
| EVCouplings Server | A web platform for analyzing protein sequences and calculating evolutionary couplings to inform contact prediction and simulation guiding [2]. |
| Plumed | A plugin-like library that works with most MD codes to perform enhanced sampling simulations, including metadynamics and umbrella sampling. |
| Collective Variables (CVs) | Low-dimensional descriptors of slow processes (e.g., distances, angles, RMSD) used to bias simulations in methods like metadynamics [1]. |
Workflow and Pathway Visualizations
Troubleshooting Guides & FAQs
Frequently Asked Questions
Q1: My molecular dynamics simulation appears "stuck" in a single conformational state. What are my primary options to overcome this?
A: When a simulation is trapped in a metastable state, you have several enhanced sampling strategies at your disposal, each with different requirements and strengths. Biased MD methods, such as Metadynamics or Accelerated MD (aMD), modify the potential energy surface to encourage escape from energy wells [4] [5]. Alternatively, path-sampling approaches like Transition Path Sampling (TPS) or the Weighted Ensemble (WE) method focus computing power exclusively on the transition events themselves without introducing bias, generating an ensemble of transition pathways [6]. The choice depends on your goal: use biased MD for free energy landscapes or path sampling for mechanistic insights and rate constants.
Q2: How can I define a good Collective Variable (CV) for methods like Metadynamics, and what if I cannot find one?
A: A good CV should unambiguously distinguish between the initial, final, and transition states of your process [7]. It must be smooth and continuous, and it should capture the slowest dynamical modes of the transition. If identifying a single CV is challenging, consider machine learning approaches like the AMORE-MD or ISOKANN frameworks. These can learn a low-dimensional reaction coordinate directly from simulation data without requiring a priori knowledge of specific CVs [8]. Alternatively, for problems involving multiple simultaneous events (like bond dissociations), the Collective Variable-Driven Hyperdynamics (CVHD) method constructs a global CV from local structural variables, which is particularly useful for chemical reactions [7].
Q3: After running an accelerated simulation with a bias potential, my statistics seem distorted. How can I recover accurate thermodynamic information?
A: Recovering unbiased statistics from biased simulations is a crucial final step. For methods like Metadynamics and aMD, this is achieved through reweighting techniques. Each sampled configuration is assigned a statistical weight based on the applied bias potential (e.g., using the Boltzmann factor ( e^{\beta \Delta V} )), which allows you to reconstruct the canonical ensemble [4]. Be aware that the effectiveness of reweighting depends on the quality of your sampling and the magnitude of the bias; poor reweighting can lead to inaccurate free energy estimates.
Q4: What specific sampling challenges should I anticipate when performing free energy calculations on protein:protein complexes?
A: Protein:protein interfaces present distinct challenges due to complex networks of protein and water interactions [9]. Mutations, particularly those involving charge changes, often introduce severe sampling problems. Slow degrees of freedom that are specific to the mutation can lead to inadequate sampling. To overcome this, employ advanced techniques like alchemical replica exchange or alchemical replica exchange with solute tempering, and ensure simulations are sufficiently long to achieve convergence [9].
Troubleshooting Common Problems
| Problem | Symptoms | Potential Solutions |
|---|---|---|
| Insufficient Sampling | Simulation trapped in one state; non-ergodic behavior; poor convergence of free energy estimate. | 1. Apply Well-Tempered Metadynamics with a carefully designed CV [5].2. Use a path sampling method (e.g., Weighted Ensemble) to focus on transitions [6].3. Increase simulation temperature or use replica exchange [10]. |
| Poorly Chosen Collective Variable (CV) | The system transitions without the CV changing, or the CV changes without a meaningful transition. | 1. Employ interpretable deep learning (e.g., AMORE-MD) to discover a reaction coordinate [8].2. Use a set of preliminary short simulations to test and validate candidate CVs. |
| Inefficient Reweighting | Large statistical error in free energy estimates; biased ensemble averages. | 1. Use the Well-Tempered Metadynamics variant for more convergent reweighting [5].2. For aMD, consider the modified boost potential (ΔVc) to prevent oversampling of high-energy regions [4]. |
| High Energy Barriers in Protein Refinement | Inability to correct structural defects in predicted protein models; models rapidly unfold. | 1. Use flat-bottom restraints to prevent large unfolding while allowing local transitions [10].2. Initiate sampling from an ensemble of alternative initial models to explore broader conformational space [10]. |
Quantitative Data & Method Comparisons
Performance of Enhanced Sampling Methods
Table 1: Comparison of key enhanced sampling methodologies. This table summarizes the core principles, requirements, and outputs of different approaches to tackling rare events.
| Method | Core Principle | Required A Priori Knowledge | Primary Output | Key Reference |
|---|---|---|---|---|
| Metadynamics | Fills energy wells with a history-dependent bias potential to encourage escape. | Collective Variables (CVs) | Free Energy Surface (FES) | [5] |
| Accelerated MD (aMD) | Applies a non-negative boost potential to the potential energy surface, lowering barriers. | Boost energy (E) and acceleration parameter (α). | Accelerated trajectory, reweighted statistics. | [4] |
| Path Sampling (e.g., TPS, WE) | Samples ensembles of unbiased transition pathways between defined states. | Initial state (A) and final state (B). | Transition pathways, rate constants. | [6] |
| AMORE-MD / ISOKANN | Learns a reaction coordinate as a neural network membership function from simulation data. | None (learned from data). | Reaction coordinate, transition pathways, atomic sensitivities. | [8] |
Empirical Data on Method Effectiveness
Table 2: Documented success of various methods in simulating long-timescale biological processes. This data illustrates the practical application and achievements of these techniques.
| Method | Biological Process Simulated | Timescale Accessed | Key Achievement | Reference |
|---|---|---|---|---|
| Milestoning | Conformational change in HIV reverse transcriptase. | Millisecond | Calculated rate constants consistent with experimental data. | [6] |
| Weighted Ensemble (WE) | Outward-to-inward transition in sodium symporter Mhp1. | Long (biologically relevant) | Generated full pathways using coarse-grained simulations. | [6] |
| DIMS | Conformational transition in lactose permease transporter. | Long (biologically relevant) | Generated atomistic transitions in implicit solvent. | [6] |
| Well-Tempered Metadynamics | Conformational landscape of 2D macromolecules. | N/A | Identified metastable states (flat, fold, scroll) and mapped FES. | [5] |
Detailed Experimental Protocols
Protocol 1: Protein Model Refinement using Restrained MD
This protocol is designed to improve the accuracy of predicted protein structures by balancing the need for conformational sampling with the risk of unfolding [10].
Initial Model Preprocessing:
- Begin with your initial predicted protein structure.
- Use a tool like
locPREFMDto resolve stereochemical errors, including severe atomic clashes, incorrect cis-peptide bonds, and poor rotamer states.
System Setup:
- Solvate the preprocessed model in an explicit water box.
- Add ions to neutralize the system.
- Energy minimize the system to remove any remaining strains.
Equilibration:
- Gradually heat the system to the target simulation temperature (e.g., 300 K) under appropriate restraints on protein heavy atoms.
- Perform a short equilibration run in the NPT ensemble to stabilize system density.
Sampling with Restraints:
- Conduct production MD simulations using flat-bottom harmonic restraints applied to the protein's Cα atoms.
- Key Parameters: The flat-bottom potential allows unrestrained sampling within a defined radius (e.g., 2-3 Å) from the initial coordinates but applies a harmonic force beyond that, preventing large-scale unfolding while permitting necessary local rearrangements.
- Optional: To enhance sampling, the simulation can be run at a moderately elevated temperature (e.g., 400 K) in combination with the restraints [10].
Post-Sampling Analysis:
- From the sampled trajectory, select a sub-ensemble of low-energy structures using a scoring function (e.g.,
RWplus). - Compute an ensemble-averaged structure from the selected conformations.
- Perform a final local energy minimization on the averaged structure to correct minor stereochemical irregularities.
- From the sampled trajectory, select a sub-ensemble of low-energy structures using a scoring function (e.g.,
Protocol 2: Exploring Conformational Landscapes with Well-Tempered Metadynamics
This protocol uses Well-Tempered Metadynamics to map the free energy landscape of a molecule, such as a 2D macromolecule or a small peptide [5].
Collective Variable (CV) Selection:
- Identify one or two CVs that best describe the transition of interest. For 2D macromolecules, this could be a radius of gyration or a shape descriptor. For alanine dipeptide, the canonical CVs are the Ramachandran dihedral angles Φ and Ψ.
System Preparation:
- Build and solvate your molecular system.
- Equilibrate using a standard MD protocol to stabilize temperature and pressure.
Well-Tempered Metadynamics Simulation:
- Initialize the simulation from a structure in a metastable state.
- Configure the bias deposition:
- Gaussian Height: Initial energy of the deposited Gaussians.
- Gaussian Width: Determined by the expected fluctuation of your CV.
- Deposition Stride: Frequency (in simulation steps) for adding new Gaussians.
- Bias Factor: A key parameter that governs how quickly the Gaussian height is reduced as the FES is explored, ensuring convergence.
Convergence Monitoring:
- Run the simulation until the free energy estimate for the key metastable states no longer exhibits a systematic drift and fluctuates around a stable value.
- Monitor the time evolution of the CVs to ensure adequate transitions between states.
Free Energy Analysis:
- The free energy surface is calculated as ( F(s) = -\frac{1}{\gamma} V(s,t) ), where ( V(s,t) ) is the bias potential at time ( t ), and ( \gamma ) is related to the bias factor.
- Identify metastable states as deep minima on the FES and locate the transition states (saddle points) connecting them.
Method Workflow & Pathway Visualizations
Enhanced Sampling Method Selection Pathway
This diagram outlines a logical decision tree for selecting an appropriate enhanced sampling method based on the scientific question and available prior knowledge.
AMORE-MD Framework Workflow
This diagram illustrates the iterative, self-supervised workflow of the AMORE-MD framework, which connects deep-learned reaction coordinates to atomistic mechanisms [8].
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential software tools and computational methods for investigating rare events in molecular dynamics.
| Tool / Method | Primary Function | Key Application in Rare Events |
|---|---|---|
| ISOKANN Algorithm | Learns a neural membership function representing the dominant slow process (reaction coordinate) from simulation data. | Discovers reaction coordinates without requiring a priori knowledge of Collective Variables [8]. |
| AMORE-MD Framework | Enhances interpretability of deep-learned reaction coordinates via sensitivity analysis and minimum-energy pathways. | Connects machine-learned reaction coordinates to atomistic mechanisms [8]. |
| Well-Tempered Metadynamics | Accelerates transitions and computes free energy surfaces by depositing a history-dependent bias potential. | Explores complex conformational landscapes and identifies metastable states [5]. |
| Weighted Ensemble (WE) Path Sampling | Improves sampling efficiency by running multiple trajectories in parallel and strategically splitting/merging them. | Generates unbiased transition pathways and calculates rate constants for rare events [6]. |
| Collective Variable-Driven Hyperdynamics (CVHD) | Uses a self-learning bias on local CVs to accelerate dynamics, with on-the-fly time reweighting. | Simulates rare chemical reactions, such as bond-breaking events in pyrolysis [7]. |
| Modified aMD Boost Potential (ΔVc) | A boost equation that prevents oversampling of high-energy regions by defining an acceleration window. | Provides enhanced sampling with improved statistical recovery in explicit solvent [4]. |
Frequently Asked Questions
Q1: What are the primary molecular dynamics (MD) sampling challenges for Intrinsically Disordered Proteins (IDPs)? IDPs do not adopt a single stable structure but exist as dynamic ensembles of interconverting conformations. Their conformational space is vast, and sampling this diversity requires simulations spanning microseconds to milliseconds, which is computationally intensive. Traditional MD simulations often get trapped in local energy minima and struggle to sample rare, transient states that are crucial for biological function [11].
Q2: How do enhanced sampling methods like Replica-Exchange MD (REMD) address these challenges? REMD runs multiple parallel simulations (replicas) at different temperatures. Periodically, it attempts to exchange the system states between these replicas based on their energies and temperatures. This allows the system to overcome high energy barriers by simulating at higher temperatures, facilitating a more efficient random walk through conformational space and preventing trapping in local minima [1].
Q3: My simulations of a large disordered protein show an overly compact ensemble. What could be the issue? This is a known limitation of some force fields. While improved force fields like CHARMM36IDPSFF (C36IDPSFF) perform well for many disordered systems, they can still underestimate the radius of gyration (Rg) for larger IDPs. This indicates a potential force field inaccuracy in balancing intra-molecular interactions for larger systems, leading to overly compact conformations [12].
Q4: Are AI methods a viable alternative to MD for sampling conformational ensembles? Yes, AI and deep learning (DL) offer a transformative alternative. DL models can learn complex sequence-to-structure relationships from large datasets, enabling efficient generation of diverse conformational ensembles without the computational cost of physics-based MD simulations. They have been shown to outperform MD in generating ensembles with comparable accuracy, though they often depend on the quality of training data [11].
Q5: What is a key advantage of using metadynamics for studying protein folding or binding? Metadynamics enhances sampling by discouraging the revisiting of previously sampled states. It adds a history-dependent bias potential along predefined collective variables (e.g., root-mean-square deviation, number of native contacts), effectively "filling" free energy wells. This allows the system to explore new regions of the conformational landscape and helps in reconstructing free energy surfaces for processes like folding [1].
Troubleshooting Guides
Issue 1: Inadequate Sampling of Rare Events
Problem: Your simulation fails to observe a critical, functionally relevant conformational change that occurs on a timescale longer than your simulation can reach.
Solution:
- Implement Enhanced Sampling: Use methods like Gaussian accelerated MD (GaMD), metadynamics, or replica-exchange to help the system overcome energy barriers.
- Leverage AI-Generated Ensembles: Train or use existing deep learning models to generate initial conformational ensembles that include rare states, which can serve as starting points for more focused MD simulations [11].
- Extend Sampling with Hybrid Approaches: Combine AI and MD in a hybrid workflow. Use AI to rapidly explore conformational space and identify interesting states, then use MD to refine these states and validate their thermodynamic properties [11].
Issue 2: Force Field Inaccuracies for Disordered States
Problem: Simulated IDP ensembles are consistently too compact or too extended compared to experimental data (e.g., from SAXS or NMR).
Solution:
- Select a Specialized Force Field: Use force fields specifically parameterized for disordered proteins, such as CHARMM36IDPSFF, ff14IDPSFF, or a99SB-disp [12].
- Validate with Multiple Observables: Compare simulation results against a range of experimental data, including NMR chemical shifts, J-couplings, and SAXS profiles, not just a single metric like Rg [12].
- Test Force Field Compatibility: As demonstrated with C36IDPSFF, ensure the force field performs adequately for both disordered and folded domains if your system contains both [12].
Issue 3: High Computational Cost of Enhanced Sampling
Problem: Running a sufficient number of replicas for REMD or long enough bias deposition for metadynamics is computationally prohibitive for your system.
Solution:
- Optimize Replica Number and Placement: For REMD, carefully choose the temperature range and spacing. Using a maximum temperature too high can reduce efficiency. Tools like
temperature_generator.pycan help optimize replica placement [1]. - Use Variants like λ-REMD: For specific problems like absolute binding free energy calculations, Hamiltonian replica-exchange (H-REMD), where different replicas have different Hamiltonians, can be more efficient than temperature-based REMD [1].
- Start from AI-Predicted Structures: Reduce the necessary simulation time by starting from conformations generated by fast AI models, which may already be close to biologically relevant states [11].
Experimental Protocols & Data
Table 1: Enhanced Sampling Methods for Protein Simulations
| Method | Key Principle | Best Suited For | Key Considerations |
|---|---|---|---|
| Replica-Exchange MD (REMD) [1] | Parallel simulations at different temperatures exchange configurations, overcoming barriers. | Biomolecular folding, exploring rough energy landscapes. | Computational cost scales with system size (number of replicas). Efficiency sensitive to maximum temperature choice. |
| Metadynamics [1] | History-dependent bias potential "fills" free energy wells along collective variables. | Protein folding, conformational changes, ligand binding. | Requires careful selection of a small number of collective variables. Accuracy depends on the choice of these variables. |
| Simulated Annealing [1] | System is heated and then gradually cooled to find low-energy states. | Characterizing very flexible systems, large macromolecular complexes. | A variant, Generalized Simulated Annealing (GSA), can be applied to large systems at a relatively low computational cost. |
| AI/Deep Learning [11] | Learns sequence-to-structure relationships from large datasets to generate ensembles. | Efficiently sampling conformational landscapes of IDPs, generating diverse starting states. | Dependent on quality and source of training data. Limited interpretability. Hybrid approaches with MD are often beneficial. |
| System Type | Example Protein | Simulation Length | Number of Replicas | Key Observable Measured |
|---|---|---|---|---|
| Short Disordered Peptide | Ala5 | 1 μs × 5 | N/A | Conformational preferences |
| Disordered Protein | Aβ40 | 1 μs × 5 | N/A | Radius of gyration, NMR data |
| Fast-Folding Protein | Villin | 500 ns × 36 | 36 (REMD) | Folding stability |
| Folded Protein | GB3 | 1 μs × 1 | N/A | Structural stability, NMR data |
This protocol outlines the steps for evaluating the performance of a force field like CHARMM36IDPSFF on an intrinsically disordered protein.
System Setup:
- Initial Structure: Obtain or generate an extended conformation of the protein sequence.
- Solvation: Solvate the protein in a cubic water box (e.g., using TIP3P water model), ensuring a minimum distance between the protein and box edge.
- Neutralization: Add ions (e.g., Na⁺ or Cl⁻) to neutralize the system's net charge. Additional ions can be added to match physiological concentration.
Simulation Parameters (Based on GROMACS):
- Energy Minimization: Use the steepest descent algorithm (up to 50,000 steps) to remove steric clashes.
- Equilibration:
- Perform a 100 ps simulation in the NVT ensemble (constant Number of particles, Volume, and Temperature) using a velocity rescaling thermostat.
- Follow with a 100 ps simulation in the NPT ensemble (constant Number of particles, Pressure, and Temperature) using the Parrinello-Rahman barostat.
- Production MD:
- Run multiple (e.g., five) independent simulations of 1 μs each from different initial velocities to improve sampling and assess convergence.
- Use a 2 fs integration time step. Constrain covalent bonds involving hydrogen with the LINCS algorithm.
- Treat long-range electrostatics with the Particle Mesh Ewald (PME) method. Apply a 12 Å cutoff for both Coulomb and Lennard-Jones interactions.
Validation and Analysis:
- Conformational Analysis: Calculate the radius of gyration (Rg) and compare with experimental SAXS data.
- NMR Comparison: Compute NMR chemical shifts and scalar couplings (³J-couplings) from the simulation trajectory and compare directly with experimental NMR data.
- Convergence Check: Ensure that properties like Rg and secondary structure content have stabilized over the simulation time and are consistent across independent runs.
The Scientist's Toolkit: Research Reagent Solutions
| Item / Resource | Function / Purpose | Key Notes |
|---|---|---|
| Specialized Force Fields (e.g., CHARMM36IDPSFF, a99SB-disp) [12] | Provide empirical parameters for MD simulations that are tuned to accurately model both folded proteins and IDPs. | Corrects biases in standard force fields that often over-stabilize folded or compact states. Essential for realistic IDP ensembles. |
| Enhanced Sampling Algorithms (e.g., REMD, Metadynamics) [1] | Integrated into MD software to overcome energy barriers and sample rare events more efficiently. | Critical for studying processes like folding and large-scale conformational changes that are beyond the reach of standard MD. |
| AI/Deep Learning Models [11] | Generate conformational ensembles of IDPs efficiently by learning from data, bypassing expensive physics-based sampling. | Useful for rapid exploration and generating starting states. Performance depends on training data quality. |
| MD Software Packages (e.g., GROMACS, AMBER, NAMD) [1] | Provide the computational engine to run MD and enhanced sampling simulations. | Include implementations of key methods like REMD and metadynamics. GROMACS is noted for its performance and wide use. |
| Lab Notebook & Scripting (e.g., RMarkdown, Python, Shell scripts) [13] | Ensure reproducibility and organization of computational experiments. | A chronologically organized lab notebook (electronic or wiki) and driver scripts (e.g., runall) that record every operation are crucial. |
Workflow and Pathway Diagrams
Enhanced Sampling MD Workflow
AI-MD Hybrid Sampling Strategy
Frequently Asked Questions
1. What defines the "computational cost barrier" in protein simulation? The barrier arises from the fundamental constraints of Molecular Dynamics (MD), where the femtosecond timestep required for stability makes simulating biologically relevant timescales (microseconds to seconds) prohibitively expensive for standard computational resources. This limits the conformational sampling needed to observe large-scale protein folding and function [14].
2. My MD simulations are not sampling the full conformational landscape. What are my options? You can consider shifting to or supplementing with Monte Carlo (MC) methods, which have no inherent timescale and can more rapidly explore conformational space using simplified moves [14]. Alternatively, implement hybrid methods like MDeNM or ClustENMD that combine the atomic detail of MD with the sampling efficiency of coarse-grained models or normal mode analysis to accelerate exploration [15].
3. How does the choice between explicit and implicit solvent models impact computational cost and results? Explicit solvent models are computationally expensive because they simulate every water molecule, but provide high accuracy for solvent-involved interactions. Implicit solvent models are significantly faster and well-suited for Monte Carlo or enhanced sampling, but may have limitations such as over-stabilizing salt bridges or incorrect ion distribution [14].
4. What are the key metrics to validate that my sampling is adequate? Beyond achieving a low RMSD to a known native structure, you should analyze the free energy landscape to identify stable states and transition barriers. Compare your simulation's principal components (PCs) of structural change against ensembles of experimental structures. Good sampling should reproduce the known experimental conformational space [15].
5. How can I visually analyze and present large, complex simulation trajectories? Effective visualization is crucial for interpretation. While traditional frame-by-frame visualization is common, new challenges require leveraging web-based tools for accessibility, interactive visual analysis systems for high-dimensional data, and even virtual reality (VR) for an immersive exploration of complex dynamics [16].
Quantitative Comparison of Sampling Methodologies
The table below summarizes the core characteristics, resource requirements, and outputs of different sampling methods, helping you choose the right approach for your project.
| Method | Computational Demand | Key Input Parameters | Primary Output | Best Suited For |
|---|---|---|---|---|
| Molecular Dynamics (MD) [14] | Very High (constrained by femtosecond timestep) | Force field, timestep, simulation temperature & duration | Time-dependent trajectory of atomic coordinates | Studying precise kinetic pathways with explicit solvent. |
| Monte Carlo (MC) [14] | Lower (no inherent timescale) | Force field, number of MC steps, move sets | Thermodynamic ensemble of uncorrelated conformations | Efficiently sampling thermodynamic states and free energy landscapes. |
| Hybrid Methods (e.g., MDeNM, ClustENMD) [15] | Moderate | Number of normal modes, RMSD thresholds, short MD runs for refinement | Ensemble of full-atomic conformers covering transitions | Rapidly exploring large-scale cooperative motions at atomic resolution. |
Experimental Protocols for Enhanced Sampling
Protocol 1: All-Atom Monte Carlo Simulation for Protein Folding
This protocol uses the AMBER99SB*-ILDN force field with a Generalized Born implicit solvent model [14].
- System Setup: Obtain the initial protein structure (folded or unfolded) from a database like the PDB.
- Parameter Configuration:
- Force Field: AMBER99SB*-ILDN.
- Solvent Model: Generalized Born with a solvent accessible surface area (SASA) term for nonpolar solvation.
- Sampling: Set the number of MC steps (e.g., 200 million).
- Temperature: Run simulations over a wide temperature range (e.g., 330K–410K) to characterize folding/unfolding equilibria.
- Execution: Run the MC simulation on available computational nodes (e.g., an AMD EPYC node using 15-30 cores).
- Analysis:
- Calculate the free energy landscape as a function of reaction coordinates (e.g., RMSD, radius of gyration).
- Identify transition states and energy barriers.
- Determine per-residue stability across the sampled temperature range.
Protocol 2: Hybrid Sampling with ClustENMD
This method efficiently generates diverse conformers at atomic resolution [15].
- Conformer Generation: Deform the initial protein structure along its low-frequency normal modes (calculated using an Elastic Network Model) to create a large pool of candidate conformers.
- Clustering: Group the generated conformers based on structural similarity (e.g., using RMSD) to identify unique representative structures.
- Refinement: Run short, all-atom MD simulations (with implicit or explicit solvent) for each cluster representative to relax and refine the structures, removing steric clashes and incorporating atomic-level details.
- Validation: Compare the final ensemble of conformers against experimental data by analyzing the principal components of structural change to see if the known experimental space is reproduced.
Workflow: Navigating Sampling Method Selection
The following diagram illustrates a logical pathway for selecting a sampling strategy based on your research goals and resources.
The Scientist's Toolkit: Research Reagent Solutions
| Tool / Resource | Function / Description | Relevance to Sampling |
|---|---|---|
| AMBER99SB*-ILDN Force Field [14] | A high-quality, all-atom intramolecular force field. | Provides physically accurate energy calculations for both MD and MC simulations, crucial for correct folding behavior. |
| Generalized Born (GB) Implicit Solvent Model [14] | An approximate model that simulates solvent effects without explicit water molecules. | Drastically reduces computational cost, making extensive sampling in MC and hybrid methods feasible. |
| Elastic Network Model (ENM) [15] | A coarse-grained model that identifies a protein's collective, large-scale motions. | Used in hybrid methods to generate realistic deformation directions, guiding all-atom simulations to explore relevant conformational space. |
| Principal Component Analysis (PCA) [15] | A dimensionality reduction technique to identify major modes of structural variation. | A critical analytical tool to compare and validate that your simulation's sampled space matches experimental ensembles. |
| Visual Molecular Dynamics (VMD) [17] | A molecular visualization program for displaying, animating, and analyzing large biomolecular systems. | Essential for visual inspection of trajectories, analysis of structural dynamics, and creation of publication-quality renderings. |
A Toolkit of Solutions: Enhanced Sampling and AI-Driven Approaches
Troubleshooting Guides
FAQ 1: How do I resolve "hidden barriers" and poor sampling efficiency when my collective variables are not the true reaction coordinates?
| Problem | Root Cause | Diagnostic Steps | Solution |
|---|---|---|---|
| Ineffective acceleration and "hidden barriers" persist despite biasing chosen Collective Variables (CVs). | The selected CVs do not correspond to the true reaction coordinates (tRCs), missing the essential degrees of freedom that govern the conformational change [18]. | 1. Check if the biased trajectories follow non-physical pathways [18].2. Monitor if the system gets trapped in metastable states not described by the current CVs [1]. | 1. Identify True Reaction Coordinates (tRCs): Use methods like the generalized work functional (GWF) or potential energy flow (PEF) analysis computed from energy relaxation simulations to find optimal CVs [18].2. Use Adaptive Path CVs: Implement path collective variables (PCVs) that converge to the minimum free energy path during the simulation [19]. |
FAQ 2: How can I fix numerical instability and sampling artifacts in adaptive path collective variable simulations?
| Problem | Root Cause | Diagnostic Steps | Solution |
|---|---|---|---|
| Simulation crashes or shows large, non-physical fluctuations in the extended variable when using adaptive path CVs. | Discontinuities in the path CV value (s(z)) caused by path updates or the system "shortcutting" a curved path [19]. | 1. Observe sudden jumps in the value of the progress variable s in the output logs.2. Check for large, abrupt changes in the bias potential or the extended variable (λ). |
1. Stabilization Algorithm: Implement a correction step for the extended variable's position before integration. If the change in the CV (s(z)) between steps exceeds a threshold (e.g., the thermal coupling width σ), correct the previous extended variable position: λ(t-1) = s(z(t)) [19].2. Confinement Potential: Apply a mild harmonic restraint on the distance from the path (d(z)) to reduce shortcutting [19]. |
FAQ 3: What should I do if my metadynamics or eABF simulation shows poor free energy convergence?
| Problem | Root Cause | Diagnostic Steps | Solution |
|---|---|---|---|
| The calculated free energy profile does not converge and changes significantly with simulation time. | 1. In metadynamics, the bias deposition rate is too high [1].2. The CV space is too high-dimensional, leading to slow filling [19].3. The chosen CVs are suboptimal, creating hidden barriers [18]. | 1. For metadynamics, monitor the time evolution of the bias potential; it should stabilize [1].2. For WTM-eABF, check the convergence of the adaptive biasing force [19]. | 1. Use Well-Tempered Metadynamics: This variant reduces the height of added Gaussian hills over time, ensuring smoother convergence [1] [19].2. Employ Hybrid Methods: Use the WTM-eABF algorithm, which combines the benefits of metadynamics and ABF for faster and more robust convergence [19].3. Post-Processing Reweighting: Use the multistate Bennett's acceptance ratio (MBAR) estimator on the trajectory to recover unbiased statistical weights and improve the free energy estimate [19]. |
FAQ 4: How can I generate an initial path for path collective variable methods when I lack prior mechanistic knowledge?
| Problem | Root Cause | Diagnostic Steps | Solution |
|---|---|---|---|
| No initial transition path is available to initialize adaptive path CV simulations. | The transition mechanism is unknown, and reactant/product states are separated by a high free energy barrier [18]. | The simulation cannot be started because an initial path connecting the two metastable states is required. | 1. Linear Interpolation: Create an initial path by linearly interpolating between the known reactant and product structures in the CV space [19].2. Use tRCs from a Single Structure: Apply methods that can compute true reaction coordinates from a single protein structure via energy relaxation simulations, then use these to guide path generation [18].3. High-Temperature MD: Run short MD simulations at elevated temperatures to prompt spontaneous transitions, though this is not guaranteed for large barriers [1]. |
Experimental Protocols
Protocol 1: Setting Up a Well-Tempered Metadynamics Simulation with a Single Collective Variable
This protocol provides a methodology for accelerating the sampling of a conformational change using a one-dimensional CV, such as a distance or dihedral angle.
Application Context: This is suitable for studying processes where a reasonable one-dimensional reaction coordinate is known or hypothesized, such as a ligand dissociation or a domain hinge motion [1].
Detailed Methodology:
System Preparation:
- Prepare the protein-ligand complex topology and coordinate files using a tool like
tleapfor the AMBER suite. Solvate the system in a water box (e.g., TIP3P) and add ions to neutralize the charge [20]. - Perform a multi-step energy minimization to relieve steric clashes.
- Gradually heat the system to the target temperature (e.g., 300 K) under constant volume conditions with positional restraints on the protein heavy atoms.
- Equilibrate the system without restraints under constant pressure (NPT ensemble) until the density stabilizes [20].
- Prepare the protein-ligand complex topology and coordinate files using a tool like
Collective Variable Selection:
- Define a CV (
ξ) that distinguishes the reactant and product states. Examples include the distance between two protein domains, a key dihedral angle, or the root-mean-square deviation (RMSD) from a reference structure.
- Define a CV (
Simulation Parameters for Well-Tempered Metadynamics:
- Bias Factor: Set to achieve a significantly higher "bias temperature" (e.g., corresponding to 1000-6000 K) to enhance barrier crossing.
- Gaussian Height (
hG): Start with a value between 0.1 and 1.0 kJ/mol. - Gaussian Width (
σG): Choose based on the fluctuation of the CV in an unbiased short simulation. - Deposition Rate: Add a Gaussian hill every 1-10 ps (100-1000 simulation steps).
Production Simulation:
Protocol 2: Implementing the Path-WTM-eABF Hybrid Method for Complex Transitions
This protocol describes a more advanced setup for sampling complex transitions where a one-dimensional CV is insufficient, using adaptive path collective variables biased by the WTM-eABF algorithm [19].
Application Context: Ideal for intricate biomolecular processes like enzymatic reactions or large-scale protein conformational changes with multiple slow degrees of freedom [19].
Detailed Methodology:
Initial System Preparation: Follow the same steps as in Protocol 1 for system minimization, heating, and equilibration.
Define the Collective Variable Space and Initial Path:
- Select a set of relevant CVs (e.g., several distances, angles, or dihedrals) that are thought to describe the transition. This forms the CV space
z. - Generate an initial path connecting the reactant and product states in this CV space. This can be done via linear interpolation or by using a zero-temperature path optimization method like the nudged elastic band [19].
- Select a set of relevant CVs (e.g., several distances, angles, or dihedrals) that are thought to describe the transition. This forms the CV space
Configure the Path WTM-eABF Simulation:
- Path Parameters: Define the path with a sufficient number of discrete, equidistant nodes (e.g., 20-50). Set a path update frequency (e.g., every N steps) and a half-life (
τ) for the update weights. - WTM-eABF Parameters:
- Thermal Coupling Width (
σ): Use a small value (e.g., 0.01-0.05) for tight coupling between the extended variableλand the path progresss(z). - Bias Temperature (
ΔT): Set for the WTM component. - Gaussian Parameters: Define the height and width for the WTM hills deposited in
λ-space.
- Thermal Coupling Width (
- Stabilization: Enable the correction algorithm for the extended variable
λto handle discontinuities from path updates, using the thermal coupling widthσas the threshold [19].
- Path Parameters: Define the path with a sufficient number of discrete, equidistant nodes (e.g., 20-50). Set a path update frequency (e.g., every N steps) and a half-life (
Production and Analysis:
- Run the simulation. The path will iteratively update towards the minimum free energy path.
- Monitor the convergence metric
Δs(z), which should approach zero at the transition state for an ideal path [19]. - Use the MBAR estimator on the trajectory frames to compute the final converged free energy profile [19].
| Item Name | Function / Purpose | Example Usage in Protocol |
|---|---|---|
| Molecular Dynamics Engine | Software to perform the MD and enhanced sampling simulations. | GROMACS [1], NAMD [1], AMBER [1] [20]. Used in all protocols for simulation execution. |
| Path Collective Variable (PCV) Implementation | A code or plugin that defines and manages adaptive path CVs. | PLUMED [19]. Essential for Protocol 2 to define the path and calculate the progress variable s(z). |
| Generalized Born (GB) Solvent Model | An implicit solvent model for faster computation of solvation effects. | Used in force field parameterization for continuum solvent [21] and can be used in production MD (e.g., igb=5 in AMBER [21]). |
| True Reaction Coordinate (tRC) Identification Tool | A method or code to compute optimal CVs from protein structures. | Generalized Work Functional (GWF) method [18]. Used to find the best CVs to bias, overcoming hidden barriers. |
| Multistate Bennett's Acceptance Ratio (MBAR) | A statistical reweighting estimator to compute unbiased free energies from biased simulations. | Used in post-processing of WTM-eABF trajectories to obtain accurate free energies [19]. |
| IEFPCM Solvent Model | A continuum solvation model used in quantum chemical calculations. | Used during force field parameterization to compute energies in liquid phase for more accurate parameters [21]. |
Signaling Pathways and Workflows
Frequently Asked Questions (FAQs) & Troubleshooting Guide
This guide addresses common challenges researchers face when implementing generative AI models for simulating small protein ensembles, providing targeted solutions to overcome sampling limitations.
FAQ 1: Why does my generated protein ensemble lack structural diversity and get stuck near the initial conformation?
- Problem: The model fails to explore conformational states far from the input structure, a common limitation noted in models like AlphaFlow and aSAM when dealing with complex multi-state proteins or long flexible elements [22].
- Solutions:
- High-Temperature Training: Incorporate high-temperature (e.g., 450 K) simulation data from datasets like
mdCATHduring training. This teaches the model to overcome energy barriers and explore a wider landscape [22]. - Architectural Check: Ensure your model uses an expressive, full-rank transformation. For flow-based models, consider residual connections (
φ_k(x) = x + δ * u_k(x)) to improve the representational capacity of the learned transformation [23]. - Evaluation: Quantify diversity using the mean initial RMSD (
initRMSD) of your generated ensemble and compare it to a reference MD simulation. Consistently lower values indicate poor exploration [22].
- High-Temperature Training: Incorporate high-temperature (e.g., 450 K) simulation data from datasets like
FAQ 2: How can I improve the physical realism and stereochemical quality of generated atomistic structures?
- Problem: Generated structures, particularly side chains, may contain atom clashes or distorted bond geometries, even when global structures appear correct. This is a known issue in atomistic generators like aSAM [22].
- Solutions:
- Post-Processing Energy Minimization: Apply a brief, constrained energy minimization to the raw model outputs. Restraining backbone atoms to 0.15–0.60 Å RMSD during minimization can efficiently resolve clashes while preserving the overall ensemble structure [22].
- Physics-Informed Loss: Incorporate physics-based terms, such as bond length or angle restraints, directly into the model's loss function during training to encourage stereochemical validity [22].
- Quality Metrics: Use validation tools like MolProbity scores to assess clash scores and overall structural quality, comparing your results against established baselines [22].
FAQ 3: My model performs well on backbone atoms but poorly on side-chain conformations. How can I fix this?
- Problem: Some models are optimized for backbone (Cα) generation and treat side chains as a separate, less accurate post-processing step [22].
- Solutions:
- Latent Diffusion for Atoms: Implement a latent diffusion model (like aSAM) that encodes and generates heavy atom coordinates, forcing the model to learn joint distributions for both backbone and side-chain torsion angles [22].
- Focus on Torsions: Evaluate your model's performance on side-chain dihedral angles (χ distributions). A model specifically designed for atomistic generation should approximate these distributions from MD reference data much more effectively than Cα-only models [22].
FAQ 4: What is the fundamental connection between a denoising diffusion model and a classical Molecular Dynamics (MD) force field?
- Problem: The relationship between the learned denoising process and physical forces can seem abstract.
- Explanation: A denoising model trained to remove noise from atomic configurations is mathematically equivalent to learning the physical force field. For a Boltzmann distribution
p ∝ e^(-βE), the score function∇log pis proportional to the physical forces-∇E[24] [25]. The model learns to move atoms from a noisy (unstable) state back to a more stable one, which is precisely what forces do in an MD simulation [24].
Experimental Protocols & Performance Data
The following table summarizes key quantitative results from benchmarking the aSAM model against AlphaFlow on the ATLAS dataset, highlighting their respective strengths and weaknesses in generating protein ensembles [22].
Table 1: Benchmarking aSAM versus AlphaFlow on ATLAS MD Dataset
| Evaluation Metric | Model | Performance Result | Interpretation & Implication |
|---|---|---|---|
| Cα RMSF Correlation (PCC) | AlphaFlow | 0.904 (Avg.) | Better at capturing the amplitude of local backbone fluctuations. |
| aSAMc | 0.886 (Avg.) | Slightly lower, but still strong performance on local flexibility. | |
| Cβ Ensemble Similarity (WASCO-global) | AlphaFlow | Higher Score | Significantly better at approximating the global ensemble diversity. |
| aSAMc | Lower Score | Struggles more with multi-state proteins and large conformational changes. | |
| Backbone Torsion Angles (WASCO-local) | aSAMc | Higher Score | Superior at learning the joint distribution of φ/ψ angles. |
| AlphaFlow | Lower Score | Limited by training that uses only Cβ positions. | |
| Side-Chain Torsion Angles (χ distributions) | aSAMc | High Accuracy | Effectively approximates χ distributions from MD data. |
| AlphaFlow | Low Accuracy | Cannot model side-chain torsions directly. | |
| Structural Quality (MolProbity Score) | AlphaFlow | Better (Lower) Score | Produces structurally cleaner outputs with fewer clashes. |
| aSAMc | Worse (Higher) Score by 0.63 units | Requires post-generation energy minimization for improvement. |
Protocol: Implementing a Temperature-Conditioned Latent Diffusion Model (aSAMt)
This methodology enables the generation of structural ensembles conditioned on temperature, generalizing to unseen sequences and temperatures [22].
Data Preparation:
- Source: Use the
mdCATHdataset, which contains MD simulations for thousands of globular protein domains at multiple temperatures (e.g., 320 K to 450 K) [22]. - Partition: Split the data into training and test sets, ensuring no protein sequence overlap.
- Source: Use the
Model Training:
- Step 1 - Autoencoder (AE): Train an autoencoder to learn a compressed, SE(3)-invariant latent representation of heavy atom protein coordinates. The decoder must accurately reconstruct 3D structures with a heavy atom RMSD of 0.3–0.4 Å [22].
- Step 2 - Latent Diffusion: Train a diffusion model to learn the probability distribution of the latent encodings. Condition this model on both an initial 3D structure and the target temperature [22].
Ensemble Generation & Refinement:
- Sampling: For a given input structure and temperature, sample multiple latent vectors from the diffusion model and decode them into 3D structures [22].
- Energy Minimization: To resolve minor atom clashes, apply a short energy minimization protocol that restrains backbone atoms. This step is crucial for achieving high MolProbity scores [22].
Validation:
- Assess the temperature-dependent behavior of ensemble properties like flexibility (RMSF) and conformational diversity (PCA, initRMSD).
- Use WASCO-local scores to validate the accuracy of backbone (φ/ψ) and side-chain (χ) torsion angle distributions against reference MD data [22].
Workflow Visualization
The following diagram illustrates the core architecture and process of a temperature-conditioned latent diffusion model for protein ensemble generation.
The Scientist's Toolkit: Research Reagent Solutions
Table 2: Essential Resources for Generative Protein Ensemble Research
| Resource Name | Type | Primary Function in Research |
|---|---|---|
| mdCATH Dataset [22] | Dataset | Provides MD simulations of thousands of globular protein domains at multiple temperatures for training and validating temperature-conditioned models. |
| ATLAS Dataset [22] | Dataset | A large dataset of protein simulations performed at 300 K, used for benchmarking ensemble generation methods. |
| aSAM / aSAMt [22] | Software Model | An atomistic latent diffusion model for generating all-heavy-atom protein ensembles, with a version (aSAMt) conditioned on temperature. |
| AlphaFlow [22] | Software Model | A generative model based on AlphaFold2 components, used as a state-of-the-art benchmark for Cβ and flexibility modeling. |
| BoltzGen [26] | Software Model | A generative AI model capable of de novo protein binder design, unifying both structure prediction and protein design tasks. |
| Energy Minimization Protocol [22] | Computational Method | A constrained optimization process applied to generated structures to resolve atom clashes and improve stereochemical quality without significantly altering the global conformation. |
| WASCO Score [22] | Analysis Metric | Quantifies the similarity between two structural ensembles (global) or their local torsion angle distributions (local). |
| Equivariant GNN (e.g., SE(3)-Transformer) [25] | Neural Network Architecture | A type of graph neural network that preserves symmetry under 3D rotations and translations, crucial for processing and generating 3D molecular structures. |
Leveraging Machine Learning for Data-Driven Collective Variables
Technical Support Center
Frequently Asked Questions (FAQs)
FAQ 1: What are data-driven collective variables (CVs) and how do they differ from traditional CVs? Data-driven CVs are one-dimensional, interpretable, and differentiable variables generated by machine learning algorithms to describe a transformation's progress. Unlike traditional CVs, which are based on intuitive physical or chemical descriptors (e.g., distances, angles, radii of gyration), data-driven CVs are a generalization of the path collective variable concept. They are created by performing a kernel ridge regression of the committor probability, which encodes the progress of a transformation. This approach can uncover optimal descriptors for modeling transformations that are not apparent through physical intuition alone [27].
FAQ 2: Why is adequate sampling a critical challenge in Molecular Dynamics (MD) simulations of small proteins? Biological molecules possess rough energy landscapes with many local minima separated by high-energy barriers. This makes it easy for simulations to become trapped in non-functional conformational states for extended periods, preventing a meaningful characterization of the protein's dynamics and function. Large conformational changes essential for biological activity, such as those occurring during catalysis or substrate transport, often occur on timescales beyond the reach of conventional MD simulations [1].
FAQ 3: My ML-CV seems to perform poorly when applied to a larger system. What could be the cause? This is a common issue related to transferability. A machine-learned force field (and by extension, a CV derived from it) is only applicable to the phases of the material in which it was trained. If the larger system explores regions of phase space not included in the training data, the results will be unreliable. The best practice is to ensure the training data explores as much of the relevant phase space as possible. It is often recommended to train a force field on a system that is large enough for the relevant phonons or collective oscillations to fit into the supercell [28].
FAQ 4: During on-the-fly training, the number of reference configurations (ML_ABN) is low. How can I increase it?
A low number of selected reference configurations indicates that the algorithm is not encountering enough novel atomic environments. This can be addressed by adjusting the threshold for selecting new configurations. Lowering the default value of the ML_CTIFOR parameter (e.g., from 0.02 to a smaller value) makes the criterion for adding a new configuration to the training set more sensitive. The optimal value is system-dependent and should be determined through trial and error [28].
FAQ 5: How should I handle atoms of the same element in different chemical environments (e.g., bulk vs. surface oxygen)? Treating them as a single species can lead to higher errors. For improved accuracy, you can split a single elemental species into multiple subtypes. This involves:
- Grouping atoms by their subtype in the POSCAR file.
- Assigning each group a unique name (e.g., O1, O2).
- Updating the POTCAR file to include a separate entry for each new species name. Be aware that this improves accuracy at the cost of computational efficiency, as the cost scales quadratically with the number of species [28].
Troubleshooting Guides
Problem: Poor Convergence of Free Energy Estimates with ML-CVs
| Symptom | Potential Cause | Solution |
|---|---|---|
| Hysteresis in free energy profiles | Inadequate sampling of the transition path or a poorly chosen CV. | Ensure the ML-CV is trained on sufficient data that includes configurations from the transition state region. Consider running multiple independent simulations or using a variant of metadynamics (e.g., well-tempered metadynamics) to improve convergence [1]. |
| Drifting free energy estimates | The system is exploring new phase space not captured by the original ML-CV. | Implement a re-training protocol where the ML model is updated with new data collected during the enhanced sampling simulation, or use an on-the-fly learning approach [27] [28]. |
| High variance in forces from MLFF | Insufficient training data or inaccurate ab-initio reference calculations. | Verify the convergence of the underlying ab-initio calculations (e.g., KPOINTS, ENCUT). Continue training in underrepresented regions of phase space (using ML_MODE=TRAIN with an existing ML_AB file) to expand the database [28]. |
Problem: Instabilities in On-the-Fly Machine Learning Force Field Training
| Symptom | Potential Cause | Solution |
|---|---|---|
| Non-converged electronic structures during ab-initio steps | The use of charge density mixing (MAXMIX) with large ion steps between calculations. |
Do not set MAXMIX > 0 when training force fields. The significant movement of ions between first-principles calculations often causes the self-consistency cycle to fail [28]. |
| Unphysical cell deformation in NpT simulations | Extreme cell tilting, especially in fluids or systems with vacuum. | For fluids, use ICONST to constrain the cell shape and only allow volume changes. This prevents the cell from "collapsing." For systems with surfaces or isolated molecules, train stresses are not physical; set ML_WTSIF to a very small value (e.g., 1E-10) and use the NVT ensemble [28]. |
| Poor exploration of phase space | Training in the NVE ensemble or starting at too high a temperature. | Avoid training in the NVE ensemble. Prefer the NpT ensemble (if applicable) or the NVT ensemble with a stochastic thermostat (e.g., Langevin) for better ergodicity. Start training at a low temperature and gradually increase it (ramp) to about 30% above the target application temperature [28]. |
Problem: Inaccurate or Non-Interpretable ML-CVs
| Symptom | Potential Cause | Solution |
|---|---|---|
| CV fails to distinguish between relevant states | The input features/descriptors lack the necessary information to describe the mechanism. | Use global descriptors that capture permutation invariance or other relevant symmetries. For solvation dynamics, ensure descriptors include information from the first solvation shell. In some cases, inertial effects may require more complex features than just atomic positions [27]. |
| CV is noisy and not smooth | Under-regularized model or noisy training data. | Adjust the regularization parameter in the kernel ridge regression. Ensure the forces from the ab-initio calculations are well-converged, as they are used in training the committor model [27] [28]. |
Experimental Protocols and Methodologies
Protocol 1: Data-Driven Path Collective Variable Generation
This methodology outlines the generation of a data-driven collective variable as described in France-Lanord et al. [27].
- Data Collection: Perform ab-initio MD simulations or select a diverse set of configurations from existing trajectories that span the transformation of interest (e.g., unfolded and folded states, associated and dissociated states).
- Feature Calculation: For each configuration, compute a set of atomic descriptors. These can be simple intuitive variables or high-dimensional global descriptors (e.g., permutation invariant vectors).
- Committor Analysis: Estimate the committor probability for each configuration in the dataset. The committor, pB, is the probability that a configuration committed to state B (the product state) rather than state A (the reactant state).
- Model Training: Use a kernel ridge regression (KRR) algorithm to learn the functional relationship between the atomic descriptors and the committor probabilities.
- CV Validation: The resulting model provides a one-dimensional, differentiable, and interpretable CV. Validate its quality by projecting the transformation path onto this CV and ensuring it provides a clear and continuous reaction coordinate.
Protocol 2: On-the-Fly Training of a Machine-Learned Force Field in VASP
This protocol summarizes the best practices for training an MLFF as per the VASP wiki [28], which can serve as the foundation for ML-CVs.
Initial Setup:
- Set
ML_MODE = TRAIN. The presence or absence of anML_ABfile determines if training starts from scratch or continues from an existing database. - Configure the ab-initio settings in the
INCARfile for electronic minimization. Crucially, setISYM = 0(turn off symmetry) and avoid settingMAXMIX > 0. - For the MD part, set a suitable time step (
POTIM): not exceeding 0.7 fs for hydrogen-containing compounds or 1.5 fs for oxygen-containing compounds. - Prefer the NpT ensemble (
ISIF=3) for robustness, or NVT (ISIF=2) with a Langevin thermostat. Avoid the NVE ensemble.
- Set
Systematic Training for Complex Systems:
- If the system has different components (e.g., a crystal surface and an adsorbing molecule), train them separately first. Train the bulk crystal, then the surface, then the isolated molecule, and finally the combined system.
Continual Learning and Refinement:
- To add new configurations to an existing database, run
ML_MODE = TRAINwith the existingML_ABfile in the working directory. - To generate a new force field from a precomputed ab-initio dataset (
ML_ABfile), useML_MODE = SELECT. This mode ignores the old list of local reference configurations and creates a new set.
- To add new configurations to an existing database, run
Protocol 3: Enhanced Sampling with Metadynamics using ML-CVs
This protocol integrates the ML-CV into an enhanced sampling technique [1].
- Collective Variable Definition: Use the data-driven CV generated in Protocol 1 as the reaction coordinate for metadynamics.
- Simulation Setup: In your MD software (e.g., GROMACS, NAMD), configure a metadynamics simulation. Define the ML-CV as the biased collective variable.
- Parameters: Set the Gaussian hill height and width, and the deposition rate. For well-tempered metadynamics, set an appropriate bias factor.
- Production Run: Run the metadynamics simulation. The history-dependent bias potential will "fill" the free energy wells, encouraging the system to escape local minima and explore new regions of the CV space.
- Analysis: The free energy surface (FES) as a function of the ML-CV can be reconstructed from the deposited bias potential.
Workflow and Relationship Diagrams
Workflow for Developing and Using ML-CVs
Decision Tree for Sampling Method Selection
The Scientist's Toolkit: Research Reagent Solutions
Table: Essential Tools for ML-CV Development and Enhanced Sampling
| Item/Reagent | Function/Brief Explanation | Key Considerations |
|---|---|---|
| VASP [28] | A software package for performing ab-initio quantum mechanical calculations using pseudopotentials and a plane wave basis set. Used to generate accurate training data (forces, energies) for MLFFs and ML-CVs. | Requires careful setup of INCAR parameters (e.g., ISYM=0, avoid MAXMIX). The POTCAR file must not change between training sessions. |
| AMBER99SB*-ILDN [14] | An all-atom force field for proteins. Provides intramolecular interaction parameters. Often combined with an implicit solvent model for faster sampling in Monte Carlo or MD simulations. | When used with implicit solvent, limitations include over-stabilized salt bridges and neglect of temperature dependence of solvation free energy. |
| GROMACS/NAMD [1] | High-performance molecular dynamics simulation packages. Used to run conventional and enhanced sampling MD simulations. They support plugins or built-in methods for metadynamics and replica-exchange. | Ensure compatibility with the ML-CV definition, which may require custom coding or the use of a PLUMED plugin to interface the ML model with the MD engine. |
| Metadynamics [1] | An enhanced sampling technique that accelerates the exploration of free energy landscapes by adding a history-dependent bias potential. Ideal for biasing data-driven CVs. | Effectiveness depends on the quality of the CV. Well-tempered metadynamics is often preferred to improve convergence. |
| Replica-Exchange MD (REMD) [1] | A sampling method that runs multiple parallel simulations at different temperatures (T-REMD) or with different Hamiltonians (H-REMD), periodically exchanging configurations. | Efficiency is sensitive to the choice of maximum temperature. Too high a maximum temperature can make REMD less efficient than conventional MD. |
| Generalized Born/SASA Model [14] | An implicit solvent model that approximates the electrostatic and non-polar contributions to solvation free energy. Significantly faster than explicit solvent for MC simulations. | Can have limited representation of hydrogen bonds and incorrect ion distributions compared to explicit solvent models. |
| Kernel Ridge Regression [27] | The machine learning algorithm used to create the data-driven CV by regressing atomic descriptors against the committor probability. | Produces a one-dimensional, differentiable, and interpretable CV suitable for biasing in enhanced sampling. |
| Permutation Invariant Vector [27] | A type of global atomic descriptor used as input for the ML model. It can capture complex structural information that simpler, intuitive variables might miss. | Can be essential for achieving high accuracy in systems where simple CVs are insufficient. |
Molecular Dynamics (MD) simulation has become an indispensable tool for studying biomolecular processes, such as protein folding and drug binding. However, a fundamental challenge limits its effectiveness: the femtosecond timestep required for numerical integration means that observing biologically relevant events often requires simulating microseconds to milliseconds of real time, which demands immense computational resources [29]. This "timescale problem" fundamentally constrains the questions researchers can address about large-scale conformational changes using accessible computational hardware [14].
In this context, Monte Carlo (MC) methods emerge as a powerful alternative for thermodynamic characterization. Unlike MD, which simulates dynamics through time, MC methods rely on random sampling of conformational space and have no inherent timescale, enabling them to bypass kinetic limitations entirely [14]. This technical support guide explores how researchers can implement MC approaches to overcome sampling barriers in the study of small proteins, providing practical troubleshooting and methodological frameworks.
Understanding Monte Carlo: Key Concepts for Researchers
Fundamental Principles
Monte Carlo simulations generate a sequence of molecular conformations through random moves that are accepted or rejected based on the Metropolis criterion, which uses energy calculations to Boltzmann-weight probabilities. This approach provides several distinct advantages for specific research applications:
- Thermodynamic Focus: MC simulations are designed to sample the Boltzmann distribution of states, making them ideal for calculating free energies, equilibrium populations, and stability parameters without being constrained by kinetic barriers [14].
- No Inherent Timescale: Because MC is not based on numerical integration of equations of motion, it does not simulate a physical trajectory through time. This allows it to "jump" between distant conformational states that would be separated by slow, barrier-crossing events in MD [14].
- Efficient Move Sets: Specialized moves can be designed that modulate particularly important degrees of freedom, such as dihedral angles for peptides, leading to more efficient exploration of conformational space per computational step [14].
Comparative Advantages Over Molecular Dynamics
Table: Key Differences Between Molecular Dynamics and Monte Carlo Simulation Approaches
| Feature | Molecular Dynamics | Monte Carlo |
|---|---|---|
| Timescale | Inherently linked to simulation time | No inherent timescale |
| Primary Output | Kinetic trajectories & time-dependent properties | Thermodynamic ensembles & equilibrium properties |
| Barrier Crossing | Limited by integration timestep & energy barriers | Can bypass barriers through discrete moves |
| Solvent Treatment | Efficient with explicit solvent | Typically uses implicit solvent models |
| Kinetic Information | Directly provides kinetic data | Requires reconstruction from thermodynamic data [14] |
Implementation Guide: Monte Carlo for Small Protein Folding
Research Reagent Solutions
Table: Essential Computational Components for Monte Carlo Protein Folding Studies
| Component | Function | Example Implementations |
|---|---|---|
| Intramolecular Force Field | Defines energy contributions from bonds, angles, torsions, and non-bonded interactions | AMBER99SB*-ILDN [14], CHARMM |
| Implicit Solvent Model | Approximates solvent effects without explicit water molecules, dramatically speeding up calculations | Generalized Born with Surface Area (GBSA) [14] |
| Sampling Algorithm | Governs how conformational moves are proposed and accepted | Metropolis Monte Carlo, Wang-Landau Sampling |
| Move Sets | Defines types of conformational changes attempted | Dihedral angle rotations, backbone moves, sidechain adjustments |
| Analysis Tools | Processes simulation output to extract thermodynamic information | Free energy estimators, cluster analysis, order parameters |
Experimental Protocol: Thermodynamic Characterization of Small Proteins
The following workflow provides a validated methodology for studying protein folding using Monte Carlo simulations, based on successful applications to well-characterized model systems like Trp-cage, Villin headpiece, and WW-domain [14]:
System Preparation
- Obtain initial coordinates from PDB or generate extended structures.
- Select an appropriate all-atom force field (e.g., AMBER99SB*-ILDN).
- Choose an implicit solvent model (e.g., GBSA) to represent solvation effects.
Simulation Parameterization
- Define move sets focusing on torsion angles for efficient sampling.
- Set temperature range wide enough to characterize folding/unfolding equilibria.
- Determine total sampling requirements (typically hundreds of millions of MC steps).
Production Simulation
- Execute multiple independent runs from different initial conditions.
- Implement replica exchange across temperatures if enhanced sampling is needed.
- Monitor convergence through energy stability and structural metrics.
Analysis and Validation
- Construct free energy landscapes using order parameters (e.g., RMSD, radius of gyration).
- Identify transition states and energy barriers.
- Calculate per-residue stability contributions.
- Validate against experimental structural and thermodynamic data.
Performance Metrics and Validation
Table: Representative Monte Carlo Simulation Results for Model Proteins [14]
| Protein System | Size (residues) | Topology | Key Thermodynamic Parameters | Sampling Requirements |
|---|---|---|---|---|
| Trp-cage | 20 | α-helix + 3₁₀-helix | Melting temperature, hydrophobic core stability | 200M steps, ~180 CPU hours |
| Villin Headpiece | 36 | Three-helix bundle | Helix-coil transition barriers, tertiary contact formation | Comparable to Trp-cage |
| WW Domain | 35 | Three-stranded β-sheet | β-sheet formation energetics, turn stability | Comparable to Trp-cage |
Frequently Asked Questions (FAQs)
Q1: What are the primary limitations of using implicit solvent models in Monte Carlo simulations?
Implicit solvent models, while computationally efficient, introduce several potential limitations that researchers must consider:
- Limited hydrogen bond representation that can affect secondary structure stability
- Over-stabilized salt bridges due to insufficient screening of electrostatic interactions
- Incorrect ion distribution around the protein surface
- Neglection of the temperature dependence of solvation free energy [14]
- Difficulty reproducing water-mediated interactions that are crucial for some folding mechanisms (e.g., in Trp-cage) [29] [14]
Q2: Can kinetic information be recovered from Monte Carlo simulations?
While MC simulations do not directly provide kinetic information, it is possible to reconstruct large-scale kinetics from thermodynamic data. For biological processes that can be described as transitions between a few distinct conformational sub-ensembles, the barriers between these ensembles—which are directly sampled in MD—can be computed from thermodynamic averages in MC methods [14]. This permits estimation of transition rates between major states using appropriately parameterized kinetic models.
Q3: How do I validate the accuracy of my Monte Carlo folding simulations?
Validation should employ multiple complementary approaches:
- Structural validation: Compare lowest-energy structures to experimental coordinates (e.g., RMSD to PDB structures)
- Thermodynamic validation: Calculate melting temperatures and compare to experimental values
- Free energy validation: Reconstruct free energy landscapes and verify folding funnels correspond to experimental expectations
- Convergence testing: Ensure independent runs from different initial conditions sample similar distributions
- Force field validation: Test with known model systems before applying to novel proteins [14]
Q4: What types of move sets are most effective for protein folding studies?
Effective move sets typically focus on the most flexible degrees of freedom:
- Dihedral angle rotations for backbone and sidechain flexibility
- Backbone moves that preserve local geometry while enabling larger conformational changes
- Combined moves that simultaneously adjust multiple correlated degrees of freedom The optimal move set often depends on the specific protein system and should be tested for efficiency and acceptance rate during preliminary simulations.
Troubleshooting Common Issues
Problem 1: Poor Sampling of Folded States
Symptoms: Simulations fail to locate native-like structures; energy distributions show no low-energy peak corresponding to folded state.
Solutions:
- Increase simulation length (typically hundreds of millions of MC steps are needed)
- Implement replica exchange across a wider temperature range
- Modify move sets to include larger backbone displacements
- Verify force field parameters are appropriate for your protein system
- Check that implicit solvent parameters are correctly specified [14]
Problem 2: Structural Artifacts and Non-Native Stability
Symptoms: Non-physical structural motifs (e.g., excessive helicity in β-proteins); incorrectly stabilized non-native states.
Solutions:
- Validate force field against known experimental structures and stabilities
- Adjust implicit solvent parameters to better mimic explicit solvent behavior
- Incorporate experimental restraints if available (e.g., NMR distances)
- Compare results across multiple independent runs to identify consistent vs. artifactual features [29] [14]
Problem 3: Failure to Achieve Convergence
Symptoms: Significant differences in energy distributions between independent runs; free energy profiles that change substantially with additional sampling.
Solutions:
- Extend simulation length until key metrics stabilize
- Implement enhanced sampling techniques like replica exchange
- Use multiple diverse starting structures to ensure complete sampling
- Monitor convergence using multiple metrics (energy, RMSD, secondary structure content) [14]
Advanced Applications and Future Directions
Monte Carlo methods continue to evolve with several promising research applications:
- Multi-scale Modeling: Combining all-atom MC with coarse-grained approaches for larger systems [14]
- Force Field Development: Testing new energy functions with efficient thermodynamic sampling [14]
- Cellular Environments: Extending to crowded cellular conditions while maintaining sampling efficiency
- Drug Design Applications: Calculating binding free energies for protein-ligand systems where slow conformational changes limit MD approaches
As force fields and implicit solvent models continue to improve, Monte Carlo methods offer a complementary approach to MD that can overcome fundamental sampling limitations in small protein studies, providing researchers with robust tools for thermodynamic characterization without the constraints of molecular timescales.
Specialized MD Techniques for Intrinsically Disordered Proteins (IDPs)
Frequently Asked Questions (FAQs) & Troubleshooting Guides
FAQ 1: What are the main challenges when running MD simulations for IDPs?
Answer: Simulating IDPs presents two primary challenges: achieving accurate physical models (force fields) and ensuring sufficient conformational sampling.
- Force Field Accuracy: Traditional force fields, parameterized for folded proteins, often lead to IDP ensembles that are overly compact or have incorrect secondary structure propensities. This is due to an imbalance in protein-protein, protein-water, and water-water interactions [30] [31]. State-of-the-art force fields like CHARMM36m and Amber ff19SB, when paired with modern water models (e.g., TIP3P*, OPC), have shown significant improvements [30] [31].
- Sampling Limitations: IDPs explore a vast and flat energy landscape with many local minima. Standard MD simulations, even on the microsecond scale, often fail to converge on a representative ensemble of structures, missing rare but biologically relevant states [32] [30]. This necessitates the use of advanced sampling techniques and substantial computational resources.
FAQ 2: My IDP ensemble is too compact compared to experimental data. How can I fix this?
Answer: An overly compact ensemble typically indicates a force field imbalance.
- Troubleshooting Steps:
- Verify Force Field Combination: Ensure you are using a modern IDP-optimized force field. Switch to a combination like CHARMM36m/TIP3P* or Amber ff19SB/OPC, which have been corrected to improve the solvation of disordered states [30] [31].
- Check Coarse-Grained Parameters: If using a coarse-grained model like Martini 3, apply a protein-water interaction scaling factor (e.g., 1.10) to reduce unnatural compaction and better match experimental dimensions [31].
- Integrate Experimental Data: Use a maximum entropy reweighting procedure to refine your simulation ensemble with experimental data from NMR and SAXS. This penalizes conformations that disagree with experiments and can correct for residual force field biases [33].
FAQ 3: How can I achieve adequate sampling for an IDP within a reasonable computation time?
Answer: Leverage advanced sampling methods and efficient simulation protocols.
- Recommended Protocols:
- Use Enhanced Sampling Techniques: Methods like Replica Exchange MD (REMD) allow the system to overcome energy barriers by simulating multiple copies at different temperatures, ensuring a broader exploration of conformational space [30] [31].
- Employ Multiple Independent Trajectories: Instead of one extremely long simulation, run multiple shorter, independent trajectories with different initial velocities. This can often improve conformational sampling more efficiently [31].
- Consider Multi-Scale Approaches: For large systems or very long timescales, start with coarse-grained simulations (e.g., Martini, SIRAH) to identify key states or regions of interest, then refine them with more detailed all-atom simulations [30] [31].
FAQ 4: What experimental data is most useful for validating and refining IDP simulations?
Answer: NMR spectroscopy and Small-Angle X-Ray Scattering (SAXS) are the primary experimental techniques used for validation and integration.
- NMR Spectroscopy: Provides atomic-level, residue-specific information on structural and dynamic properties. Key observables include chemical shifts, J-couplings, and residual dipolar couplings (RDCs), which report on secondary structure propensity and local dynamics [33] [34].
- SAXS: Yields low-resolution data on the global shape and dimensions of the IDP in solution, such as the radius of gyration (Rg), which is a critical check for over-compaction or over-extension in simulations [33] [30].
- Integration Workflow: The maximum entropy reweighting approach uses forward models to predict these experimental observables from each simulation snapshot and then reweights the entire ensemble to achieve the best agreement with the experimental dataset [33].
Troubleshooting Common Problems
Problem: Simulation shows incorrect secondary structure content (e.g., too much helix). Solution: This is a classic force field issue. Transition to a more modern force field like CHARMM36m or ff19SB. The dihedral parameters in these force fields have been specifically adjusted to better capture the conformational preferences of disordered states [30] [31].
Problem: The simulation is trapped in one conformational basin. Solution: Implement an enhanced sampling method. Gaussian accelerated MD (GaMD) is a technique that has been successfully used to sample rare events in IDPs, such as proline isomerization, which can act as conformational switches [32].
Problem: Discrepancies remain even after using an improved force field. Solution: Integrate your simulation with experimental data. The fully automated maximum entropy reweighting procedure allows you to combine data from multiple sources (NMR, SAXS) to determine a structurally accurate and force-field independent conformational ensemble [33].
Quantitative Data and Method Comparisons
Table 1: Comparison of State-of-the-Art Force Fields for IDP Simulations
| Force Field | Water Model | Key Features/Improvements | Best for |
|---|---|---|---|
| CHARMM36m [30] [31] | TIP3P* (modified) | Adjusted dihedral angles and protein-water vdW interactions to reduce over-compaction. | General-purpose IDP and folded protein simulations. |
| Amber ff19SB [31] | OPC | Optimized backbone and side-chain torsions based on a neural network, improving secondary structure balance. | Accurate secondary structure propensities in disordered and folded states. |
| a99SB-disp [33] | a99SB-disp water | A "disorder-friendly" force field with rebalanced protein-water interactions. | Generating initial ensembles for integrative modeling. |
| Coarse-Grained Martini 3 [31] | Martini water | Fast sampling; requires protein-water interaction scaling (~1.10) for accurate IDP dimensions. | Large systems and rapid exploration of conformational space. |
| Method | Principle | Advantage for IDPs |
|---|---|---|
| Replica Exchange MD (REMD) [30] [31] | Parallel simulations at different temperatures exchange configurations, overcoming energy barriers. | Efficiently samples the broad, flat energy landscape of IDPs. |
| Gaussian Accelerated MD (GaMD) [32] | Adds a harmonic boost potential to smooth the energy landscape, enabling sampling of rare events. | Captures slow transitions, such as proline isomerization or transient long-range contacts. |
| Maximum Entropy Reweighting [33] | Statistically reweights an existing ensemble to match experimental data with minimal bias. | Corrects for residual force field inaccuracies; produces ensembles that are consistent with experiments. |
Experimental Protocols & Workflows
Protocol 1: Determining an Accurate Conformational Ensemble via MD and Experimental Integration
This protocol is adapted from the maximum entropy procedure detailed in Nature Communications [33].
- Generate Initial Ensembles: Run long-timescale (e.g., 30 µs) all-atom MD simulations of the IDP using multiple modern force fields (e.g., a99SB-disp, CHARMM36m, Amber ff19SB) to ensure diversity in initial sampling.
- Collect Experimental Data: Acquire extensive experimental data, primarily:
- Calculate Observables: Use forward models (e.g., SHIFTX2 for chemical shifts) to predict the experimental observables from every frame of the MD simulation [33].
- Reweight the Ensemble: Apply the maximum entropy reweighting algorithm to assign new statistical weights to each simulation frame. The goal is to achieve the best agreement with the experimental data while maximizing the entropy of the final ensemble (minimizing bias from the initial simulation).
- Validate and Analyze: The output is a refined conformational ensemble. Validate its robustness by checking the similarity of ensembles derived from different initial force fields and analyze the structural and dynamic properties of the IDP.
The following workflow diagram illustrates this integrative process:
Protocol 2: Setting Up All-Atom and Coarse-Grained MD Simulations for an IDP
This practical guide is based on a case study of Amyloid-β [31].
A. All-Atom Simulation with Amber/Gromacs
- System Setup:
- Force Field/Water: Use Amber ff19SB (or CHARMM36m) with the OPC (or TIP3P*) water model.
- Solvation: Place the IDP in a cubic water box, ensuring a minimum distance (e.g., 1.2 nm) between the protein and box edge.
- Ions: Add ions to neutralize the system and reach a desired physiological concentration (e.g., 150 mM NaCl).
- Energy Minimization: Perform steepest descent minimization to remove bad contacts.
- Equilibration:
- Run a short simulation with positional restraints on the protein heavy atoms to equilibrate the solvent and ions.
- Gradually release the restraints while equilibrating the system at the target temperature (e.g., 300 K) and pressure (1 bar).
- Production MD: Run multiple independent trajectories without restraints. Use a different random seed for initial velocities in each run.
B. Coarse-Grained Simulation with Gromacs (Martini 3)
- Mapping and Topology: Convert the all-atom structure to a coarse-grained representation using the
martinize2script. - System Setup:
- Force Field: Use the Martini 3 force field.
- Solvation and Ions: Use the corresponding Martini water and ion models.
- Scaling: Apply a scaling factor (e.g.,
epsilon-rf=1.10for protein-water interactions in themartini_v3.x.scfile) to match experimental dimensions [31].
- Energy Minimization and Equilibration: Follow similar steps as the all-atom protocol, but with a longer time step (e.g., 20-30 fs).
- Production MD: Run the simulation. The increased efficiency of the coarse-grained model allows for much longer effective sampling times.
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Software and Tools for IDP MD Simulations
| Item Name | Function/Brief Explanation | Reference |
|---|---|---|
| GROMACS | A high-performance molecular dynamics package, highly optimized for both CPUs and GPUs. Ideal for both all-atom and coarse-grained simulations. | [35] [31] |
| AMBER | A suite of biomolecular simulation programs. Includes the pmemd engine, well-regarded for its efficiency and the ff19SB force field. |
[35] [31] |
| NAMD / QwikMD | A parallel MD simulation program. QwikMD provides a user-friendly GUI within VMD, simplifying the setup of complex simulations for novices and experts. | [35] [36] |
| CHARMM | A versatile program for energy minimization and dynamics simulations, providing the CHARMM force fields. | [35] |
| VMD | A molecular visualization program for displaying, animating, and analyzing large biomolecular systems. Essential for simulation analysis. | [36] |
| MaxEnt Reweighting Code | Custom code (e.g., from GitHub repository accompanying [33]) for integrating MD ensembles with experimental data using the maximum entropy principle. | [33] |
| pE-DB / Protein Ensemble DB | Databases for depositing and accessing structural ensembles of IDPs, useful for validation and comparison. | [34] [33] |
From Theory to Practice: Optimizing Simulations and Quantifying Uncertainty
Frequently Asked Questions
What is the most common mistake in setting up MD simulations for small proteins? A frequent mistake is the belief that a single, short trajectory is sufficient to capture a protein's behavior. Biological systems have vast conformational spaces, and a single simulation often gets trapped in a local energy minimum, failing to provide statistically meaningful results. To obtain valid thermodynamics, you should always run multiple independent simulations with different initial velocities [37].
My simulation ran without crashing. Does this mean my setup was correct? Not necessarily. MD engines will simulate a system even with incorrect parameters, such as wrong protonation states or incompatible force fields. Proper validation is essential. You should check that properties like energy, temperature, and pressure have stabilized and, whenever possible, compare simple observables like RMSF or NOE distances with experimental data [37].
How do I handle a ligand or non-standard residue in my protein system? You should not mix force fields carelessly. Instead, generate parameters for the custom molecule that are explicitly designed to work with your main protein force field. For example, use CGenFF with CHARMM36 or GAFF2 with AMBER ff14SB. Inconsistent parameters disrupt the balance of interactions and can lead to unrealistic behavior [37].
My RMSD looks stable. Is my protein equilibrated? A stable Root-Mean-Square Deviation (RMSD) is a good sign, but it does not guarantee full equilibration or that you have sampled all relevant states. You should also monitor other metrics, such as radius of gyration, hydrogen bond networks, and energy fluctuations, to build a multidimensional picture of system stability [37].
Troubleshooting Guides
Problem: Simulation is unstable and "blows up"
- Check your time step. An overly large timestep causes numerical instability. A value of 2 femtoseconds is common when using hydrogen constraints. Ensure you are not using a large timestep without the appropriate constraints [37].
- Verify minimization converged. Inadequate minimization fails to remove bad atomic contacts and high-energy strains. Always confirm that the energy minimization process has converged before proceeding to equilibration [37].
- Check for incorrect parameters. Review all simulation parameters, including the choice of integrator and thermostat. Using settings without understanding their meaning can lead to incorrect ensembles and instabilities [37].
Problem: Sampled conformations are not representative
- Run multiple replicates. A single trajectory is rarely sufficient. Run multiple independent simulations (3-5 is a good start) with different initial velocities to improve sampling and ensure your results are not an artefact of a single pathway [37].
- Employ an enhanced sampling method. If your process of interest involves crossing a high energy barrier, use a method like replica-exchange molecular dynamics (REMD) or metadynamics. These techniques are designed to help the system escape local minima and explore conformational space more broadly [38] [39].
- Confirm proper equilibration. Ensure the system's temperature, pressure, and density have stabilized over the equilibration phase. Do not start production runs until these thermodynamic properties show consistent plateaus [37].
Problem: Analysis results show strange jumps or distortions
- Correct for Periodic Boundary Conditions (PBC). PBC can cause molecules to appear split across the simulation box. Before analysis, use tools like
gmx trjconvin GROMACS orcpptrajin AMBER to make molecules whole again and remove jumps caused by crossing periodic boundaries [37].
Enhanced Sampling Method Selection Table
The table below summarizes key enhanced sampling methods to help you select the right one for your research question on small proteins.
| Method | Best For | Key Principle | System Size | Computational Cost |
|---|---|---|---|---|
| Replica-Exchange MD (REMD) [38] [39] | Folding, conformational changes, systems with rough energy landscapes. | Parallel simulations at different temperatures exchange states, overcoming energy barriers. | Small to medium-sized proteins. | High (scales with number of replicas). |
| Metadynamics [38] [39] | Calculating free energy landscapes, studying ligand binding, characterizing barrier crossing. | A history-dependent bias potential is added to discourage the system from visiting already sampled states. | Well-suited for studying specific processes with a few defined collective variables. | Moderate to High. |
| GaMD (Gaussian-accelerated MD) [38] | Spontaneous ligand binding, characterizing large-scale conformational changes. | Adds a harmonic boost potential to smoothen the energy landscape, lowering energy barriers. | Applicable to large systems like protein-ligand complexes. | Moderate. |
| REST (Replica Exchange with Solute Tempering) [38] | Biomolecular binding, solvation, and conformational changes focused on a solute. | The "temperature" of the solute and its immediate environment is scaled, reducing the number of required replicas. | Efficient for studying a solute in explicit solvent. | Lower than standard REMD. |
Experimental Protocols
Protocol 1: Running a Standard Metadynamics Simulation
- Define Collective Variables (CVs): Identify 1-2 CVs that best describe the process of interest (e.g., a distance, an angle, or a dihedral).
- Choose Simulation Parameters:
- Hill height/width: This determines the size of the Gaussian "hills" deposited. Start with values recommended by your software's documentation.
- Deposition rate: This defines how frequently hills are added.
- Run the Simulation: Execute the metadynamics simulation. As it progresses, the bias potential will fill the underlying free energy basins.
- Analyze the Results: The negative of the deposited bias potential provides an estimate of the Free Energy Surface (FES) as a function of your chosen CVs.
Protocol 2: Setting up a REST2 Simulation for Protein-Ligand Binding
- System Preparation: Prepare your solvated protein-ligand complex as usual.
- Define the "Hot" Region: Specify the ligand and the protein's binding site residues as the region to which the scaling will be applied.
- Set Replica Parameters: Determine the number of replicas and the range of scaling factors (lambda) needed to ensure sufficient exchange probability between neighboring replicas.
- Run and Analyze: Run the parallel REMD simulation. Analyze the trajectories from the different replicas, focusing on the unbiased (lowest lambda) replica for structural analysis, and use the replica exchange data to compute thermodynamic properties.
The Scientist's Toolkit: Research Reagent Solutions
| Item | Function |
|---|---|
| MARTINI Coarse-Grained Model [38] | A coarse-grained force field that reduces system complexity by grouping multiple atoms into single "beads," enabling the simulation of larger systems and longer timescales. |
| Markov State Models (MSM) [38] | A data-analysis framework built from many short MD simulations to predict long-timescale kinetics and identify metastable states within a complex conformational landscape. |
GROMACS trjconv [37] |
A versatile tool for trajectory processing, essential for correcting periodic boundary conditions, removing jumps, and centering the system for analysis. |
| pdbfixer / H++ [37] | Online tools and software for protein structure preparation, which can add missing atoms, correct structural gaps, and assign protonation states at a given pH. |
Method Selection Workflow
This decision diagram outlines a logical pathway for selecting the most appropriate enhanced sampling method based on your research question and system characteristics.
Best Practices in Uncertainty Quantification (UQ) for Trajectory Data
Frequently Asked Questions (FAQs)
1. Why is UQ essential for my molecular dynamics simulations? The usefulness of a simulated result ultimately hinges on being able to confidently and accurately report uncertainties along with any given prediction. This is crucial because molecular systems are complex and operate at the edge of computational capabilities; even with large-scale computing resources, adequate sampling is not guaranteed. Communicating statistical uncertainties allows consumers of your data to understand its significance and limitations [40].
2. What is the difference between standard deviation and standard uncertainty? It is critical to distinguish between these terms. The standard deviation (( \sigma_x )) is a measure of the width of the distribution of a random quantity. In itself, it is not a direct measure of statistical uncertainty. The standard uncertainty, often estimated by the experimental standard deviation of the mean (( s(\bar{x}) )), quantifies the uncertainty in your estimate of a true value (like an expectation value) [40].
3. My simulation has run for a long time. How can I check if the sampling is adequate? Long simulation time does not automatically guarantee adequate sampling. Best practices advocate for a tiered approach. Before estimating observables, perform semi-quantitative checks on your trajectory data. This includes calculating timescales for conformational changes relevant to your system and ensuring your simulation explores these transitions multiple times. Monitoring the evolution of running averages for key observables can also indicate if sampling is sufficient [40].
4. How do I handle uncertainty when my derived observable is a "nontrivial" property? Derived observables, such as free energies, are properties not computed from a single configuration but from a "nontrivial" analysis of raw trajectory data. The UQ approach must be tailored to the specific method used. For instance, if the analysis itself involves a fitting procedure or a specialized algorithm, you may need to employ techniques like bootstrapping or Bayesian inference to propagate the uncertainty from the raw data to the final derived result [40].
5. What are the main sources of uncertainty that UQ does not address? The UQ methods discussed here focus exclusively on statistical uncertainties arising from finite sampling. They do not address systematic errors, which can stem from inaccuracies in the force field, the underlying model, implementation bugs, or the choice of simulation parameters [40].
Troubleshooting Guides
Issue 1: Inadequate Sampling and Poor Convergence
Problem: The running average of a key observable, such as protein radius of gyration, has not stabilized, or the calculated uncertainty seems unreasonably small.
Solutions:
- Check Correlation Times: Calculate the statistical inefficiency or integrated autocorrelation time (( \tau )) for your observables. This measures how long the system "remembers" its previous states. Use this to determine the number of statistically independent samples in your trajectory [40].
- Use Block Averaging: Perform block averaging analysis. Split your trajectory into increasingly larger blocks and compute the observable and its uncertainty for each block size. The uncertainty should plateau once the block size is larger than the correlation time, giving you a robust error estimate [40].
- Consider Enhanced Sampling: For small proteins with slow dynamics, normal MD may be insufficient. Consider enhanced sampling methods like Replica Exchange MD (REMD). One study on small proteins (10-46 residues) found that while normal MD could sometimes predict native-like structures, REMD can improve sampling efficiency [41].
Issue 2: Estimating Uncertainty for Correlated Trajectory Data
Problem: You have a long trajectory, but the data points are highly correlated in time. Using the formula ( s(\bar{x}) = s(x)/\sqrt{n} ) gives an unrealistically small error estimate because it assumes all n data points are independent.
Solutions:
- Account for Correlations: Do not use raw, correlated data to construct statistical estimates. The effective number of independent samples is ( n{eff} = n / (2\tau) ), where ( \tau ) is the correlation time. The correct standard uncertainty of the mean is then ( s(\bar{x}) = s(x)/\sqrt{n{eff}} ) [40].
- Employ Advanced UQ Methods: Newer UQ methods, such as those based on Bayesian inference or Polynomial Chaos expansions, can be more effective at handling correlated data and providing robust uncertainty estimates compared to traditional methods [40] [42].
The Scientist's Toolkit: Research Reagent Solutions
Table 1: Essential Computational Tools for UQ in MD
| Item | Function in UQ Analysis |
|---|---|
| Statistical Inefficiency Calculator | Determines the correlation time (( \tau )) of a time series, which is essential for identifying the number of uncorrelated samples [40]. |
| Block Averaging Script | Automates the process of dividing a trajectory into blocks to compute a converged estimate of the standard uncertainty of the mean [40]. |
| Replica Exchange MD (REMD) | An enhanced sampling method that helps overcome energy barriers and improves phase-space sampling, which is particularly useful for small proteins with folding/unfolding transitions [41]. |
| Bayesian Inference Software (e.g., PyMC) | Provides a framework for rigorously quantifying parametric uncertainty and inverse problems by combining prior knowledge with simulation data [43] [42]. |
| Polynomial Chaos (PC) Expansion Tools | A forward propagation method used to characterize how uncertainty in model parameters (e.g., force field terms) affects simulation observables [42]. |
Experimental Protocols & Data Presentation
Example Workflow: UQ for a Small Protein Folding Simulation
The following workflow is adapted from studies validating MD's ability to predict structures of small proteins like Trp-cage (20 residues) and Chignolin (10 residues) [41].
1. System Setup:
- Protein: Start with a native or denatured structure (e.g., from PDB).
- Solvation: Solvate the protein in an explicit water box (e.g., TIP3P model).
- Force Field: Choose an appropriate force field (e.g., AMBER, CHARMM).
- Neutralization: Add ions to neutralize system charge.
2. Simulation Production:
- Protocol: Run a minimum of 3-5 independent MD simulations (or REMD) from different initial conditions. For proteins of ~20 residues, simulation lengths of 200 ns or more are often used [41].
- Controls: Ensure stability by monitoring temperature, pressure, and energy.
3. Trajectory Analysis and UQ:
- Observable Calculation: For each trajectory, compute your observable of interest (e.g., RMSD to native structure) over time.
- Check for Stationarity: Visually inspect the time series and its running average to ensure the simulation has reached a steady state.
- Quantify Uncertainty:
- For each independent simulation, calculate the correlation time (( \tau )) for the observable.
- Compute the experimental standard deviation of the mean (( s(\bar{x}) )) using the effective sample size ( n_{eff} ) to account for correlations [40].
- Report the final result as the mean ± standard uncertainty across the independent simulations.
Quantitative Performance of MD for Small Proteins
Table 2: Validation of MD Simulations for Predicting Small Protein Structures This table summarizes results from a study that evaluated the ability of MD simulations to predict the 3D structures of small proteins with known experimental structures. The Root Mean Square Deviation (RMSD) is a key metric for comparing predicted and experimental structures [41].
| Protein (Residues) | Simulation Length | Minimum RMSD (Å) | Key Finding / Reproducible Secondary Structure? |
|---|---|---|---|
| Chignolin (10) | 200 ns | < 2.0 Å | Yes, structure closely approximated. |
| CLN025 (10) | 200 ns | < 2.0 Å | Yes, structure closely approximated. |
| Trp-cage (20) | 200 ns | < 2.0 Å | Yes, structure closely approximated. |
| HPH (34) | 2000 ns | < 1.0 Å | Yes, with longer simulation. |
| Crambin (46) | 2000 ns | > 3.0 Å | Difficult to apply to >40 residue proteins. |
Automated Workflows and Hybrid Docking-MD Pipelines for Efficiency
Frequently Asked Questions (FAQs)
FAQ 1: What are the main advantages of using a hybrid docking-MD pipeline over docking alone? Molecular docking alone often treats the receptor as rigid, which can lead to incorrect pose predictions when the binding mechanism involves induced fit [44]. A hybrid pipeline that integrates molecular dynamics (MD) simulations addresses this limitation by allowing both the ligand and the protein to move flexibly, sampling more biologically relevant conformations [44]. MD can be used as a post-docking step to refine the docked poses and account for full flexibility, or as a pre-docking step to generate an ensemble of multiple receptor conformations for docking, thereby providing a more realistic model of the binding event [44].
FAQ 2: Which enhanced sampling methods are best suited to overcome sampling limitations in small protein simulations? The choice of enhanced sampling method depends on your system and the biological property you are studying [1].
- Replica-Exchange MD (REMD) is highly effective for studying folding mechanisms and free energy landscapes of peptides and small proteins [1]. It involves running multiple parallel simulations at different temperatures and periodically exchanging system states, facilitating a random walk in temperature and energy space to escape local energy minima [1].
- Metadynamics is well-suited for studying biomolecular dynamics, protein folding, and conformational changes by "filling" free energy wells with computational "sand," which discourages re-sampling of previously visited states and encourages exploration of new ones [1]. Its effectiveness depends on selecting a small set of appropriate collective coordinates [1].
- Monte Carlo (MC) Methods offer a powerful alternative for extensive thermodynamic characterization, as they have no inherent timescale limitation [14]. All-atom MC simulations with implicit solvent can efficiently sample the conformational landscape of small proteins, allowing for the full characterization of free energy landscapes, transition states, and energy barriers [14].
FAQ 3: My docking results show many false positives. What controls can I implement to improve reliability? False positives are a common challenge in virtual screening. To improve the reliability of your results:
- Use control (decoy) docking calculations to evaluate your docking parameters before running a large-scale screen [45].
- Employ machine learning (ML) classifiers to reduce false positives after the initial docking screen. ML models can be trained to distinguish true binders from non-binders based on various molecular features [45].
- Always validate docking hits experimentally to confirm specific activity [45]. Do not rely solely on docking scores.
FAQ 4: What are the most common mistakes when setting up a production MD simulation? Common mistakes often involve incorrect parameter settings during the setup phase [46]:
- Mismatched temperature and pressure parameters: Ensure the settings for temperature and pressure coupling in your production run match those used and reached during your NVT and NPT equilibration steps [46].
- Forgotten constraints: Check that all intended constraints (e.g., on backbone atoms) are correctly applied before starting the production run [46].
- Incorrect input paths: When continuing from an equilibration step, use an "Auto-fill" feature if available to automatically populate the input path and avoid manual errors [46].
FAQ 5: How can I automate my docking and MD workflows to increase efficiency? Automation can save time and reduce errors. Several strategies exist:
- Integrated Computational Pipelines: Tools like the M01 tool automate the entire workflow from hybrid molecule generation to docking simulations by integrating established software like RDKit and EasyDock into a user-friendly platform [47].
- Workflow Orchestration Tools: Use tools like Apache Airflow, Prefect, or Luigi to define, schedule, and manage task dependencies in your data pipeline. These tools allow you to run independent tasks in parallel, handle failures with retries, and ensure reproducible workflows [48].
- LLM-Powered Agents: Emerging frameworks use Large Language Models (e.g., Gemini) to automate the preparation of MD input files through web interfaces like CHARMM-GUI, generating simulation scripts and managing the entire setup process with minimal human intervention [49].
Troubleshooting Guides
Issue 1: Poor Sampling and Inadequate Conformational Coverage
Problem: Your simulation is trapped in a local energy minimum and fails to sample all functionally relevant conformational substates.
Solutions:
- Implement Enhanced Sampling:
- REMD: Ensure you select an appropriate temperature range. The maximum temperature should be chosen slightly above the point where the enthalpy for folding vanishes for optimal efficiency [1].
- Metadynamics: Carefully select one or two physically meaningful collective variables (CVs) that describe the transition of interest, such as a distance or a dihedral angle [1].
- Consider Alternative Methods:
- Use Generalized Simulated Annealing (GSA), which is well-suited for characterizing very flexible systems and can be applied to large macromolecular complexes at a relatively low computational cost [1].
- Employ Monte Carlo (MC) simulations with an all-atom force field and implicit solvent. This approach bypasses the femtosecond timestep limitation of MD and can provide extensive thermodynamic data on protein folding [14].
Table: Comparison of Enhanced Sampling Methods for Small Proteins
| Method | Key Principle | Best For | Considerations |
|---|---|---|---|
| REMD [1] | Parallel simulations at different temperatures exchange states. | Studying free energy landscapes & folding mechanisms. | Efficiency sensitive to the maximum temperature choice. |
| Metadynamics [1] | Biases simulation with repulsive potentials to discourage revisiting states. | Exploring conformational changes & protein-ligand interactions. | Requires pre-defined Collective Variables (CVs). Accuracy depends on CV choice. |
| Simulated Annealing [1] | Gradual cooling of the system to find low-energy states. | Characterizing very flexible systems & large complexes. | A variant, GSA, is more efficient for large systems. |
| Monte Carlo [14] | Accepts/rejects random moves based on energy change; no timescale. | Thermodynamic characterization & overcoming time barriers. | Does not provide direct kinetic information. |
Issue 2: Docking Poses are Unrealistic or Lack Biological Relevance
Problem: The predicted ligand binding modes from docking are incorrect or do not agree with experimental data.
Solutions:
- Incorporate Receptor Flexibility:
- Validate and Control Your Docking Protocol:
- Check Ligand Preparation:
- Ensure the protonation states of your ligands are correct at the relevant pH (e.g., 7.4) using a tool like
pkasolver[47].
- Ensure the protonation states of your ligands are correct at the relevant pH (e.g., 7.4) using a tool like
Issue 3: Simulation or Workflow Failure Due to Technical Errors
Problem: The simulation crashes, or the automated pipeline fails to execute properly.
Solutions:
- Increase Logging Verbosity: When using tools like
openfe, configure the logging toDEBUGlevel to get more detailed output, which can help identify the exact point and reason for failure [50]. - Double-Check Simulation Parameters:
- Before starting a production MD run, meticulously check that all parameters (temperature, pressure, constraints) are correctly carried over from equilibration steps [46].
- Use the "Reset" button in your MD software's advanced parameters window to return to safe defaults if you are unsure of custom settings [46].
- Optimize Your Computational Pipeline:
- Filter Data Early: Apply filtering operations as close to the data source as possible to reduce the amount of data processed downstream [48].
- Leverage Parallelism: Use multithreading, multiprocessing, or distributed computing frameworks (like Apache Spark) to run independent tasks concurrently and speed up compute-intensive workloads [48].
Workflow Diagram for a Hybrid Docking-MD Pipeline
Enhanced Sampling Decision Diagram
The Scientist's Toolkit: Research Reagent Solutions
Table: Essential Software and Tools for Hybrid Docking-MD Pipelines
| Tool Name | Category | Primary Function | Application Note |
|---|---|---|---|
| M01 Tool [47] | Automated Workflow | Integrated pipeline for generating small molecule-peptide hybrids and docking. | Automates receptor prep (via PDB/UniProt ID), hybrid generation with RDKit, and docking via EasyDock. Ideal for users with limited chemistry expertise. |
| RDKit [47] | Cheminformatics | Open-source toolkit for cheminformatics and molecule manipulation. | Used in pipelines like M01 for generating molecular hybrids, converting SMILES to 3D structures, and molecular sanitization. |
| AutoDock Vina/SMINA [47] [45] | Molecular Docking | Docking program to predict ligand binding modes and affinities. | A standard for docking screens. SMINA is a variant with enhanced scoring and customization. |
| CHARMM-GUI [49] | MD Setup | Web-based interface for setting up complex simulation systems. | Simplifies building systems for various MD engines (NAMD, GROMACS, AMBER). Can be automated via LLM agents. |
| GROMACS [46] [49] | MD Engine | High-performance molecular dynamics package. | Widely used for simulating proteins, lipids, and nucleic acids. Known for its high performance. |
| NAMD [49] | MD Engine | Parallel molecular dynamics code. | Designed for high-performance simulation of large biomolecular systems. |
| AMBER [1] [14] | MD Engine/MC Force Field | Suite of biomolecular simulation programs. | Includes MD software and force fields (e.g., AMBER99SB*-ILDN) used in both MD and Monte Carlo simulations [14]. |
| Apache Airflow [48] | Workflow Orchestration | Platform to programmatically author, schedule, and monitor workflows. | Manages complex data pipelines, handles task dependencies, and enables parallel execution of independent tasks. |
Overcoming Force Field and Implicit Solvent Model Limitations
Frequently Asked Questions
Q1: My implicit solvent model gives inaccurate solvation free energies, making absolute free energy comparisons unreliable. What's wrong? A primary limitation of many machine learning (ML) implicit solvent models is their reliance on a pure force-matching training approach. This method determines potential energies only up to an arbitrary constant, rendering them unsuitable for comparing absolute free energies across different chemical species [51]. A novel solution is the λ-Solvation Neural Network (LSNN), which extends the training procedure. Instead of just force-matching, it is also trained to match derivatives with respect to alchemical variables (λsteric and λelec). This ensures the model learns a conservative vector field, allowing its scalar potential to accurately represent the true Potential of Mean Force (PMF) for meaningful free energy comparisons [51].
Q2: How can I access more accurate potentials for biomolecular simulations without the cost of high-level quantum calculations? Utilize recently released, massive-scale neural network potentials (NNPs) pre-trained on high-accuracy computational data. For instance, Meta's Open Molecules 2025 (OMol25) dataset contains over 100 million quantum chemical calculations performed at the ωB97M-V/def2-TZVPD level of theory, a high-accuracy standard [52]. Pre-trained models like the Universal Model for Atoms (UMA) and eSEN models are available on platforms like HuggingFace. These models have been shown to provide better energies than affordable DFT levels and enable simulations on large systems previously considered intractable [52].
Q3: Force fields struggle with the conformational sampling of Intrinsically Disordered Proteins (IDPs). Are there efficient alternatives? Yes, Artificial Intelligence (AI) methods now offer a transformative alternative to traditional Molecular Dynamics (MD) for sampling IDP ensembles. Deep learning models can learn complex sequence-to-structure relationships from large datasets, allowing them to efficiently generate diverse conformational ensembles without the computational cost of long MD simulations. These AI approaches can outperform MD in generating ensembles with comparable accuracy and are particularly useful for capturing rare, transient states [11] [53]. For the best results, consider hybrid approaches that integrate these AI-generated ensembles with physics-based MD simulations to ensure thermodynamic feasibility [11].
Q4: Setting up MD simulations for complex systems is time-consuming and error-prone. How can this process be streamlined? Leverage automation tools that use Large Language Models (LLMs). Frameworks like NAMD-Agent employ LLMs (e.g., Gemini-2.0-Flash) in a ReAct (Reasoning and Acting) paradigm to automate the preparation of simulation input files through web interfaces like CHARMM-GUI [49]. This agent can interpret user commands, write and execute code to navigate the setup website, extract parameters, and produce the required input files, significantly reducing setup time and minimizing manual errors [49].
Troubleshooting Guides
Issue: Inaccurate Hydration Free Energy Predictions
A root-mean-square error (RMSE) above 1 kcal/mol for hydration free energy calculations indicates a lack of "chemical accuracy," which is critical for reliable drug discovery applications [54].
Solution: Adopt a modern charge model and force field combination.
The combination of the GAFF2 force field with the ABCG2 charge model has been demonstrated to achieve milestone accuracy. On the standard FreeSolv database (642 solutes), this combination achieved an RMSE of 0.99 kcal/mol, meeting the chemical accuracy threshold [54].
Protocol: Hydration Free Energy Calculation with GAFF2/ABCG2
- Charge Assignment: Generate partial atomic charges for your organic solute molecule using the ABCG2 charge model. This model allows for instantaneous charge assignment and shows smaller fluctuations across different input conformations compared to traditional methods like RESP [54].
- Force Field Assignment: Apply the GAFF2 parameters to the solute.
- System Setup: Solvate the solute in a pre-equilibrated water box (e.g., TIP3P) using a tool like
tleapfrom AmberTools. - Simulation & Analysis: Perform an alchemical free energy calculation (e.g., using Thermodynamic Integration or Multistate Bennett Acceptance Ratio) to compute the free energy change of transferring the solute from gas phase to water.
Issue: Inadequate Conformational Sampling
Traditional MD simulations can be computationally expensive and struggle to sample the full conformational landscape, especially for flexible systems like IDPs, within practical timeframes [11].
Solution: Implement a hybrid AI-MD sampling workflow.
This protocol uses a deep learning model to rapidly generate a diverse initial ensemble, which is then refined and validated using shorter, targeted MD simulations and experimental data [11].
Protocol: Hybrid AI-MD Sampling for IDPs
- Deep Learning Sampling:
- Input the protein sequence into a specialized deep learning model for conformational ensemble generation (e.g., a graph neural network trained on IDP data).
- The model rapidly generates a diverse set of plausible structures, exploring a broader conformational space than might be accessible via MD alone.
- Ensemble Refinement with MD:
- Use the AI-generated structures as starting points for multiple, shorter MD simulations.
- This step refines the structures and ensures they are thermodynamically feasible within a physics-based force field.
- Validation with Experimental Data:
- Validate the final refined ensemble by comparing back-calculated averaged experimental observables (e.g., from NMR or SAXS data) with actual measurements to ensure the ensemble's accuracy [11].
Issue: Model Forces are Non-Conservative
Using a neural network potential (NNP) with a direct-force prediction head can sometimes lead to non-conservative forces, making molecular dynamics simulations and geometry optimizations unstable [52].
Solution: Use a model trained with a conservative-force prediction objective.
The eSEN architecture from Meta's FAIR team addresses this by employing a two-phase training scheme [52].
Protocol: Ensuring Conservative Forces with eSEN
- Model Selection: Select a pre-trained eSEN conservative-force model (e.g., the small conservative-force eSEN model available on HuggingFace) [52].
- Inference for MD: When performing geometry optimizations or molecular dynamics, the forces computed by this model will inherently be conservative, leading to better-behaved and more stable simulations [52].
The table below quantifies the accuracy of modern methods for overcoming classic force field and solvation limitations.
Table 1: Benchmarking Accuracy of Advanced Methods for Solvation and Energy Prediction
| Method / Model | Benchmark | Key Metric | Reported Performance | Significance |
|---|---|---|---|---|
| GAFF2/ABCG2 [54] | Hydration Free Energy (FreeSolv, 642 solutes) | Root-Mean-Square Error (RMSE) | 0.99 kcal/mol | Meets the "chemical accuracy" threshold (≤1 kcal/mol) for the first time with a physics-based model on this benchmark. |
| LSNN Implicit Solvent [51] | Solvation Free Energy | Accuracy vs. Explicit Solvent | Comparable to explicit-solvent alchemical simulations | Provides explicit-solvent accuracy with a significant computational speedup. |
| OMol25-trained NNP (eSEN) [52] | Molecular Energy Benchmarks (e.g., GMTKN55) | Accuracy vs. DFT | Matches high-accuracy DFT performance | Provides high-level quantum chemistry accuracy at a fraction of the computational cost. |
The Scientist's Toolkit
Table 2: Essential Research Reagents and Computational Resources
| Item / Resource | Function / Application | Key Feature |
|---|---|---|
| OMol25 Dataset [52] | Training or fine-tuning machine learning potentials for atoms and molecules. | Massive dataset (100M+ calculations) with high ωB97M-V accuracy and unprecedented chemical diversity (biomolecules, electrolytes, metal complexes). |
| Pre-trained UMA/eSEN Models [52] | Ready-to-use neural network potentials for molecular modeling. | Unifies multiple datasets; offers superior accuracy and energy conservation for dynamics simulations. Available on HuggingFace. |
| ABCG2 Charge Model [54] | Assigning partial atomic charges for organic molecules in GAFF2 force field simulations. | Enables chemical accuracy in hydration free energy predictions; low conformational dependence. |
| λ-Solvation Neural Network (LSNN) [51] | Implicit solvent model for accurate free energy calculations. | Graph neural network trained on derivatives of alchemical variables, enabling absolute free energy comparisons. |
| NAMD-Agent [49] | Automated setup of molecular dynamics simulation input files. | LLM-powered agent (Gemini-2.0-Flash) that automates workflow via CHARMM-GUI, reducing setup time and errors. |
| Hybrid AI-MD Sampling Workflow [11] | Efficiently generating conformational ensembles for Intrinsically Disordered Proteins (IDPs). | Combines deep learning for broad sampling with MD for physical refinement and experimental validation. |
Strategies for Sampling Rare, Transient, and Functionally Relevant States
Frequently Asked Questions (FAQs)
FAQ 1: What are rare events in molecular dynamics, and why are they important? Rare events are conformational transitions, such as protein folding, unfolding, or ligand (un)binding, that occur on timescales much longer than the typical dwell time in metastable states. While the transitions themselves are fast, the waiting time between them can be prohibitively long for conventional MD simulations. These events are often precisely the functionally relevant processes researchers want to study [6] [55].
FAQ 2: How do path sampling methods differ from conventional MD? Conventional MD simulations run a single, continuous trajectory, spending most of the computational resources dwelling in stable states. In contrast, path sampling approaches focus computing effort specifically on the transitions of interest. They generate an ensemble of transition trajectories, enabling the calculation of rate constants and the mechanistic study of transitions that would be impractical to observe with straight-ahead MD [6] [55].
FAQ 3: What is the main challenge in applying enhanced sampling methods? A central challenge is the identification of optimal collective variables (CVs) or reaction coordinates. These are low-dimensional descriptors that characterize the progress of the transition. Sub-optimal CVs can severely affect sampling efficiency and the accuracy of the resulting mechanistic understanding [39] [56].
FAQ 4: Can I use these methods without knowing the reaction coordinate in advance? Yes, several modern strategies address this. Machine learning approaches, such as the AMORE-MD framework, can learn a reaction coordinate directly from simulation data without a priori knowledge [8]. Other methods, like Evolutionary Couplings-guided Adaptive Sampling (ECAS), use bioinformatic data from protein sequences to inform natural reaction coordinates [2].
FAQ 5: What are the common limitations of path-sampling methods? A common limitation is the correlation between generated trajectories, which reduces statistical independence and can lead to undersampling. Furthermore, all methods require careful parameter tuning, and their software implementations may present a learning curve. Critically analyzing results for sampling quality is essential [6].
Troubleshooting Guides
Issue 1: Poor Convergence and Sampling of Transition Paths
Problem: Your simulation fails to observe the rare event of interest, or the sampled pathways are highly correlated and do not represent the true ensemble of transitions.
Solutions:
- Utilize Direction-Guided Sampling: For ligand unbinding or folding, consider methods like PathGennie. This framework launches swarms of ultrashort, unbiased trajectories and selectively propagates only those showing progress toward a defined goal, rapidly generating physically meaningful pathways [57].
- Implement Iterative Retraining: When using machine-learned reaction coordinates, adopt an iterative sampling and retraining strategy. Use an initially learned coordinate to guide new simulations, which in turn generate new data to improve the reaction coordinate. This enhances coverage of rare transition states [8].
- Leverage Quantum Annealing for Uncorrelated Paths: To overcome the challenge of path correlation, a hybrid MD/quantum computing algorithm can be employed. The quantum annealer, re-initialized at each step, generates viable and uncorrelated transition paths at every iteration, aiding in exploring the path ensemble [56].
- Apply the Weighted Ensemble (WE) Method: Use WE to improve sampling efficiency. The system's configuration space is divided into bins, and unbiased trajectories are run in parallel. Trajectories that progress into new bins are replicated, encouraging progress toward the target state while statistical weighting ensures unbiased results [6].
Issue 2: Selecting and Validating Collective Variables (CVs)
Problem: The chosen collective variables are not sufficient to describe the transition mechanism, leading to inefficient sampling or incorrect mechanistic conclusions.
Solutions:
- Incorporate Evolutionary Couplings: Use distances between evolutionarily coupled residues as natural CVs. These pairs, identified from multiple sequence alignments, often form contacts critical for function. The sum of their distances (ΔSEC) can be used in adaptive sampling schemes to guide simulations toward functional conformations [2].
- Employ Explainable AI (XAI) Techniques: For deep-learned reaction coordinates, use gradient-based sensitivity analysis. Frameworks like AMORE-MD can quantify atomic contributions to the learned coordinate, providing a transparent and chemically interpretable view of which atoms or distances drive the transition [8].
- Benchmark with Well-Understood Systems: Validate your CVs and method on a small benchmark system with known properties, such as alanine dipeptide or the Trp-cage miniprotein. Successful recovery of known mechanisms builds confidence before applying the approach to novel systems [29] [8].
Issue 3: High Computational Cost of Transition Sampling
Problem: The computational resources required to generate a sufficient number of uncorrelated transition events are prohibitively high.
Solutions:
- Adopt a Path Sampling Method Suited to Your System: Choose a method that aligns with your system's characteristics. For instance, milestoning has been used to simulate millisecond conformational transitions in enzymes like HIV reverse transcriptase, while transition interface sampling (TIS) and forward flux sampling (FFS) are designed for efficient rate constant calculations [6].
- Use Adaptive Sampling: Instead of running a few long simulations, run many short, independent simulations in parallel. Analyze them on-the-fly (e.g., with a Markov State Model) and use the results to seed new simulations from promising conformations, thereby reducing time spent on already sampled states [2].
- Integrate Coarse-Graining: Develop a coarse-grained representation of the dynamics based on an initial exploration of the configuration space (e.g., using Intrinsic Map Dynamics). Sampling can then be performed on this low-resolution manifold, significantly reducing the computational cost [56].
Comparison of Key Path Sampling Methods
The table below summarizes several major path sampling strategies to aid in method selection.
| Method Name | Category | Key Principle | Example Applications |
|---|---|---|---|
| Transition Path Sampling (TPS) [6] [55] | Methods using complete paths | Monte Carlo sampling in trajectory space; new paths generated by perturbing existing ones (e.g., via shooting moves). | Protein folding, conformational changes. |
| Weighted Ensemble (WE) [6] | Region-to-region (Bin-to-bin) | Runs parallel trajectories; replicates those that progress into new bins while using statistical weights to maintain unbiased kinetics. | Conformational transitions in membrane transporters, ion channel permeation. |
| Transition Interface Sampling (TIS) / Forward Flux Sampling (FFS) [6] | Interface-to-interface | Calculates flux through a series of interfaces between states; TIS uses TPS between interfaces, while FFS uses standard simulations. | Protein folding, binding/unbinding. |
| Milestoning [6] [39] | Interface-to-interface | Uses a set of milestones (hypersurfaces) to calculate the kinetics of a process by integrating many short simulations between them. | Large conformational changes in HIV reverse transcriptase. |
| Metadynamics [39] | Enhanced Sampling | Adds a history-dependent bias potential in the CV space to discourage the system from revisiting sampled states, thus pushing it over energy barriers. | Exploring free energy surfaces of biomolecules. |
| Replica Exchange MD (REMD) [39] | Enhanced Sampling | Runs parallel simulations at different temperatures; exchanges configurations between them to accelerate barrier crossing. | Peptide folding, structural refinement. |
Experimental Workflow for Path Sampling
The following diagram illustrates a generalized, iterative workflow for applying path sampling and analysis to a biological system, integrating concepts from several modern methodologies.
Research Reagent Solutions
This table lists key computational tools and their roles in sampling rare events.
| Tool / Resource | Function / Role | Relevance to Sampling |
|---|---|---|
| Collective Variables (CVs) | Low-dimensional descriptors of the transition (e.g., distances, angles, RMSD). | Essential for most enhanced sampling methods; defines the progress of the reaction [39]. |
| Markov State Models (MSMs) | A kinetic model built from many short simulations to describe long-timescale dynamics. | Enables the analysis of adaptive sampling data and estimation of equilibrium properties from non-equilibrium simulations [2]. |
| Evolutionary Couplings | Bioinformatically derived residue-residue contacts from multiple sequence alignments. | Provides a data-driven approach to define biologically relevant reaction coordinates without prior structural knowledge [2]. |
| Machine Learning Models (e.g., VAMPnets, ISOKANN) | Neural networks that learn reaction coordinates directly from simulation data. | Discovers intrinsic reaction coordinates without requiring expert intuition or a priori CV selection [8]. |
| Path Sampling Software (e.g., for WE, TPS) | Specialized software packages implementing specific path sampling algorithms. | Provides tested and optimized implementations of complex sampling methodologies [6]. |
Benchmarking Success: Validating and Comparing Sampling Methods
Quantitative Metrics for Conformer Generation Algorithm Comparison
In molecular dynamics (MD) simulations of small proteins and their interactions with ligands, accurately representing the conformational landscape of small molecules is paramount. A significant limitation in this field is the inadequate sampling of conformational space, often due to the rough energy landscapes of biomolecules, which contain many local minima separated by high-energy barriers [1] [39]. This article establishes a technical support framework to help researchers overcome these sampling limitations by providing clear guidelines for evaluating, selecting, and troubleshooting molecular conformer generation algorithms, which are essential for successful computational drug discovery and design [58] [59].
Key Quantitative Metrics for Performance Evaluation
A robust comparison of conformer generation algorithms relies on a set of quantitative metrics that assess different aspects of performance. The table below summarizes the key metrics identified from benchmarking studies.
Table 1: Key Quantitative Metrics for Conformer Generation Algorithms
| Metric Category | Specific Metric | Description and Purpose |
|---|---|---|
| Accuracy | Heavy-atom Root-Mean-Square Deviation (RMSD) | Measures the average distance between atoms in a generated conformer and a reference experimental structure (e.g., from PDB). A lower value indicates higher accuracy [60]. |
| Accuracy | Torsion Fingerprint Deviation (TFD) | A continuous, scale-invariant measure of similarity that compares the torsional angles of conformers, providing a more holistic measure than RMSD [61]. |
| Diversity | Coverage and Recall within an RMSD threshold | Assesses the ability of a generated ensemble to include conformers that are close to all known experimental reference structures [59]. |
| Energetic Quality | Force Field Energy | The internal energy of a generated conformer calculated using a molecular mechanics force field. Lower energies are preferred, indicating more stable, strain-free conformations [61]. |
| Efficiency | Processing Time | The computational time required to generate a conformer ensemble for a given molecule [60]. |
| Efficiency | Number of Energy Evaluations | The number of times the algorithm evaluates the energy of a conformation during its search, which is a hardware-independent measure of computational cost [61]. |
| Robustness | Success Rate | The percentage of molecules in a diverse dataset for which the algorithm successfully produces a valid conformer ensemble [60]. |
| Ensemble Quality | Ensemble Size | The number of unique conformers generated to represent the molecular landscape. This balances completeness with storage and computational overhead [60]. |
Experimental Protocols for Benchmarking
To ensure fair and reproducible comparisons between different conformer generators, follow this standardized experimental protocol.
Dataset Preparation
- Platinum Diverse Dataset: A standard dataset containing high-quality protein-bound ligand conformations extracted from the Protein Data Bank (PDB). It is typically used for benchmarking typical drug-like small molecules [58] [60].
- Cofactorv1 Dataset: A complementary dataset designed to challenge algorithms with high flexibility. It features only seven small molecule cofactors, but each has hundreds to thousands of experimental conformers sourced from the PDB, with 15-29 rotatable bonds per molecule [59] [62].
- Macrocycle Datasets: Specialized datasets for evaluating performance on macrocyclic structures, which present unique challenges due to their constrained ring flexibility [60].
Benchmarking Workflow
The following diagram outlines the logical workflow for conducting a conformer generation benchmark.
Execution and Analysis
- Run Algorithms: Process the selected dataset with all conformer generators to be evaluated, ensuring consistent computational resources.
- Calculate Metrics: For each molecule and each algorithm, compute the metrics listed in Table 1. This often involves scripting (e.g., using Python or provided analysis scripts [59]) to calculate RMSD, TFD, and other values at scale.
- Statistical Comparison: Perform statistical analysis (e.g., averaging results over the entire dataset, creating box plots, or conducting significance tests) to create a robust ranking of the algorithms [58] [59].
Troubleshooting Common Sampling Issues
Table 2: Common Issues and Solutions in Conformer Generation
| Problem | Possible Cause | Solution Guide |
|---|---|---|
| High RMSD toBioactive Structure | Algorithm is trapped in local energy minima and fails to sample the global minimum or relevant states. | Switch to an enhanced sampling method like Moltiverse, which uses eABF and metadynamics to escape local minima [58]. For stochastic methods, increase the number of sampling iterations [61]. |
| Long Computation Times | The conformational search is inefficient, especially for molecules with many rotatable bonds. | For flexible molecules, use stochastic methods (e.g., Bayesian Optimization) that require fewer energy evaluations [61]. For systematic searches, adjust torsion angle increments to be less fine-grained. |
| Lack of Diversity inGenerated Ensemble | The search algorithm is overly exploitative or lacks a mechanism to escape the current basin of attraction. | Use metadynamics, which discourages re-sampling of previously visited states by "filling free energy wells" [1] [39]. Check if the algorithm has a diversity-maximizing mode. |
| Poor Performance onMacrocycles | Standard torsion-driven methods struggle with the coupled torsions of macrocyclic rings. | Employ specialized algorithms proven on macrocycles, such as CONFORGE, RDKit's ETKDG, or Moltiverse, which has shown high accuracy for these challenging systems [58] [60]. |
Frequently Asked Questions (FAQs)
Q1: Which conformer generation method is best for handling highly flexible molecules with more than 15 rotatable bonds? For highly flexible molecules, enhanced sampling MD methods and advanced stochastic searches are preferable. Moltiverse, which uses extended Adaptive Biasing Force (eABF) and metadynamics, has been specifically benchmarked on the Cofactorv1 dataset containing molecules with 15-29 rotatable bonds and demonstrated high accuracy [58] [59]. Alternatively, Bayesian Optimization (BOA) has been shown to find low-energy minima with far fewer energy evaluations than systematic search for molecules with multiple rotatable bonds [61].
Q2: My goal is to find the single lowest-energy conformation, not a diverse ensemble. Which metric and method should I prioritize? You should prioritize metrics related to energetic quality, specifically the force field energy of the generated conformers [61]. For methods, consider algorithms designed for global minimum search rather than ensemble diversity. Bayesian Optimization (BOA) is explicitly designed to find the lowest-energy conformation with high efficiency, as it intelligently samples the potential energy surface [61].
Q3: Why might a physics-based method like Moltiverse be more effective for certain systems than knowledge-based methods? Knowledge-based methods rely on torsion angle libraries derived from existing experimental databases (e.g., CSD, PDB). They can fail for novel molecules or transition states that are not well-represented in these libraries [60] [63]. Physics-based methods like Moltiverse use molecular mechanics force fields and enhanced sampling to explore the energy landscape from first principles, making them more generalizable to a wider range of molecular complexities, including challenging flexible and macrocyclic systems [58].
Q4: What is the practical difference between systematic and stochastic sampling approaches?
- Systematic Search: Deterministically enumerates torsion angles. It is fast and exhaustive for molecules with a small number of rotatable bonds but suffers from combinatorial explosion as flexibility increases [60] [61].
- Stochastic Search: Randomly samples torsion angles (e.g., using Monte Carlo, Distance Geometry, or Bayesian Optimization). It is more suitable for molecules with high flexibility or macrocycles, as it can generate representative ensembles with fewer iterations, though it may be harder to guarantee thorough sampling [60] [61].
Visualization of Algorithm Categories and Relationships
Understanding the relationships between different algorithmic approaches can help in selecting the right tool. The following diagram categorizes common methods.
Table 3: Key Software and Data Resources for Conformer Generation Research
| Resource Name | Type | Function and Explanation |
|---|---|---|
| Moltiverse | Software Tool | An open-source conformer generator using enhanced sampling MD (eABF/metadynamics). It is particularly effective for flexible and macrocyclic molecules [58] [59]. |
| CONFORGE | Software Tool | An open-source generator that uses a systematic approach, delivering state-of-the-art performance for drug-like molecules and macrocycles [60]. |
| RDKit (ETKDG) | Software Tool | A widely used open-source cheminformatics toolkit. Its ETKDG method combines knowledge-based torsion preferences with distance geometry for stochastic conformer generation [60] [61]. |
| Bayesian Optimization (BOA) | Algorithm | A stochastic search strategy that builds a surrogate model of the energy landscape to find low-energy minima with very few evaluations, ideal for finding global minima [61]. |
| Platinum Diverse Dataset | Benchmark Data | A standard dataset of protein-bound ligand conformations used to evaluate the accuracy of conformer generators on drug-like molecules [58] [60]. |
| Cofactorv1 Dataset | Benchmark Data | A complementary dataset featuring highly flexible small molecules with a massive number of experimental conformers per molecule, useful for stress-testing algorithms [59] [62]. |
Benchmarking Against Long-Timescale MD and Experimental Data
Frequently Asked Questions (FAQs)
Q1: What are the most effective enhanced sampling methods for simulating small proteins?
For small proteins, Replica-Exchange Molecular Dynamics (REMD) and metadynamics are among the most adopted and effective sampling methods [1] [39]. REMD runs multiple parallel simulations at different temperatures and allows exchanges between them, facilitating escape from local energy minima [1]. Metadynamics enhances sampling by adding a bias potential to discourage revisiting previously explored states, effectively "filling in" free energy wells to encourage exploration of new configurations [1] [39].
Q2: How can I objectively compare my novel machine-learned molecular dynamics method against existing approaches?
A standardized benchmarking framework is essential for a fair comparison. You should evaluate your method against a common ground-truth dataset using a consistent set of observables and metrics [64]. A proposed framework uses Weighted Ensemble (WE) sampling with progress coordinates from Time-lagged Independent Component Analysis (TICA) to ensure broad conformational coverage [64]. The evaluation should include a suite of metrics, such as:
- Structural Fidelity: Root Mean Square Deviation (RMSD), radius of gyration, and contact maps [64].
- Slow-mode Accuracy: Analysis of slow dynamical processes [64].
- Statistical Consistency: Quantitative divergence metrics like Wasserstein-1 and Kullback-Leibler divergences for bond lengths, angles, and dihedrals [64].
Q3: My simulation seems trapped in a non-functional conformational state. What can I do?
This is a common problem due to the rough energy landscapes of biomolecules, which contain many local minima separated by high-energy barriers [1] [39]. Implementing an enhanced sampling algorithm like Generalized Simulated Annealing (GSA) can be particularly well-suited for driving the system out of these deep minima and characterizing highly flexible systems [1] [39]. GSA employs an artificial temperature that decreases during the simulation, helping the system find lower-energy, functionally relevant conformations [1].
Q4: What are the critical checks before starting a production MD simulation to avoid common errors?
Before launching a production run, always double-check the following [46]:
- Temperature and Pressure Coupling: Ensure parameters match those used and validated during the equilibration steps (NVT and NPT).
- Constraint Settings: Verify that all bonds involving hydrogen are properly constrained and that the chosen algorithm (e.g., SHAKE) is correctly configured to avoid convergence failures [64] [65].
- Input File Paths: Use auto-fill features where available to prevent manual path errors that can break the simulation setup [46].
- Advanced Parameters: Review advanced settings, such as those for electrostatic interactions (e.g., Particle Mesh Ewald) and nonbonded cutoffs, to ensure they are appropriate for your system [64] [46].
Troubleshooting Guides
Problem: Inadequate Sampling of Rare Biological Events
Symptoms
- Simulation fails to observe known large-scale conformational changes.
- The system remains trapped in a single conformational substate and does not transition to other known functional states.
- Poor reproducibility of experimental results, such as folding pathways or binding/unbinding events.
Solutions
- Implement Enhanced Sampling: Employ methods like Weighted Ensemble (WE) sampling. This involves running multiple parallel trajectories (walkers) and periodically resampling them based on progress coordinates (e.g., from TICA) to efficiently allocate computational resources toward rare events [64].
- Leverage Standardized Benchmarks: Use a diverse set of small proteins with known folding dynamics to validate your sampling. The table below summarizes a proposed benchmark dataset [64].
| Protein Name | Residues | Predominant Fold | Description |
|---|---|---|---|
| Chignolin [64] | 10 | β-hairpin | Tests basic secondary structure formation |
| Trp-cage [64] | 20 | α-helix | Fast-folding with hydrophobic collapse |
| BBA [64] | 28 | ββα | Mixed secondary structure competition |
| WW domain [64] | 37 | β-sheet | Challenging β-sheet topology |
| Protein G [64] | 56 | α/β | Complex topology formation |
- Validate with Quantitative Metrics: Compute statistical divergences (e.g., Wasserstein-1 distance) between the distribution of properties (e.g., radius of gyration, dihedral angles) from your simulation and a ground-truth reference to quantitatively assess sampling adequacy [64].
Problem: Force Field Inaccuracy Leading to Poor Agreement with Experiment
Symptoms
- Systematic errors in predicted structural properties (e.g., density, bond lengths, coordination numbers) when compared to experimental data or high-level ab initio calculations [66].
- Inaccurate prediction of dynamic properties, such as self-diffusion coefficients and electrical conductivity [66].
- Poor transferability of the force field outside its original parameterization range.
Solutions
- Benchmark Multiple Force Fields: Systematically test different empirical force fields against available experimental data for your specific system. As shown in oxide melt studies, force fields can perform differently for structural versus dynamic properties [66].
- Prioritize Experimentally-Optimized Force Fields: For simulating dynamic properties in non-biological systems, prefer force fields that have been specifically optimized for the relevant phase (e.g., high-temperature liquid phase) and validated against transport properties [66].
- Utilize Ab Initio MD for Validation: Use short, computationally expensive Ab Initio Molecular Dynamics (AIMD) simulations to generate high-accuracy reference data for evaluating the performance of classical force fields on structural properties [66].
Experimental Protocols & Workflows
Protocol: Standardized Benchmarking of MD Methods Using Weighted Ensemble Sampling
This protocol outlines a modular framework for rigorously evaluating MD simulation methods [64].
1. Pre-processing and Ground Truth Data
- Input: Select initial protein structures from the Protein Data Bank (PDB). Repair missing residues, atoms, and termini using a tool like
pdbfixer, and assign protonation states at pH 7.0 [64]. - Ground Truth Generation: Run extensive reference MD simulations. For example, use
OpenMMwith an explicit solvent model (e.g., TIP3P-FB) and an appropriate force field (e.g., AMBER14). Run simulations from multiple starting points (e.g., 1,000,000 steps per point at a 4 fs timestep, 300K) to ensure coverage of conformational space [64].
2. Weighted Ensemble Simulation
- Setup: Use the WESTPA (The Weighted Ensemble Simulation Toolkit) software [64].
- Define Progress Coordinate: Construct a progress coordinate from molecular descriptors (e.g., distances, angles) analyzed using Time-lagged Independent Component Analysis (TICA) [64].
- Propagation: Use a flexible propagator interface to run WE simulations with your chosen MD engine (classical or machine-learned). The system will run multiple walkers, which are periodically resampled based on the progress coordinate.
3. Analysis and Evaluation
- Metric Suite: Compute over 19 different metrics and visualizations, including [64]:
- Global Properties: TICA energy landscapes, contact map differences.
- Local Properties: Distributions for the radius of gyration, bond lengths, angles, and dihedrals.
- Quantitative Divergences: Wasserstein-1 and Kullback-Leibler divergences across all analyses.
The following workflow diagram illustrates the key steps of this benchmarking protocol:
The Scientist's Toolkit: Essential Research Reagents & Software
The table below details key software tools and computational methods essential for conducting and benchmarking advanced molecular dynamics simulations.
| Item Name | Type | Function/Brief Explanation |
|---|---|---|
| WESTPA (Weighted Ensemble Simulation Toolkit) [64] | Software | An open-source implementation of the Weighted Ensemble (WE) sampling strategy, used for enhancing the sampling of rare events in MD simulations. |
| GENESIS (GENeralized-Ensemble SImulation System) [65] | Software | A highly-parallel MD simulator that includes a wide array of enhanced sampling algorithms like replica-exchange (REMD, gREST) and Gaussian accelerated MD (GaMD). |
| OpenMM [64] | Software | A toolkit for MD simulation that includes high-performance GPU acceleration. Often used as a propagation engine in flexible simulation workflows. |
| Time-lagged Independent Component Analysis (TICA) [64] | Algorithm | A dimensionality reduction technique used to identify slow collective variables that serve as optimal progress coordinates for enhanced sampling methods. |
| Ab Initio MD (AIMD) [66] | Method | Uses first-principles quantum mechanics (e.g., Density Functional Theory) to compute forces. Provides high-accuracy reference data but is computationally expensive. |
| Benchmark Protein Set (e.g., Chignolin, Trp-cage) [64] | Dataset | A collection of diverse, well-characterized small proteins used to validate and compare the performance of different MD methods and force fields. |
Frequently Asked Questions
FAQ 1: My AI-generated ensemble lacks diversity and doesn't capture known alternative states. What should I check?
This is a common issue where the model fails to escape the energy basin of the input structure. We recommend a multi-step diagnostic:
- First, verify your input MSA: For MSA perturbation methods (like AFCluster), ensure your Multiple Sequence Alignment is deep and diverse. A shallow MSA limits the conformational diversity the model can explore [67] [68].
- Second, benchmark on a known system: Use a protein from a standardized dataset like ATLAS or mdCATH where the expected ensemble diversity is documented. Compare the RMSD distribution and principal component analysis (PCA) of your generated ensemble to the reference MD data [22].
- Third, try a different model family: If a diffusion model (e.g., AlphaFlow, aSAM) fails, switch to an MSA perturbation method, as they can often predict large-scale, biologically relevant conformational changes more reliably for some targets [67] [68].
- Protocol for Benchmarking Ensemble Diversity:
- Input: Generate 100-500 structures using your AI model of choice.
- Alignment: Superimpose all generated structures and a reference MD trajectory to a common frame.
- Metric Calculation: Compute the Cα Root-Mean-Square Deviation (RMSD) relative to the input structure for all frames.
- Comparison: Plot the distributions of RMSD for your AI ensemble and the reference MD ensemble. A low mean RMSD and failure to cover the MD distribution's tail indicates poor diversity [22].
FAQ 2: When using enhanced sampling, my simulation gets stuck or follows a non-physical path. How can I improve my Collective Variables (CVs)?
This typically indicates poorly chosen CVs that create "hidden barriers" [18].
- Diagnose with a simple CV first: Start with a simple, intuitive CV like the radius of gyration or a known key distance. If this also fails, the issue may be with the simulation setup itself.
- Leverage AI to define CVs: Instead of relying on intuition, use AI methods to inform your CV selection. The AF2RAVE protocol is a robust solution:
- Implement True Reaction Coordinates (tRCs): For the most effective sampling, compute tRCs using methods like the generalized work functional (GWF). These coordinates, which control both conformational changes and energy relaxation, can be derived from energy relaxation simulations starting from a single structure and have been shown to accelerate conformational changes by up to 10^15-fold [18].
FAQ 3: For a new, small protein with no known structures or deep MSA, which approach is more reliable?
In this low-information scenario, AI methods that rely solely on MSAs may fail. Your most reliable option is a hybrid AI-enhanced sampling approach.
- Option A: Physics-based ML Potentials. Use a transferable coarse-grained machine learning potential (e.g., as in Charron et al.), if available for your protein class. These are trained on MD data and can be combined with enhanced sampling without needing a system-specific MSA [67].
- Option B: Enhanced Sampling with Evolutionary Couplings. Even with a shallow MSA, you can compute evolutionary couplings from the available sequences. These coupling-derived distances can be highly effective as CVs for adaptive sampling to discover functional states [2].
- Experimental Protocol for ECAS:
- Compute Couplings: Input your protein sequence into a server like EVCouplings to get a list of evolutionarily coupled residue pairs [2].
- Define the CV: For each simulation frame, calculate ΔSEC, the change in the sum of distances for these coupled pairs relative to a starting structure [2].
- Run Adaptive Sampling: Perform iterative rounds of short MD simulations. After each round, select new starting structures from clusters with the highest ΔSEC values to maximize exploration of conformational space away from the starting point [2].
Performance Comparison on Standardized Datasets
The table below summarizes the quantitative performance of leading AI and Enhanced Sampling methods when evaluated on the ATLAS and mdCATH datasets.
Table 1: Performance Benchmarking on ATLAS and mdCATH Datasets
| Method | Type | Key Metric vs. MD (ATLAS) | Key Metric vs. MD (mdCATH) | Computational Cost | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| AlphaFlow [67] [22] | AI (Generative) | PCC of Cα RMSF: 0.904 [22] | Not fully reported | GPU-minutes for an ensemble | High accuracy in local flexibility (RMSF) [22] | Struggles with multi-state transitions; lower accuracy on side-chain torsions [22] |
| aSAM / aSAMt [67] [22] | AI (Generative) | PCC of Cα RMSF: 0.886 [22] | Captures temperature-dependent ensemble properties [22] | GPU-minutes for an ensemble | Accurate backbone (φ/ψ) and side-chain (χ) torsion distributions [22] | Slightly lower RMSF accuracy than AlphaFlow; requires energy minimization [22] |
| BioEmu [67] | AI (Generative) | Recovers alternative states and local unfolding [67] | Comparable landscape coverage to long MD [22] | High (largest model) | High diversity; predicts folding free energies [67] | Generates backbone-only atoms; side chains require post-processing [67] |
| True Reaction Coordinates (tRCs) [18] | Enhanced Sampling | Not directly benchmarked | Not directly benchmarked | High (requires MD) | 10^5 to 10^15-fold acceleration; generates natural transition paths [18] | Computationally expensive; identifying tRCs is complex [18] |
| ECAS [2] | Enhanced Sampling | Greatly reduced time to sample activation/folding [2] | Not reported | Medium (adaptive sampling) | No biasing forcefields; uses evolutionary info [2] | Requires an MSA; performance depends on coupling quality [2] |
| Coarse-grained ML Potentials [67] | Hybrid (ML+Simulation) | Reproduces free energy landscapes [67] | Not reported | Medium | Directly usable with enhanced sampling; transferable [67] | NN evaluations slower than classical force fields per step [67] |
The Scientist's Toolkit
Table 2: Essential Research Reagents and Computational Resources
| Resource Name | Type | Function in Research | Relevant Use Case |
|---|---|---|---|
| ATLAS [67] [22] | MD Dataset | Provides 300K simulation trajectories for PDB chains; used for training and benchmarking AI ensemble models. | Benchmarking the accuracy of a generated ensemble's local flexibility (RMSF) and diversity. |
| mdCATH [67] [22] | MD Dataset | Contains multi-temperature simulations for thousands of globular domains; used for training temperature-conditioned models. | Validating if a method can recapitulate temperature-dependent protein unfolding or dynamics. |
| Platinum Diverse Dataset [58] | Small Molecule Dataset | A standard benchmark for evaluating conformer generation algorithms for drug-like small molecules. | Testing sampling methods for flexible ligands in a drug discovery context. |
| EVCouplings Server [2] | Web Server | Computes evolutionary couplings from a protein sequence, inferring residue-residue contacts. | Generating reaction coordinates (CVs) for guided adaptive sampling (ECAS). |
| drMD [69] | Software Tool | An automated pipeline for running MD simulations with OpenMM, designed for non-experts. | Quickly setting up and running standard or metadynamics simulations for validation. |
| MSMBuilder [2] | Software Tool | A Python package for constructing Markov State Models (MSMs) from MD simulation data. | Analyzing the kinetics and thermodynamics of simulation trajectories from both MD and AI surrogate models. |
Experimental Protocols
Protocol 1: Benchmarking an AI Generator with ATLAS
This protocol assesses how well an AI-generated ensemble approximates a reference MD ensemble from the ATLAS dataset [22].
- Input Preparation: Select a target protein from the ATLAS test set. Use the provided starting structure as input to your AI model.
- Ensemble Generation: Generate a structural ensemble (N > 100) using the AI model.
- Trajectory Processing: Superimpose all generated structures and the reference MD trajectory to the same frame using the backbone atoms of a stable core.
- Metric Calculation:
- Local Flexibility: Calculate the Cα Root-Mean-Square Fluctuation (RMSF) for both the AI and MD ensembles. Compute the Pearson Correlation Coefficient (PCC) between the two RMSF profiles.
- Global Diversity: Perform Principal Component Analysis (PCA) on the Cα atoms of both ensembles. Project the data onto the first two PCs and visualize the density. Calculate the mean Cα RMSD to the initial structure.
- Torsion Accuracy: Compare the distributions of backbone (φ/ψ) and side-chain (χ) torsion angles using a metric like WASCO-local [22].
- Interpretation: A high PCC for RMSF (>0.9) indicates good local dynamics capture. Overlap in PCA space and similar RMSD distributions indicate good global diversity.
Protocol 2: Enhanced Sampling using AI-Informed Collective Variables
This protocol uses AI-predicted structures to guide enhanced sampling simulations for thorough landscape exploration [67] [18] [68].
- Generate Candidate States: Use an MSA perturbation method (e.g., AFCluster [67]) to generate a diverse set of conformations for your protein sequence.
- Define Collective Variables (CVs): Cluster the AI-generated structures to identify major alternative states. Use the RMSD to these cluster centers as your CVs for enhanced sampling.
- Simulation Setup: Set up a metadynamics or umbrella sampling simulation in a package like OpenMM via drMD [69], biasing the defined RMSD-CVs.
- Run and Analyze: Execute the simulation, ensuring sufficient sampling of all CV values. Use the simulation output to build a free energy landscape and extract representative structures for each metastable state.
- Validation: Compare the simulation-derived ensemble and free energies with any available experimental data (e.g., NMR couplings, SAXS profiles).
Workflow Diagrams
The following diagrams illustrate the core workflows for the two main approaches discussed in this review.
AI vs Enhanced Sampling Workflow
True Reaction Coordinate Enhanced Sampling
Frequently Asked Questions (FAQs)
Q1: My MD simulations are trapped in non-functional conformational states and cannot escape to sample relevant biology. What enhanced sampling methods can help?
The issue of being trapped in local energy minima is a classic sampling problem. Enhanced sampling techniques are specifically designed to address this:
- Replica-Exchange Molecular Dynamics (REMD): This method runs multiple parallel simulations at different temperatures. Periodically, it attempts to exchange the system states between these replicas based on their energies and temperatures. This allows conformations to effectively perform a random walk in temperature space, helping them overcome high energy barriers that are insurmountable in a standard simulation [1].
- Metadynamics: This technique discourages the system from revisiting previously sampled states by adding a small, repulsive "bias" potential to the system's energy landscape. Over time, this "fills up" the free energy wells with "computational sand," forcing the simulation to explore new regions of conformational space [1].
- Simulated Annealing: Inspired by metallurgy, this method involves running a simulation at a high temperature to overcome barriers and then gradually cooling it. A variant, Generalized Simulated Annealing (GSA), is particularly well-suited for exploring the conformational landscape of large macromolecular complexes at a relatively low computational cost [1].
Q2: Are there efficient alternatives to Molecular Dynamics for simulating large-scale conformational changes like protein folding?
Yes, Monte Carlo (MC) methods are a powerful alternative, especially for thermodynamic characterization. Unlike MD, which is constrained by femtosecond timesteps, MC simulations have no inherent timescale. They use stochastic moves to sample configurations, which can be particularly efficient when concentrating on key degrees of freedom like dihedral angles. Modern all-atom MC approaches can be combined with state-of-the-art force fields and implicit solvent models to faithfully reproduce the folding free energy landscapes, transition states, and energy barriers of small proteins, providing a full thermodynamic picture without the extreme computational cost of long MD trajectories [14].
Q3: How can I improve the physical realism and structural accuracy of a low-resolution protein model generated by a prediction algorithm?
Converting a Cα trace or other reduced model into a physically realistic all-atom structure is a common challenge. Dedicated refinement programs like ModRefiner address this through a two-step, atomic-level energy minimization [70]:
- Backbone Construction and Refinement: The algorithm first builds an initial all-atom backbone from the Cα trace and then refines it using a force field that restrains the model to the original global topology while optimizing local geometry, including bond lengths, angles, and Ramachandran plot outliers.
- Side-Chain Refinement: Side-chain atoms are added from a rotamer library and then refined together with the backbone atoms. The force field includes terms to minimize steric clashes and improve hydrogen-bonding networks, resulting in a model with fewer atomic overlaps and more accurate side-chain positions [70].
Troubleshooting Guides
Problem: Inadequate Sampling of Protein Folding Pathways
Issue: Standard Molecular Dynamics (MD) simulations of small proteins fail to observe complete folding events within practical computational timeframes due to the rough energy landscape with many local minima [1].
Solution 1: Employ a Torsion Angle-Centric Approach
- Principle: Reduce the number of degrees of freedom by focusing sampling on the rotation of backbone dihedral angles (φ and ψ), which are the primary drivers of large-scale conformational change, instead of modeling all atomic movements in Cartesian space [71].
- Protocol: The "Torsion Angle Modeling" method involves:
- Identify Residues by Inertia: Calculate the torsional inertia for each residue in the backbone. Residues with smaller rotational inertia will be more responsive to Brownian collisions from solvent molecules [71].
- Sequential Rotation: Rotate the torsion angles of the peptide in the sequence of increasing torsional inertia. The residue with the smallest inertia rotates first while others remain fixed [71].
- Iterate to Convergence: Repeat this sequential swiveling process over multiple passes (e.g., six passes) to systematically search for the conformation with the lowest potential energy [71].
- Expected Outcome: This method has been reported to simulate protein folding pathways a thousand times faster or more than some other methods by leveraging the physical principle of torsional inertia [71].
Solution 2: Leverage Enhanced Sampling Algorithms
- Principle: Use algorithms that artificially enhance the probability of crossing energy barriers to explore the free-energy landscape more comprehensively [1].
- Protocol - Running a REMD Simulation:
- System Setup: Prepare your solvated and equilibrated protein system as for a standard MD run.
- Choose Temperature Range: Start multiple replicas (copies) of the same system, each running at a different temperature. The highest temperature should be chosen to be slightly above the protein's folding transition temperature to ensure efficient unfolding and refolding [1].
- Run and Exchange: Run all replicas in parallel. Periodically, attempt to swap the configurations of two adjacent replicas (e.g., replicas at temperature T1 and T2) based on a Metropolis criterion, which considers their potential energies and temperatures [1].
- Analysis: After the simulation, "re-weight" the trajectories from all temperatures to reconstruct the system's behavior and free-energy landscape at the temperature of interest [1].
The following workflow illustrates how these methods can be integrated into a research pipeline to overcome sampling limitations:
Problem: Non-Physical Local Geometry in Refined Atomic Models
Issue: After converting a low-resolution protein model (e.g., a Cα trace) to a full-atom model, the structure has unphysical distortions, such as poor bond angles, Ramachandran plot outliers, or steric clashes, despite reasonable global topology [70].
Solution: Systematic Refinement with a Hybrid Force Field
- Principle: Apply atomic-level energy minimization using a force field that combines physical energy terms with knowledge-based restraints derived from high-resolution experimental structures [70].
- Protocol (Using ModRefiner as an example):
- Backbone Reconstruction: Build initial backbone atoms (N, Cα, C, O) from the Cα trace using a look-up table derived from high-resolution protein structures to ensure proper initial geometry [70].
- Backbone Energy Minimization: Refine the backbone using a force field that includes:
- Distance Restraint (Erestr): Maintains global topology by restraining Cα distances to the reference model.
- Physical Terms (Elength, Eangle): Penalizes outliers in bond lengths and angles based on Engh and Huber parameters.
- Ramachandran Term (Erama): Reduces the number of torsion angle pairs in disallowed regions.
- Steric Clash Term (Emclash): Minimizes atomic overlaps [70].
- Side-Chain Addition and Refinement: Add side-chain atoms from a rotamer library and refine them together with the backbone using a similar composite force field to optimize side-chain positions and packing [70].
Quantitative Data on Sampling Performance
The table below summarizes key quantitative findings from the literature on the performance of different sampling methods.
| Method | Protein System | Reported Performance / Speed | Key Outcome | Citation |
|---|---|---|---|---|
| Torsion Angle Modeling | 8-residue peptide | >1000x faster than other methods | Obtained an obvious folding pathway by focusing on torsional inertia. | [71] |
| Monte Carlo (All-Atom) | Trp-cage (20 aa) | 200M steps in ~100-180 CPU hours (AMD EPYC) | Extensive thermodynamic characterization of folding landscape on standard hardware. | [14] |
| Replica-Exchange MD (REMD) | Met-enkephalin (penta-peptide) | More efficient than conventional MD when positive activation energy for folding exists. | Effectiveness is sensitive to the choice of maximum temperature. | [1] |
Research Reagent Solutions
This table lists essential computational tools and their functions for researchers tackling sampling problems in protein simulations.
| Reagent / Tool | Function / Application | Key Feature | |
|---|---|---|---|
| ProtTorter / TorsAlign | Implements torsion angle modeling for protein folding simulation. | Focuses on dihedral angles as the primary degree of freedom, leveraging torsional inertia. | [71] |
| ModRefiner | Converts and refines Cα trace models into full-atom models with improved physical realism. | Uses a two-step energy minimization with a hybrid physics- and knowledge-based force field. | [70] |
| AMBER99SB*-ILDN Force Field | An all-atom intramolecular force field for molecular simulations. | Parameterized for accurate simulation of proteins; can be used with both explicit and implicit solvent in MD and MC. | [14] |
| Generalized Born (GB) Implicit Solvent | An approximate model for calculating electrostatic solvation effects. | Significantly accelerates conformational sampling in both MD and MC simulations by replacing explicit solvent molecules. | [14] |
Frequently Asked Questions (FAQs)
1. What is the core sampling problem in molecular dynamics simulations? Biomolecules have rough energy landscapes with many local minima separated by high-energy barriers. Conventional MD simulations can get trapped in these minima, failing to sample all relevant conformational states within practical computational timeframes, which limits the ability to reveal functional properties [1] [39].
2. When should I consider using enhanced sampling methods for my small protein system? You should consider enhanced sampling when studying processes involving large conformational changes, such as protein folding, functional activation (e.g., in GPCRs), or ligand binding, where the timescales of these transitions are beyond the reach of standard MD simulations [39] [2].
3. How do I choose the most suitable enhanced sampling method? The choice depends on your system's characteristics and the property you wish to study. Replica-Exchange MD (REMD) and metadynamics are widely adopted for biomolecular dynamics. Simulated annealing, particularly Generalized Simulated Annealing (GSA), can be a cost-effective option for studying large, flexible macromolecular complexes [39].
4. What are the key cost factors when running these simulations? The primary costs are computational resources and time. For example, a one-microsecond simulation of a ~25,000-atom system can take months on 24 processors. Enhanced sampling methods like REMD require running multiple replicas simultaneously, significantly increasing the computational demand [39].
5. How can I quantify uncertainty and assess the quality of my sampling? Best practices involve a tiered approach: start with feasibility calculations, run simulations, perform semi-quantitative checks for adequate sampling, and finally construct estimates of observables and their uncertainties using statistical techniques. The "experimental standard deviation of the mean" is a key metric for estimating the standard uncertainty of your results [40].
Troubleshooting Guides
Issue 1: Poor Sampling and Trapping in Local Energy Minima
Problem: Your simulation is not adequately exploring the conformational landscape and appears stuck in non-functional states.
Solution: Implement an enhanced sampling algorithm.
- Step 1: Diagnose the roughness of your system's energy landscape. If large amplitude movements are needed for function, enhanced sampling is required [39].
- Step 2: For small proteins, consider Replica-Exchange MD (REMD). This method runs parallel simulations at different temperatures, allowing exchanges between them to escape local minima [1] [39].
- Step 3: If you have prior knowledge of key reaction coordinates, use metadynamics. This method discourages re-sampling of previously visited states by "filling" free energy wells, promoting exploration [1] [39].
- Step 4: For very flexible systems, try Generalized Simulated Annealing (GSA). It uses an artificial temperature that decreases during the simulation, guiding the system toward low-energy states at a relatively low computational cost [39].
Issue 2: Prohibitively High Computational Cost
Problem: The resource requirements for your chosen enhanced sampling method are too high.
Solution: Optimize method selection and parameters.
- Step 1: For REMD, carefully select the maximum temperature range. Setting it too high can make REMD less efficient than conventional MD. A good strategy is to choose the maximum temperature slightly above where the folding enthalpy vanishes [1].
- Step 2: Consider meta-heuristic optimization methods that have recently gained success in supply chain optimization and can be applied to simulation workflows for efficiency [72].
- Step 3: Utilize adaptive sampling schemes like Evolutionary Couplings-guided Adaptive Sampling (ECAS). This uses bioinformatics-derived reaction coordinates to focus sampling on biologically relevant pathways, reducing the time needed to observe rare events [2].
- Step 4: Leverage Markov State Models (MSMs) to analyze data from multiple short simulations, allowing you to extrapolate long-timescale dynamics without continuously running a single, extremely long simulation [2].
Issue 3: Assessing Confidence in Simulation Results
Problem: You are unsure if your simulation has run long enough to produce statistically reliable results.
Solution: Apply rigorous uncertainty quantification (UQ).
- Step 1: Differentiate between random quantities (individual measurements) and the true value (the ideal objective of your simulation) [40].
- Step 2: Calculate the experimental standard deviation of the mean (often called the "standard error") using the formula:
s(x̄) = s(x) / √n, wheres(x)is the standard deviation of your observations andnis the sample size. This estimates the uncertainty in your calculated mean [40]. - Step 3: Account for correlations in time-series data. Molecular simulation data points are often not independent, which must be considered for accurate uncertainty estimates [40].
- Step 4: Report the standard uncertainty alongside any predicted observable. This communicates the confidence in your results and is essential for making actionable decisions based on the simulation [40].
Experimental Protocols & Methodologies
Protocol 1: Implementing Replica-Exchange MD (REMD)
Objective: Enhance conformational sampling for a small protein by escaping local energy minima.
Methodology:
- System Setup: Prepare your protein system (solvation, ionization) as for a standard MD simulation.
- Replica Generation: Create multiple copies (replicas) of your system. Each replica will be simulated at a different temperature. The number of replicas and temperature range must be chosen so that the exchange probability between adjacent temperatures is sufficient (typically 10-20%) [1].
- Parallel Simulation: Run MD simulations for all replicas simultaneously for a short period (e.g., a few picoseconds).
- Coordinate Exchange: Attempt to swap the configurations of two replicas at adjacent temperatures (e.g.,
iandj) based on a Monte Carlo criterion. The exchange probability is determined by their energies (E_i,E_j) and temperatures (T_i,T_j):P_swap = min(1, exp[(β_i - β_j)(E_i - E_j)]), whereβ = 1/k_B T[1].
- Iteration: Repeat steps 3 and 4 for hundreds or thousands of cycles, allowing a random walk in temperature space, which facilitates escape from local minima.
Protocol 2: Evolutionary Couplings-Guided Adaptive Sampling (ECAS)
Objective: Efficiently sample conformational transitions using bioinformatics-derived reaction coordinates.
Methodology:
- Calculate Evolutionary Couplings: Input a multiple sequence alignment of your protein's homologs into a statistical algorithm (e.g., the EVCouplings web server) to identify pairs of residues with strong evolutionary coupling scores. These pairs are inferred to form functionally important contacts [2].
- Initial Sampling: Run an ensemble of short, unbiased MD simulations from a starting structure (e.g., an inactive state).
- Score Frames: For every saved simulation frame, calculate the sum of the distances between all evolutionarily coupled residue pairs identified in step 1. Compare this to a reference structure (e.g., an active state) to compute a ΔSEC score [2].
- Select New Starting Points: Cluster the simulation frames and select structures from clusters with the highest ΔSEC scores (i.e., conformations most different from the reference in the evolutionarily coupled degrees of freedom) [2].
- Iterate: Use the selected structures as starting points for the next round of simulations. Repeat steps 3-5 for multiple rounds.
- Build a Markov State Model (MSM): Combine all simulation data from all rounds to construct an MSM. This model allows you to estimate long-timescale kinetics and equilibrium populations, effectively removing the bias introduced by the adaptive seeding [2].
Table 1: Key Enhanced Sampling Methods for Small Proteins
| Method | Key Principle | Computational Cost | Best Suited For |
|---|---|---|---|
| Replica-Exchange MD (REMD) | Parallel simulations at different temperatures exchange configurations [1] [39]. | High (multiple replicas run in parallel) | Protein folding, peptide dynamics, overcoming moderate energy barriers [1] [39]. |
| Metadynamics | "Fills" free energy wells with a bias potential to discourage revisiting states [1] [39]. | Moderate to High (depends on collective variables) | Protein folding, ligand docking, conformational changes when key reaction coordinates are known [1] [39]. |
| Generalized Simulated Annealing (GSA) | System is "heated" and then gradually cooled to find low-energy states [39]. | Relatively Low | Large, flexible macromolecular complexes and systems with high structural diversity [39]. |
| Evolutionary Couplings-guided Adaptive Sampling (ECAS) | Uses distances from bioinformatics analysis to guide seeding of new simulations [2]. | Moderate (many short, serial simulations) | Sampling activation pathways, protein folding, and protein-protein association without predefined reaction coordinates [2]. |
Table 2: Key Statistical Definitions for Uncertainty Quantification (UQ) [40]
| Term | Definition | Formula |
|---|---|---|
| Arithmetic Mean | Estimate of the true expectation value. | x̄ = (1/n) * Σ(x_j) |
| Experimental Standard Deviation | Estimate of the true standard deviation of a random variable. | s(x) = √[ Σ(x_j - x̄)² / (n-1) ] |
| Experimental Standard Deviation of the Mean | Estimate of the uncertainty in the mean (the "standard error"). | s(x̄) = s(x) / √n |
| Correlation Time | The longest separation in time-series data after which observations can be considered independent. | Critical for accurate UQ, as correlated data points reduce effective sample size. |
Workflow Visualization
Diagram 1: Decision workflow for balancing computational cost and sampling accuracy.
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Software and Computational Tools
| Item | Function | Relevance to Small Protein MD |
|---|---|---|
| MD Software (NAMD, GROMACS, AMBER) | Packages that perform the numerical integration of Newton's equations of motion for all atoms in the system. | The core engine for running both standard and enhanced sampling simulations. Most modern packages have built-in support for methods like REMD and metadynamics [1] [39]. |
| EVCouplings Web Server | A bioinformatics tool that uses multiple sequence alignments to compute evolutionarily coupled residue pairs. | Provides the input (residue pairs and distances) for the ECAS method, allowing for efficient, biology-guided sampling without prior structural knowledge of the target state [2]. |
| MSMBuilder/PyEMMA | Software for constructing Markov State Models (MSMs) from ensemble MD data. | Enposes the analysis of data from adaptive sampling (like ECAS) or large-scale simulation campaigns. Allows for the estimation of long-timescale kinetics and identification of key conformational states [2]. |
| Uncertainty Quantification Scripts | Custom or published scripts for calculating standard errors, correlation times, and other statistical metrics. | Critical for assessing the reliability and convergence of simulations, ensuring that reported results (e.g., free energies, average distances) are presented with appropriate confidence intervals [40]. |
Conclusion
The field of protein simulation is undergoing a transformative shift, moving beyond the inherent limitations of conventional MD through a powerful synergy of physics-based enhanced sampling and data-driven AI methods. The key takeaway is that no single method is a panacea; rather, researchers now have a diverse toolkit from which to select based on their specific protein system, scientific question, and computational resources. The integration of these approaches, guided by rigorous uncertainty quantification and validation against experimental observables, is paramount for obtaining reliable, statistically robust conformational ensembles. Future directions point toward more automated, physically informed generative models and hybrid quantum-mechanical/MD methods. For biomedical research, these advancements are not merely technical—they are pivotal for accurately modeling drug-target interactions, designing allosteric modulators, and understanding the molecular underpinnings of disease, thereby directly accelerating the pace of therapeutic discovery.
References
- 1. Enhanced Sampling Techniques in Molecular Dynamics ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC4339458/]
- 2. Enhanced unbiased sampling of protein dynamics using ... [https://www.nature.com/articles/s41598-017-12874-7]
- 3. Convert Femtosecond to Millisecond [https://www.unitconverters.net/time/femtosecond-to-millisecond.htm]
- 4. A New Equation to Regulate Boost Energy in Accelerated ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC3254191/]
- 5. Exploring Conformational Landscapes of Two-dimensional ... [https://www.sciencedirect.com/science/article/abs/pii/S2352431625001336]
- 6. Path-sampling strategies for simulating rare events in ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC5420491/]
- 7. CVHD: Bias for Rare Events — Tutorials 2025.1 documentation [https://www.scm.com/doc/Tutorials/MolecularDynamicsAndMonteCarlo/CVHD.html]
- 8. Revealing the Atomistic Mechanism of Rare Events ... [https://arxiv.org/html/2511.15514v1]
- 9. Identifying and Overcoming the Sampling Challenges in ... [https://pubmed.ncbi.nlm.nih.gov/37450482/]
- 10. Improved Sampling Strategies for Protein Model ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7946773/]
- 11. Frontiers | Use of AI-methods over MD in the simulations of... sampling [https://www.frontiersin.org/journals/molecular-biosciences/articles/10.3389/fmolb.2025.1542267/full]
- 12. Extensive tests and evaluation of the CHARMM36IDPSFF force field... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7198049/]
- 13. A Quick Guide to Organizing Computational Biology Projects [https://pmc.ncbi.nlm.nih.gov/articles/PMC2709440/]
- 14. Sampling of the conformational landscape of small proteins ... [https://www.nature.com/articles/s41598-020-75239-7]
- 15. Sampling of Protein Conformational Space Using Hybrid ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8855042/]
- 16. From complex data to clear insights: visualizing molecular ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11043564/]
- 17. VMD - Visual Molecular Dynamics [https://www.ks.uiuc.edu/Research/vmd/?]
- 18. Enhanced sampling of protein conformational changes via ... [https://www.nature.com/articles/s41467-025-55983-y]
- 19. Improved Sampling of Adaptive Path Collective Variables by ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10753802/]
- 20. -CSDN博客 蛋 白 质 分 子 动 力 学 模 拟 [https://blog.csdn.net/hdpai2018/article/details/119388418]
- 21. patents.google.com/patent/CN102779239A/zh [https://patents.google.com/patent/CN102779239A/zh]
- 22. Deep generative modeling of temperature-dependent ... [https://www.nature.com/articles/s42004-025-01737-2]
- 23. An introduction to Flow Matching [https://mlg.eng.cam.ac.uk/blog/2024/01/20/flow-matching.html]
- 24. On the Connection Between Diffusion Models and ... [https://arxiv.org/html/2504.03187v1]
- 25. Diffusion models in bioinformatics and computational biology [https://pmc.ncbi.nlm.nih.gov/articles/PMC10994218/]
- 26. MIT scientists debut a generative AI model that could ... [https://news.mit.edu/2025/mit-scientists-debut-generative-ai-model-that-could-create-molecules-addressing-hard-to-treat-diseases-1125]
- 27. [2312.13868] Data-driven path collective variables [https://arxiv.org/abs/2312.13868]
- 28. Best practices for machine-learned force fields [https://www.vasp.at/wiki/index.php/Best_practices_for_machine-learned_force_fields]
- 29. Challenges in protein folding simulations: Timescale, ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC3032381/]
- 30. Advanced Sampling Methods for Multiscale Simulation of ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8533332/]
- 31. A Practical Guide to All-Atom and Coarse-Grained ... [https://www.mdpi.com/1422-0067/25/12/6698]
- 32. Use of AI-methods over MD simulations in the sampling of ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12011600/]
- 33. Determining accurate conformational ensembles of ... [https://www.nature.com/articles/s41467-025-64098-3]
- 34. Troubleshooting Guide to Expressing Intrinsically ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC6345686/]
- 35. Modeling and Simulation Software [https://www.rcsb.org/docs/additional-resources/modeling-and-simulation-software]
- 36. QwikMD - Integrative Molecular Dynamics Tookit for Novices ... [http://www.ks.uiuc.edu/Research/qwikmd/]
- 37. 10 Common Molecular Dynamics Mistakes New ... [https://insilicosci.com/common-molecular-dynamics-mistakes/]
- 38. Editorial: Advanced Sampling and Modeling in Molecular ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8633950/]
- 39. Enhanced sampling techniques in molecular dynamics ... [https://www.sciencedirect.com/science/article/abs/pii/S0304416514003559]
- 40. Best Practices for Quantification of Uncertainty and Sampling ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC6286151/]
- 41. Validation of Molecular Dynamics Simulations for ... [https://www.mdpi.com/1420-3049/22/10/1716]
- 42. Uncertainty quantification in molecular dynamics [https://ui.adsabs.harvard.edu/abs/2012PhDT.......175R/abstract]
- 43. What is uncertainty quantification in machine learning? [https://www.ibm.com/think/topics/uncertainty-quantification]
- 44. Ten quick tips to perform meaningful and reproducible ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12064015/]
- 45. A practical guide to large-scale docking [https://www.nature.com/articles/s41596-021-00597-z]
- 46. Avoiding Common Mistakes When Setting Up a Production ... [https://blog.samson-connect.net/avoiding-common-mistakes-when-setting-up-a-production-md-simulation]
- 47. M01 tool: an automated, comprehensive computational ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11995494/]
- 48. Pipeline Optimization Techniques - by Deepak Jayabalan [https://medium.com/@deepak.jayabalan/pipeline-optimization-techniques-eb11b48ce941]
- 49. Automating MD simulations for Proteins using Large ... [https://arxiv.org/html/2507.07887v1]
- 50. Troubleshooting Simulations [https://docs.openfree.energy/en/latest/guide/troubleshooting.html]
- 51. Extending machine learning model for implicit solvation to ... [https://arxiv.org/html/2510.20103v1]
- 52. Exploring Meta's Open Molecules 2025 (OMol25) & Universal ... [https://www.rowansci.com/blog/exploring-open-molecules-2025]
- 53. Use of AI-methods over MD simulations in the sampling ... [https://pubmed.ncbi.nlm.nih.gov/40264953/]
- 54. ABCG2: A Milestone Charge Model for Accurate Solvation ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11948320/]
- 55. Path-sampling strategies for simulating rare events in ... [https://www.sciencedirect.com/science/article/abs/pii/S0959440X16302068]
- 56. Sampling rare conformational transitions with a quantum ... [https://www.nature.com/articles/s41598-022-20032-x]
- 57. PathGennie: Rapid Generation of Rare Event Pathways via ... [https://chemrxiv.org/engage/chemrxiv/article-details/690447f0ef936fb4a2641728]
- 58. Moltiverse: Molecular Conformer Generation Using ... [https://pubmed.ncbi.nlm.nih.gov/40421608/]
- 59. Moltiverse: Molecular Conformer Generation Using ... [https://chemrxiv.org/engage/chemrxiv/article-details/67621d996dde43c908780be8]
- 60. High-Quality Conformer Generation with CONFORGE [https://pmc.ncbi.nlm.nih.gov/articles/PMC10498443/]
- 61. Bayesian optimization for conformer generation [https://jcheminf.biomedcentral.com/articles/10.1186/s13321-019-0354-7]
- 62. Moltiverse: Molecular Conformer Generation Using ... [https://chemrxiv.org/engage/chemrxiv/article-details/67269d34f9980725cfe65a26]
- 63. Generating Molecular Conformer Fields [https://arxiv.org/html/2311.17932v2]
- 64. A Standardized Benchmark for Machine-Learned ... [https://arxiv.org/html/2510.17187v1]
- 65. Frequently Asked Questions - GENESIS [http://mdgenesis.org/docs/FAQ/]
- 66. Molecular dynamics studies of the structural and transport ... [https://www.sciencedirect.com/science/article/abs/pii/S0927025625004938]
- 67. AI-based Methods for Simulating, Sampling, and Predicting ... [https://arxiv.org/html/2509.17224v1]
- 68. [Literature Review] AI-based Methods for Simulating ... [https://www.themoonlight.io/en/review/ai-based-methods-for-simulating-sampling-and-predicting-protein-ensembles]
- 69. drMD: Molecular Dynamics for Experimentalists [https://www.sciencedirect.com/science/article/pii/S0022283624005485]
- 70. Improving the Physical Realism and Structural Accuracy of ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC3218324/]
- 71. The Fastest Simulation of Protein Folding Based on ... [https://www.fortunejournals.com/articles/the-fastest-simulation-of-protein-folding-based-on-torsion-angles.html]
- 72. A Cost–Benefit Analysis Simulation for the Digitalisation of ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10141111/]